

Cloudera has been working on Apache Ozone, an open-source project to develop a highly scalable, highly available, strongly consistent distributed object store. Ozone is able to scale to billions of objects and hundreds petabytes of data. It enables cloud-native applications to store and process mass amounts of data in a hybrid multi-cloud environment and on premises. These could be traditional analytics applications like Spark, Impala, or Hive, or custom applications that access a cloud object store natively.
Ozone is also highly available—the Ozone metadata is replicated by Apache Ratis, an implementation of the Raft consensus algorithm for high-performance replication. Since Ozone supports both Hadoop FileSystem interface and Amazon S3 interface, frameworks like Apache Spark, YARN, Hive, and Impala can automatically use Ozone to store data.
Current releases of Ozone in the Cloudera Data Platform (CDP) are using the write pipeline V1. A future release of Cloudera Data Platform will benefit from a new write pipeline V2 implementation that will enable faster and more predictable performance. Write pipeline V2 increases the performance by providing better network topology awareness and removing the performance bottlenecks in V1. The V2 implementation also avoids unnecessary buffer copying and has a better utilization of the CPUs and the disks in each datanode.
In this blog post, we describe the process and results of replacing the current write pipeline (V1) with the new pipeline (V2). This blog post is written with a technical audience in mind who may be interested in the design and implementation details of how writes work in a highly scalable distributed object store.
When a client writes an object to Ozone, the object is automatically replicated to three datanodes. In Ozone, containers are the fundamental unit of replication. A container stores data blocks that belong to multiple objects and the size of the container is 5GB by default. In the Ozone terminology, a client writes object data to a pipeline. A pipeline is associated with an open container behind the scene. The objects written by the clients are stored as blocks inside an open container. In the current Pipeline V1 implementation, an open container replicates data to its associated datanodes using the Raft consensus algorithm implemented by Apache Ratis. In this article, we discuss the Pipeline V2 implementation and the major performance improvement demonstrated with the benchmark results.
Ozone Write Pipeline V1 with Ratis Async
The Ozone Write Pipeline V1 is implemented with the Ratis Async API. The following are the steps for writing to a pipeline with three datanodes:
V1.1. A client gets an open container from SCM (Storage Container Manager). Open containers are precreated. An open container may serve multiple write-block operations from different clients. 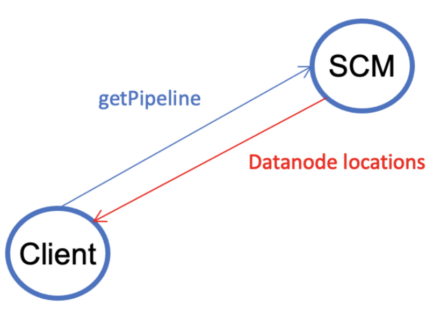
V1.2. The client must write to the Raft leader. The leader will then forward the data to its two Raft followers. In the Raft consensus algorithm, a leader is elected among the servers in a Raft group. The other servers become its followers. 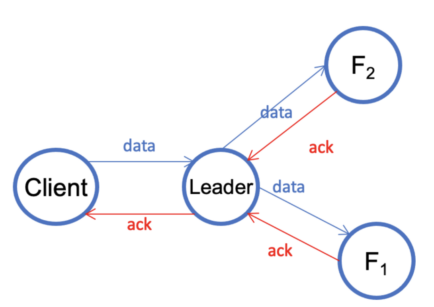
V1.3. The client sends a putBlock request to commit the block and then waits until the data is replicated to all three datanodes by sending a Ratis watch request. When the client has received a successful reply from the Ratis Async API, the request may only be replicated to a majority of the datanodes. This is the guarantee provided by the Raft consensus algorithm. The client sends a watch request in order to wait until all the data is replicated to all of the datanodes. 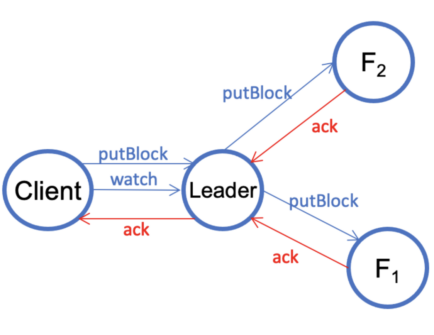
V1.4. The client sends a commit-key request to the Ozone Manager (OM). 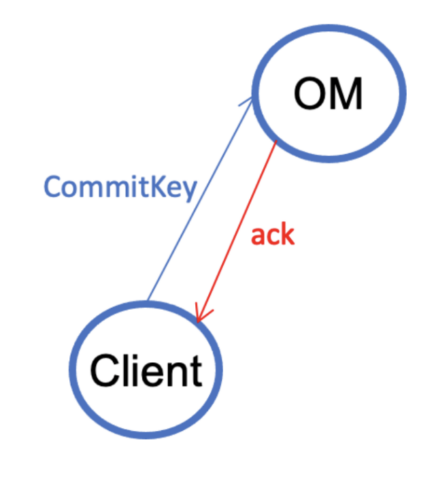
The Ozone Write Pipeline V1 has a lot of advantages compared to the HDFS Write Pipeline (a.k.a. Data Transfer Protocol). A review of the HDFS Write Pipeline can be found in the Appendix.
A.1. The pipeline transactions are distributed but not dependent on a central agent because each pipeline in Ozone has its own Raft log for storing its journal. In HDFS, the pipeline transactions are stored in a central agent, the HDFS Namenode. As a result, the Namenode is a limitation on the number of concurrent pipelines in HDFS.
A.2. An open container in Ozone may serve multiple write-block operations from different clients, but the HDFS pipeline serves only a single write. When writing small blocks, Ozone V1 is much more efficient since it does not have to open and close a new pipeline for each block.
A.3. The Ozone pipeline is implemented by an asynchronous event-driven model so that it does not require any dedicated threads per pipeline. A single thread pool in a datanode can serve all the pipelines. The HDFS Write Pipeline was implemented using blocking-IO. It requires two or four dedicated threads per pipeline in a datanode, depending on the datanode position in the pipeline. The last datanode in the pipeline requires two dedicated threads, and all the remaining datanodes require four dedicated threads. As a consequence, the number of concurrent pipelines in a datanode is limited by the number of threads in a datanode.
We have identified the following areas of improvement for Ozone V1 Pipeline.
1.1. The leader datanode is a performance bottleneck since the leader has more work to do than the followers. It gets more traffic since it receives data from the client and then forwards the data to the followers as shown in Fig. V1.2. Also, it needs more memory to cache data for retries. A work-around is to create three pipelines at the same time for three datanodes, each datanode a leader of a pipeline. However, this work-around requires more resources to manage the pipelines.
1.2. The network topology awareness is limited in Ozone V1. It is because clients have to write to the leader but not the followers in a pipeline. In some worse cases, the data may unnecessarily travel back and forth between racks. Fig. I.2 below depicts a degenerated case where the followers are closer to the client but the leader is not. The SCM will try to avoid such cases but it is not always possible since the pipelines are pre-created and the choices for allocating a pipeline to a client are limited.
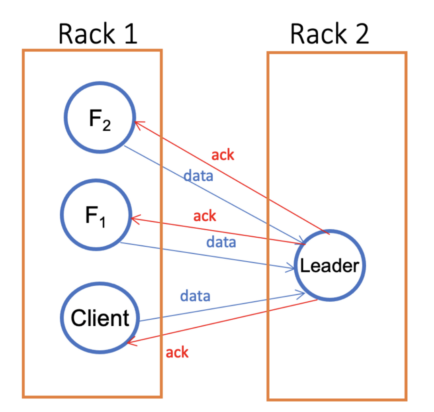
Fig. I.2. Data may unnecessarily travel fore and back between racks in V1
1.3. The concurrent client requests are ordered even if the requests are unrelated, since the transactions are ordered in the Raft consensus algorithm. When there is a slow disk in a datanode, the requests writing to fast disks still have to wait for the requests writing to the slow disk due to the ordering.
1.4. The Pipeline V1 uses Ratis Async API, which is implemented with gRPC over Netty. Unfortunately, the gRPC library allocates and copies buffers internally. It unnecessarily uses CPU and memory for the buffer copying. As a result, the chunk size has to be large, although the chunk size is configurable. The reason is that a write-chunk request generates a Raft transaction. If the chunk size is small, then there will be a lot of transactions in the Raft log. Since the gRPC library allocates and copies buffers internally, a large chunk size increases the memory usage.
Let us finally remark that Ozone Write Pipeline V1 is implemented with the Ratis data and metadata separation feature, which allows the data to be separated from the metadata before writing to the Raft log. This is because the Raft consensus algorithm is not suitable for data intensive applications since it has a replicated state machine architecture [1]. It manages a replicated log, the Raft log, containing state machine commands from clients. The state machines process identical sequences of commands from the logs, so they produce the same outputs. For data intensive applications like Ozone, the state machine commands contain the data and metadata from clients, where the data size is large and the metadata size is small. A data intensive application usually stores both the data and the metadata in its own storage. As a result, a large amount of data is written twice—once to the Raft log and once to the application’s storage. This results in write amplification. With the data and metadata separation in the V1 pipeline, only the Ozone metadata is written to the Raft log. The data written to the disk is managed by Ozone application via its state machine when it gets a Ratis callback to apply the state machine transaction. This tends well to further optimizations for buffering and caching.
Ozone Write Pipeline V2 with Ratis Streaming
The challenges discussed in the previous section have motivated us to explore a more efficient mechanism to implement the write pipeline [2]. We borrow the idea of chain replication from the HDFS Write Pipeline, which allows clients writing to the closest datanode DN1 in the pipeline. Then, DN1 forwards the data to the second datanode DN2, which further forwards the data to the third datanode DN3.
We introduced a new Ratis feature Ratis Streaming [3], which allows clients to write to any datanodes in the Raft group (which is the pipeline in Ozone). Similar to HDFS, the first datanode may forward the data to the second datanode, which may further forward the data to the third datanode. Indeed, clients may specify a routing table so that the data is forwarded accordingly.
Below are the steps in Ozone Write Pipeline V2:
V2.1. A client gets an open container from Storage Container Manager (SCM). This step is exactly the same as V1.1, the first step in V1. 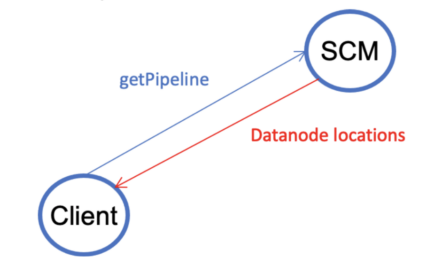
V2.2. The client uses the topology information provided by SCM to create a stream. Then the client writes to the closest datanode. Note that it does not matter if the closest datanode is the leader or a follower. The closest datanode forwards the data to the second datanode, which further forwards the data to the third datanode. Once the client has completed writing data, it closes the stream (but not the pipeline). Note also that a stream, which is similar to the pipeline in HDFS, is for writing a single block.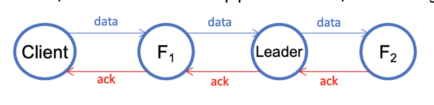
V2.3. This step is exactly the same as V1.3—the client sends a putBlock request to commit the block and then waits until the data is replicated to all three datanodes by sending a Watch request. 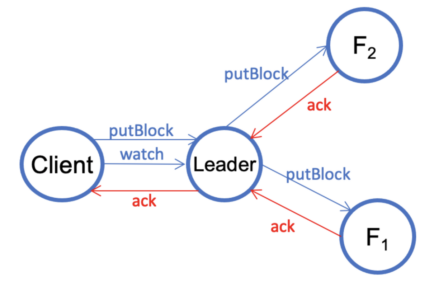
V2.4. This step is again the same as V1.4—the client sends a commit-key request to OM. 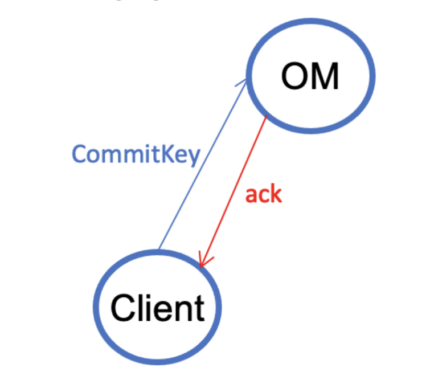
Note that Pipeline V2 has the same advantages A.1, A.2, and A.3 as Pipeline V1 but optimizes the write path further as listed below:
- Pros1. The leader is no longer the performance bottleneck since it does not get more traffic.
- Pros2. Pipeline V2 has a better network topology awareness than Pipeline V1 since clients are able to send data to any datanode in Pipeline V2. In Pipeline V1, clients must send data to the leader. As an example, the V1 pipeline in Fig I.2 may become the following V2 pipeline so that the data does not have to travel across racks.
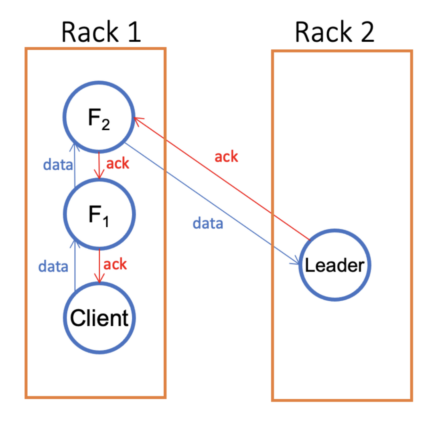
- Pros3. When there are multiple concurrent streams in a datanode, the streams are unrelated. Thus, a slow disk in a datanode only slows down the streams writing to that disk but not the stream writing to the other disks.
- Pros4. Pipeline V2 is implemented using Netty directly so that it can take the advantage of Netty zero buffer copy. Therefore, Pipeline V2 does not have the gRPC buffer problem observed in Pipeline V1.
There are cons of Pipeline V2. We describe the cons below with justifications:
- Cons1. When the data size is small, say less than 4MB, Pipeline V1 is more efficient then Pipeline V2, which still has to create a stream before writing data and close it afterward. Pipeline V1 just has to send a single request in this case. Therefore, the client should use Pipeline V1 when the data size is smaller than the chunk size. Otherwise, use Pipeline V2.
- Cons2. Ozone SCM chooses only among the pre-created pipelines while the HDFS namenode may choose any three datanodes to form a pipeline. Arguably, HDFS pays a price for the flexibility in network topology awareness—HDFS may randomly choose any three datanodes to store a block. However, when there are random failures of any three datanodes, with HDFS the data loss probability is higher. In contrast, it is unlikely to have data loss when there are random failures of any three datanodes since it is unlikely that these three datanodes belong to the same pipeline due to the advanced replication strategies in Ozone. For a more detailed discussion, see [4].
Benchmarks
The benchmark cluster has seven machines as below:
- One machine for running both SCM and OM
- Three machines for running datanodes
- Three machines for running clients
Each machine has 512GB memory and a 7.68TB ssd. We thank Intel for generously providing the hardware to run the benchmarks. The benchmark program is available at [5]. Note that the benchmark program also verifies data integrity. We have the following results:
| # files x size | V1 Async (MB/s) | V2 Streaming (MB/s) | V2 / V1 (%) |
| 100 x 128MB | 343.60 | 676.51 | 196.89% |
| 200 x 128MB | 511.74 | 967.67 | 189.09% |
| 400 x 128MB | 549.60 | 1091.90 | 198.67% |
| 800 x 128MB | 518.19 | 1371.56 | 264.69% |
Table 1: A single client writing data to a bucket
| V1 Async (MB/s) | V2 Streaming (MB/s) | V2 / V1 (%) | |
| Client 1 | 172.87 | 578.39 | 334.57% |
| Client 2 | 174.16 | 572.79 | 328.88% |
| Client 3 | 174.87 | 545.37 | 311.88% |
| Throughput | 518.57 | 1634.69 | 315.21% |
Table 2: Three clients writing 100 x 128MB data concurrently to a bucket
| V1 Async (MB/s) | V2 Streaming (MB/s) | V2 / V1 (%) | |
| Client 1 | 174.44 | 625.14 | 358.37% |
| Client 2 | 174.56 | 615.14 | 352.39% |
| Client 3 | 174.41 | 608.08 | 348.66% |
| Throughput | 522.97 | 1824.25 | 348.82% |
Table 3: Three clients writing 200 x 128MB data concurrently to a bucket
In Table 1, we have a single client writing data to a bucket. The client wrote 100, 200, 400, or 800 files with 128MB file size. In Table 2 and Table 3, we have three clients writing data concurrently to a bucket. Each client wrote 100 and 200 files with 128MB files size in Table 2 and Table 3, respectively.
We observed that V1 Async consistently has around 500 MBs throughput for all the single-client and multiple-client cases. It is the limitation of the leader since it has to forward data to two followers. In the single-client case, the performance of V2 Streaming can be ~2x of V1 Async. It is because all the datanodes only forward data to at most one datanode. In the multiple-client case, the performance of V2 Streaming can even be ~3x of V1 Async since streaming can use the full power of three datanodes as illustrated in the diagram below. 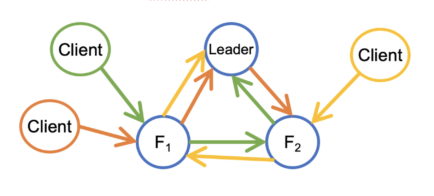
References:
[1] Diego Ongaro and John Ousterhout. In Search of an Understandable Consensus Algorithm (Extended Version). Available at https://raft.github.io/raft.pdf .
[2] HDDS-4454. Ozone Streaming Write Pipeline, https://issues.apache.org/jira/browse/HDDS-4454
[3] RATIS-979. Ratis streaming, https://issues.apache.org/jira/browse/RATIS-979
[4] Losing Data in a Safe Way—Advanced Replication Strategies in Apache Hadoop Ozone, Recorded talk https://www.youtube.com/watch?v=G4cAheDao1Y
[5] The benchmark program, https://github.com/szetszwo/ozone-benchmark
Appendix: HDFS Write Pipeline (a.k.a Data Transfer Protocol)
We give a brief discussion of HDFS Write Pipeline in this section. Below are the steps:
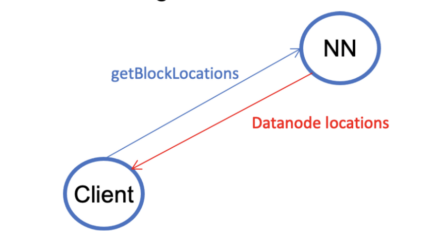
- A client gets datanode locations from the namenode.
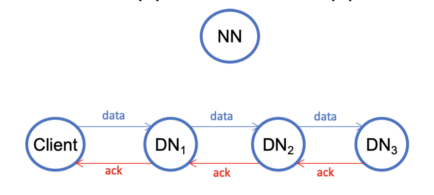
- The client creates a pipeline according to the network distances. It writes the closest datanode DN1. Then DN1 forwards the data to the second datanode DN2, which further forwards the data to the third datanode DN3. Once the client has completed writing data, it closes the pipeline. Note that a pipeline serves only for writing a single block.
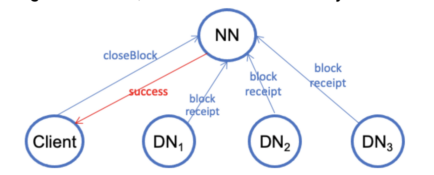
- The client sends a close-block request to the Namenode. At the same time, each datanode in the pipeline sends a block receipt to the Namenode. When the Namenode receives a close-block request from the client, it waits for the minimum number (default is one) of block receipts before replying success to the client. The waiting for the block receipts is for preventing silent data loss when all the datanodes have failed. If the block is under-replicated, the Namenode immediately replicates it. The Namenode stores the block and datanode location information in the memory and persists the block transactions in its file system journal (a.k.a. edit-log). Since the Namenode is a central agent in HDFS, the block transaction system in HDFS is a centralized system.
When a block is being written, it is replicated to three datanodes by the pipeline. In case of a failure, the failed datanode is dropped. The client reconstructs a pipeline with the remaining datanodes and then continues writing. A write pipeline can go down to a single replica in case of multiple failures. There is a replace-datanode-on-failure feature for adding new datanodes on failures in order to provide better data reliability.
The pros are:
- The HDFS Write Pipeline is known to have high throughput.
- A three-replica pipeline can tolerate two failures.
- HDFS also has a very flexible network topology awareness—the Namenode can choose any three datanodes to form a pipeline.
And the cons are:
- The transaction system is centralized in the Namenode.
- A pipeline can serve only a single block so that it is inefficient for writing small blocks.
- In the implementation, it uses blocking-IO. As a consequence, it requires four or two dedicated threads per pipeline in a datanode, depending on the datanode position in the pipeline. The last datanode in the pipeline requires two dedicated threads and all the remaining datanodes requires four dedicated threads.
- Also in the implementation, it has four or more buffer copyings in the datanode.
Conclusion
This blog has described the design and implementation details of Ozone Write Pipeline V1 and the upcoming Ozone Write Pipeline V2. The benchmark results show that V2 has significantly improved the write performance of V1 when writing large objects. There are roughly double and triple performance improvements when writing with a single client and multiple clients, respectively.
If you are interested in learning more about how to use Apache Ozone to power data science, this is a great article. If you want to know more about the new Replication Manager capabilities to cover Apache Ozone object storage, see this blog post. If you like to reduce your IT cloud spend, please read this article.
Editor's Choice

