

The previous decade has seen explosive growth in the integration of data and data-driven insight into a company’s ability to operate effectively, yielding an ever-growing competitive advantage to those that do it well. Our customers have become accustomed to the speed of decision making that comes from that insight. Data is integral for both long-term strategy and day-to-day, or even minute-to-minute operation.
Everyday, we see the Cloudera Data Platform (CDP) becoming that business-critical analytics platform that customers must have running in an available, reliable, and resilient way. Data platforms are no longer skunkworks projects or science experiments. Customers now expect enterprise behavior in their application stacks, whatever that application does. As customers import their mainframe and legacy data warehouse workloads, there is an expectation on the platform that it can meet, if not exceed, the resilience of the prior system and its associated dependencies.
Many customers migrated to the CDP product line since our original release, whether that was in CDP Private Cloud, CDP Public Cloud, or a hybrid combination of the two. We now see customers taking advantage of its new capabilities and the value it brings to their business transformation, and asking “What’s next on my CDP journey?”
Why disaster recovery?
Disaster recovery and business-continuity planning is primarily focused on managing and reducing risk. Customers, especially those in regulated industries with strict data protection and compliance requirements, routinely ask a straightforward question of our technical strategy experts: what should I do if a catastrophe hits my business and threatens to take out my data platform? The simple answer: the customer journey is evolving beyond single data clusters, single clouds, and simple infrastructures into robust, fault-tolerant architectures that can survive a failure event and keep the customer running. The goal is to minimize the impact to a customer’s data-driven decision making in the time of an operational crisis. To do that, we need to build standards for CDP implementation that account for failure, mitigate it, and are validated by market adoption.
We derive these designs from real-world implementations with some of our most leading-edge customers, generalize these learnings into repeatable patterns so they’re applicable across customer size and industry, and evangelize those patterns to improve awareness and supportability.
The CDP Disaster Recovery Reference Architecture
Today we announce the official release of the CDP Disaster Recovery Reference Architecture (DRRA). The DRRA focuses on describing how to think about reliability, resiliency, and recovery for the Cloudera Data Platform, and is a living document describing our collected learning across the platform and across customers.
This initial release focuses on common industry definitions as they apply to the product line, industry standards that we believe customers should align to when thinking about disaster recovery and business continuity planning for data platforms, and an initial set of guidelines and disaster scenarios to think about when implementing a robust data platform. Additionally, we discuss the current state of disaster recovery readiness for various components and specific resilience strategies for each.
The CDP Disaster Recovery Reference Architecture is available in our public documentation within the CDP Reference Architectures microsite.
The importance of terminology and standards
As we worked through disaster recovery designs and strategies with customers across industry verticals and organization sizes, we discovered that everyone uses terminology in different ways. It became a challenge to convey ideas consistently and repeatably. This was especially important with disaster recovery because of the nuance and impact of describing it incorrectly. At best, it led to confusion. At worst, it could have given customers a false sense of security around their catastrophe preparedness.
Within Cloudera, we have begun to align behind two industry standards covering business continuity operations. The first, ISO 27031:2011, helps describe the process and procedures involved in incident response. This includes the Plan, Do, Check, and Act life cycle that help build an incident-response process. The second, NIST 800-34, provides general guidelines for contingency planning for United States federal organizations. While these are not highly technical in nature, they do provide the necessary structural and process framework for successful continuity planning.
It’s essential to understand the difference between terms like Recovery Point Objective (RPO) and Recovery Time Objective (RTO), or the functional impact of point-in-time recovery (Tier 4) and two-site commit transaction integrity (Tier 5) in the Seven Tiers of Disaster Recovery model.
What next?
With our hybrid model, bursting to the cloud for periods of very heavy usage can also be particularly cost effective for disaster recovery in the event of a primary failure. Standby systems can be designed to meet storage requirements during typical periods with burstable compute for failover scenarios using new features such as Data Lake Scaling.
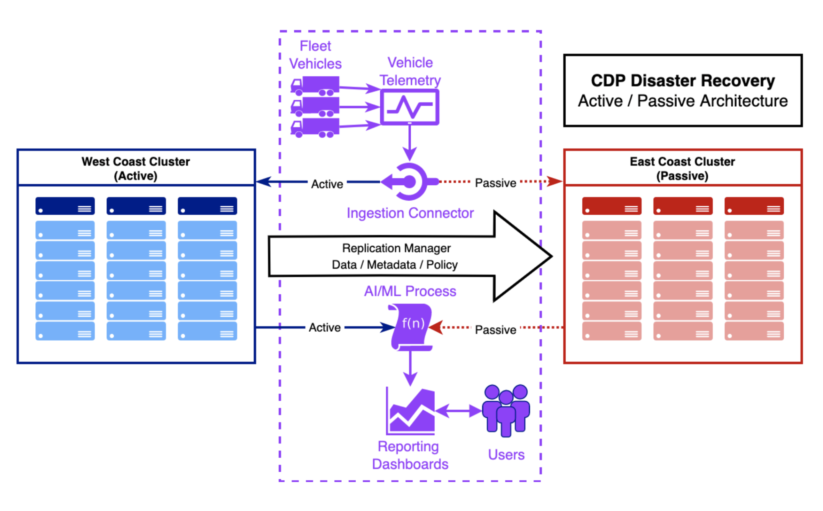
Cloudera continues to improve upon both product and process to make disaster recovery easier to implement. In future updates of the reference architecture, we will describe example implementation patterns focused around particular use cases, such as implementing geographically-separated clusters for Operational Database or Data Warehouse use cases. For example, we are integrating architecture diagrams for active/passive, geographically dispersed disaster recovery cluster pairs like the following diagram, showing a common application zone and for data ingestion and analytics, and how replication moves through the system. In this example, we have a fleet telemetry use case that is moving vehicle IoT data into the system for fleet maintenance analytics that is continually reviewed by a customer’s engineering staff to prevent unexpected mechanical failures. Disaster recovery planning helps ensure that maintenance analytics continues in the event of an unforeseen disruption.
Additionally, we continue to make product improvements including:
- Expanding Replication Manager capabilities to cover Apache Ozone object storage, coming later this year, to better support customer disaster recovery requirements around large-scale and dense data storage.
- Providing multi-availability zone deployment of our core services and certain critical data services such as the Data Lake and Data Hub services in CDP Public Cloud.
- Automating the healing, recovery, scaling, and rebalancing of core data services such as our Operational Database.
{kind=link}
Conclusion
As enterprises continue developing their experience with and critical dependence on data, the more that data becomes a vital component of a business’ ongoing success. Over the last decade, we’ve learned that data and the platforms that provide data-assisted insight need to be available, reliable, and robust. Understanding and planning for disaster recovery is the next step in the process towards a modern data architecture.
If you’d like to learn more, read through the CDP Disaster Recovery Reference Architecture and reach out to our Account and Professional Services teams, who are available to assist. We look forward to speaking with you and helping you make the most of your data.
Additional Resources
Editor's Choice

