

This is part 4 in this blog series. You can read part 1 here and part 2 here, and watch part 3 here.
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies.
The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on Data Collection. The second blog dealt with creating and managing Data Enrichment pipelines. The third video in the series highlighted Reporting and Data Visualization. And this blog will focus on Predictive Analytics. Specifically, we’ll focus on training Machine Learning (ML) models to forecast ECC part production demand across all of its factories.
You may recall from the previous blogs in this series that ECC is leveraging the Cloudera Data Platform (CDP) to cover all the stages of its data life cycle. Here are the key stages:
- Data Collection – streaming data
- Data Enrichment – data engineering
- Reporting – data warehousing & dashboarding
- Serving Data – operational database
- Predictive Analytics – AI & machine learning
- Security & Governance
You may have noticed that we’ve skipped a stage. No worries, we’ll come back to it in the upcoming blog.
The ML Challenge
Before we dive into our ECC parts demand forecasting use case, let’s look at some of the common ML challenges that are shared across industries where modern, data-driven businesses rely on predictive capabilities to drive their strategic decisions – in addition to historical and real-time analytics.
To effectively leverage their predictive capabilities and maximize time-to-value these companies need an ML infrastructure that allows them to quickly move models from data pipelines, to experimentation and into the business. Not only that, businesses also need a way to deploy these models to production in a consistent and repeatable manner, which is why it’s just as important to have ML workflows integrated with a larger data infrastructure. This integration is key in assuring that models evolve with the data – to avoid, for example, model drift.
Thus, successful ML initiatives not only depend on the ability to quickly productionize models but they also depend on seamless access to data to train (and re-train) those models.
Unfortunately, many businesses have yet to reach this level of maturity. According to the 2021 State of Enterprise ML “the time required to deploy a model is increasing, with 64% of all organizations taking a month or longer” and “38% of organizations spend more than 50% of their data scientists’ time on deployment.” One of the big reasons why it takes so long to productionize models is that many data and ML projects are siloed, making it difficult to create end-to-end data pipelines for easy deployment and frequent model updates. These silos not only constrain effective team collaboration, but they also make it difficult to manage and monitor all the projects by central IT (thus contributing to the growth of shadow IT).
The ML Solution
So let’s introduce Cloudera Machine Learning (CML) and discuss how it addresses the aforementioned silo issues.
First, CML is an experience that that has everything a data science team needs to effectively collaborate across a complete ML lifecycle:
- model training and evaluation (e.g. A/B testing)
- model packaging, deployment and serving
- model monitoring
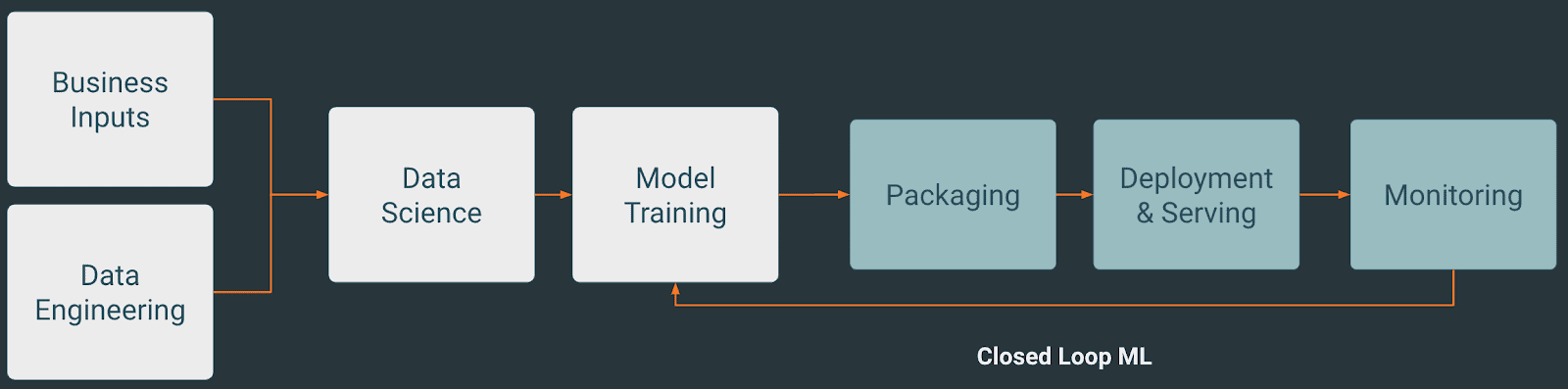
Fig 1. Typical machine learning workflow within Cloudera Machine Learning.
Second, CML seamlessly integrates with the rest of the Cloudera Data Platform to provide end-to-end ML workflows. CML can leverage experiences in the earlier stages, such as data ingestion and data engineering, to fully automate data collection, cleansing and transformation before the prediction (ML) stage begins.
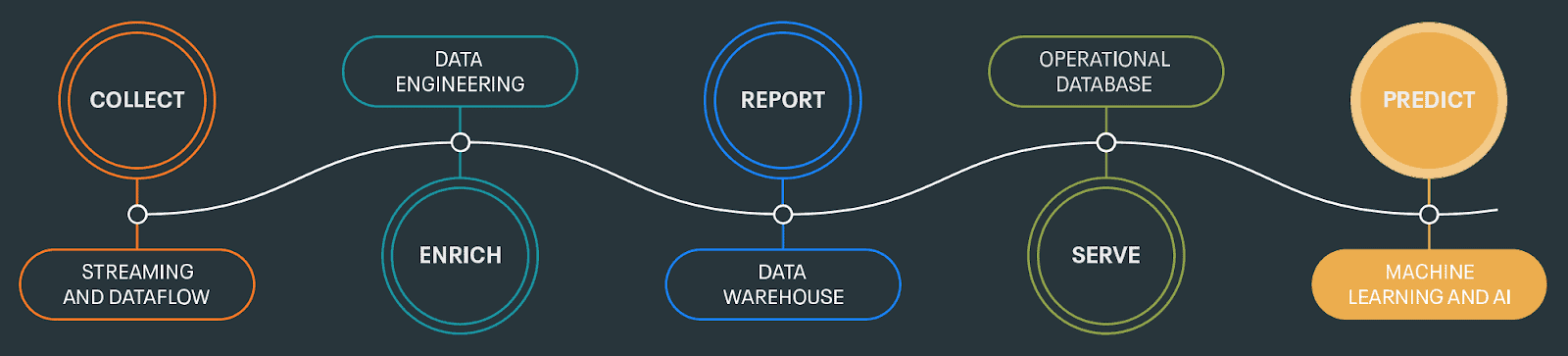
Fig 2. Cloudera Machine Learning seamlessly integrates with other Cloudera experiences, such as DataFlow and Data Engineering, to build automated pipelines that feed ML workflows.
Finally, CML has built-in model security and governance thanks to Cloudera Shared Data Experience (SDX). SDX makes compliance with regulations, such as the General Data Protection Regulation (GDPR), easier for IT administrators, security and data science teams.

Fig 3. Cloudera’s Shared Data Experience (SDX) provides complete security and governance for models and the underlying data.
The ML Use Case
Now that we have the high-level benefits of CML covered, let’s focus on the Electric Car Company use case of parts demand forecasting and start by adding a bit more color.
In our use case, ECC produces parts not only for current vehicles but also for vehicles that need servicing. It does not want to over produce its parts as this ties up cash. And it also doesn’t want to under produce these parts as this will increase wait times for vehicles that need servicing.
Thus, to optimize part production, we’ll use historical part data to train machine learning models to spot trends and seasonality. And then we’ll use these models to make predictions about future parts demand. (The historical part data is especially useful here since we can more accurately predict when or after how many miles these parts are likely to fail given their past performance.)
So here are the three main steps to implement ECC parts demand forecasting in CML.
Step 1. Train ML Models
With enriched data from the earlier stages of the data life cycle, we can easily experiment with and train any number of ML models in CML. Since our goal is to optimize part production we’ve chosen the Gradient Boost Regression model that has shown best metrics (accuracy and AUC) for our particular ECC dataset.
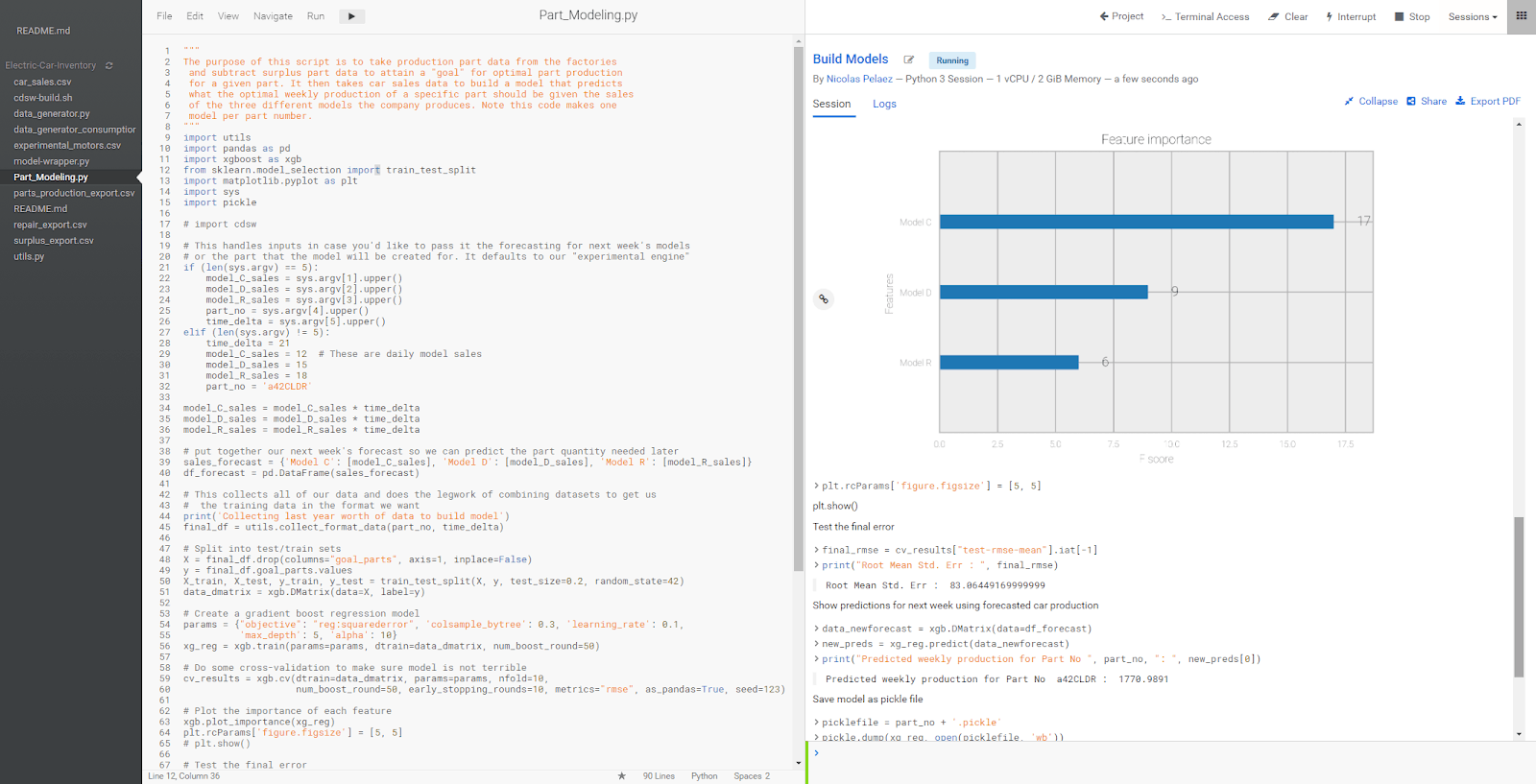
Fig 4. ML code can be easily developed and debugged within a CML workbench session.
Step 2. Schedule ML Jobs
An important step in an ML workflow is making sure that models are updated regularly. This ensures continued, high-level model accuracy and avoids model drift as new data arrives.
Below we can see that we have three jobs scheduled that make parts demand forecasts for the next 21, 14 and seven days. Notice that not only can we monitor the status of those jobs but we can also monitor earlier stages of the data lifecycle, such as data collection and data engineering, and act quickly if failures occur.
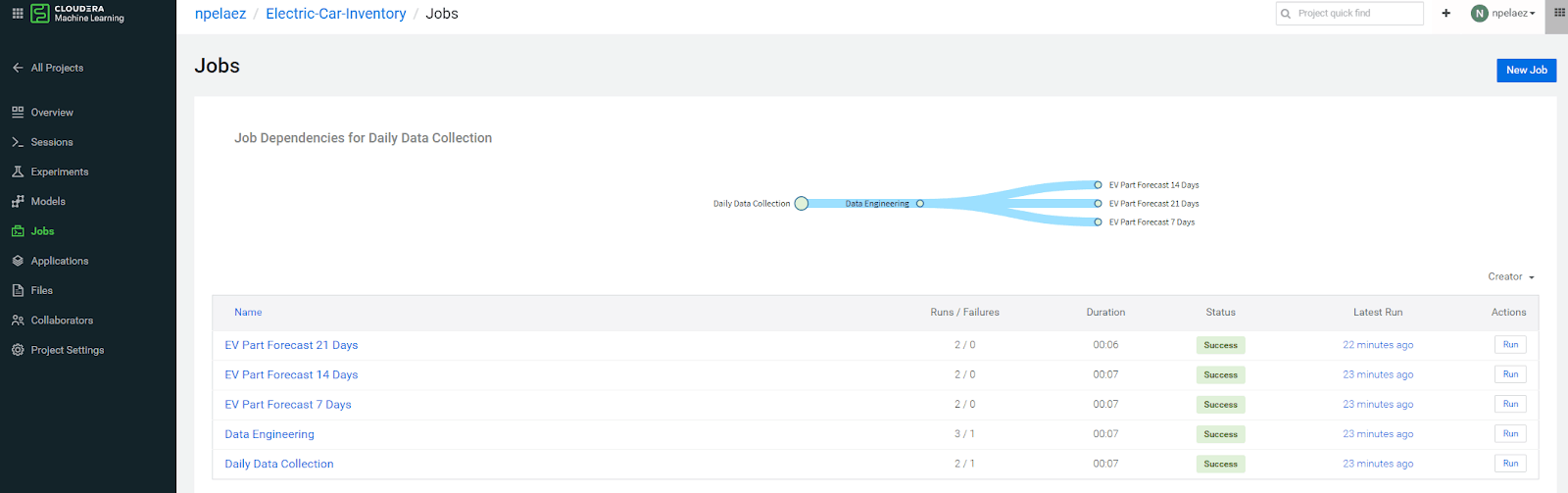
Fig 5. Jobs can be created with dependencies for rebuilding models automatically once new data is collected.
Step 3. Deploy & Serve ML Models
The final step involves pushing models to production – CML makes this process simple with one-click model packaging, deployment and serving. Once deployed, we can easily access the model outputs via API calls and run ECC parts demand forecasts for any of its factories.
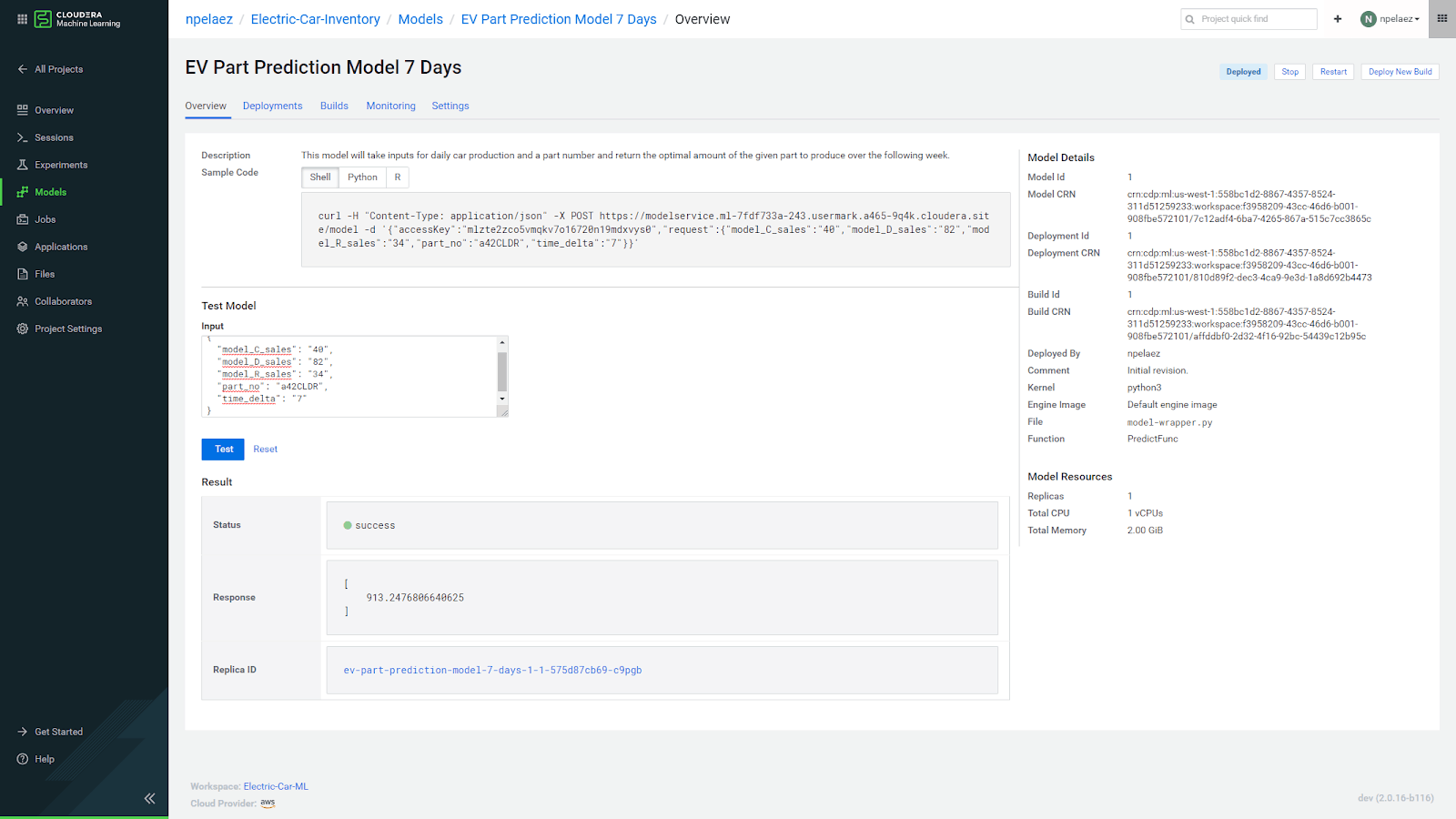
Fig 6. Completed models can be deployed and easily accessed via an API.
Final Words
As you have seen, with CML and integrated end-to-end ML workflows, it will be easy for this Electric Car Company company to build, deploy, serve, monitor and update their ML models. What’s more, by combining the model forecasts with real-time part requests and set part production schedules for new vehicles, ECC will have a complete picture of the current and future parts production demand. With all these insights, ECC will be in a position to better allocate capital resources, improve customer satisfaction with timely part deliveries, improve inventory management and more.
Additional Resources
Follow the links below if you would like to learn more and see this ECC Predictive Analytics use case in action:
- Video – watch a short demo video covering this use case
- Tutorial – follow step-by-step instructions to set up and run this use case
- Meetup – join an interactive meetup live-stream around this use case led by Cloudera experts
Lastly, don’t forget to check out the users page for more great technical content.
Editor's Choice

