

Enterprise data warehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern data warehouse can address them.
Multiplatform
A recent Harvard Business Review study confirmed that data is increasingly being spread across data centres, private clouds and public clouds. They warned data and analytics leaders to “prepare for the complexities of data management” calling out costs, performance and integration as top challenges. Organisations also agree that it is important to adopt multi-cloud and hybrid cloud strategies with 92% of enterprises embracing multi-cloud and 82% indicating that a hybrid cloud strategy is in place. Consequently, organisations are increasingly looking to augment their on-premises data centre and private cloud data warehouses with public cloud solutions. However, legacy data warehouses have limited support for public and private cloud deployment architectures. Managing disparate solutions is operationally inefficient, provides an inconsistent user experience and often leads to increased risk due to a lack of common security, governance and lineage of data.
Efficiency
Legacy data warehouse solutions are often inefficient due to their scale-up architecture, attempting to serve multiple phases of the data lifecycle with a single monolithic architecture, ineffective management and performance tuning tools.
Many data warehouse solutions use highly specialised scale-up hardware appliances consisting of hyper-converged, tightly coupled compute and storage. Additional capacity can be added over time but the unit of increment is typically large, in the order of 25, 50 or 100% of the original capacity. This leads to a constant battle between capacity and efficiency. It either means that data-driven innovation is being restricted or the effective cost of analysis is significantly higher due to unused resources.
Another area impacting efficiency is the types of workloads or tasks being performed on the data warehouse. ETL jobs and staging of data often often require large amounts of resources. In some instances, they can consume up to 90% of the available compute capacity and 70% of the total required storage space respectively. ETL is a data engineering task and should be offloaded onto a scale-out and more cost effective solution.
Similarly, operational data stores take up resources on a data warehouse. They too can be moved to a more cost effective platform. Collectively, moving these workloads off a data warehouse leads to more curated, higher-value workloads and ultimately greater efficiency.
Flexibility
Legacy data warehouse solutions often lack granular control over resources allocated to jobs and tasks and the ability to support multiple versions of tools and engines.
Legacy data warehouses require all users, groups and workloads to use the same versions of query engines and tools. This interdependency complicates the upgrade process and often stifles innovation. Conversely, modern data warehouses accommodate multiple versions and environments that support both innovation (fast interaction with the latest versions) and operational stability with tried and tested versions.
“Noisy neighbour” scenarios where two or more jobs of equal priority compete for resources is a common problem. The lack of granular resource level controls is the root cause of this. Modern data warehouse solutions take advantage of cloud design architectures and containerisation to provide consistent performance across public and private clouds.
Price-Performance
Performance, as a proxy for value, is one of the most important considerations for data warehouse platform owners. On-premises legacy data warehouse solutions set a benchmark for performance for over a decade, but that performance comes at a cost. A better measure of value is price-performance.
Earlier this year, GigaOM McKnight Consulting Group published the results of a TPC99 benchmark study comparing the cost of five industry data warehouse solutions. The study included a combination of native cloud solutions and third-party PaaS solutions. The chart below summarises the price-performance results. The findings revealed that the price-performance of the most expensive solution was over five times that of the best performer.
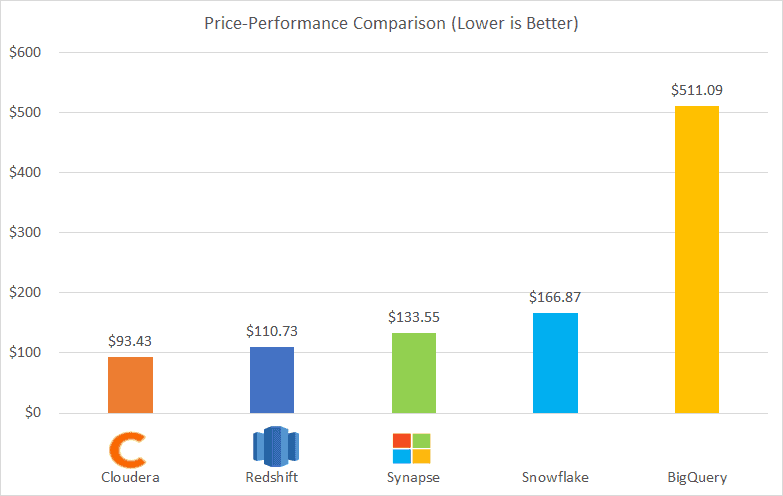
Source: https://gigaom.com/report/cloud-data-warehouse-performance-testing-cloudera/
Data Types & Access Patterns
A modern data warehouse needs to support a combination of different data types, data model architectures, real-time & batch analytics and a variety of data access patterns.
Legacy data warehouse platforms typically accommodate a subset of these data types and access patterns and thus need to be augmented with third-party products and services. For example, many data warehouse platforms do not have efficient storage and query engines to analyse time-series data as this capability frequently sits in an adjacent dedicated platform outside of the data warehouse.
Data warehouses also need to accommodate interactively working with data, including the ability to update records instead of simply reading and performing analytics on them. This has historically led to infrequent updates of data, often significantly after the update event has occurred. This can reduce accuracy, extend the time to insight and complicate platform operations.
Scalability
Historical records show that the amount of data we have created each year has increased exponentially for the last two decades. Current predictions suggest this trend will increase. And IDC expects that by 2025, the global datasphere will grow to 175 zetabytes, and nearly 30% of the data will be generated in real-time. For example, consider the rapidly growing autonomous vehicle market. It is estimated that a single vehicle can generate between five and twenty terabytes of data each day.
Modern data warehouse solutions increasingly need to analyse multi-petabyte data sets as well as a rapidly growing number of users and use cases. This is increasingly becoming tens of petabytes and for some organisations hundreds of petabytes of data. Most of today’s data warehouse solutions hit scalability limits at the low petabytes scale.
This has a number of implications. Limits to the size of data sets that can be processed reduces the accuracy of analysis. This is either due to the window of analysis being smaller or the granularity of data within a window being coarser. Even if a data warehouse solution can process a single data set at the required level of granularity, scalability limitations restrict the number of jobs that can be run in parallel. Ease of deployment could impact the time to insight by up to 88% and affect subsequent data driven decisions.
Data Exploration
There is a growing need to provide users with flexible options to explore data and share insights; this includes both statistical and visual exploration of data, interactively running queries, long running reports and collaborative notebooks.
Exploratory Data Analysis (EDA) typically consists of both statistical and visual exploration of data. While statistical analysis may provide the foundation, visualising data often provides the greatest insight to a wider audience, in a shorter period of time. A well chosen plot or graph can communicate complex relationships or highlight areas to explore further in seconds.
Despite the importance of data visualisation, most data warehouse solutions require additional third-party tools to visualise data. This requires integration effort and ongoing subscription and management costs.
Most data warehouse query engines are optimised for efficient batch operations. This is an obstacle for users who need to iteratively explore data. Extended query times resulting from jobs being queued and waiting to be processed is inefficient and can frustrate analysts.
Notebooks are a great way to collaborate during the data exploration phase, not to mention their broader use in the context of Machine Learning (ML). Formerly tools used just by data scientists, they are increasingly being used by data analysts.
Conclusion
Faced with the limits of existing information management infrastructures, companies will increasingly look towards modernizing their data warehouses to keep up with the exponential growth in data volumes, diversity, and velocity. Check out this Nucleus Research report that highlights how Cloudera’s customers have experienced a wide range of benefits with Cloudera Data Platform and Cloudera Data Warehouse, including an 88% reduction in script runtime, a 75% reduction in time spent coding, and a 47% reduction in the development lifecycle.
Join us on the upcoming webinar “Migrate your Data Warehouse to Cloudera” on 20 April 2021 to jumpstart your data warehouse modernization journey.
Editor's Choice

