

This is part 2 in this blog series. You can read part 1, here: Digital Transformation is a Data Journey From Edge to Insight
This blog series follows the manufacturing, operations and sales data for a connected vehicle manufacturer as the data goes through stages and transformations typically experienced in a large manufacturing company on the leading edge of current technology. The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. To accomplish this, ECC is leveraging the Cloudera Data Platform (CDP) to predict events and to have a top-down view of the car’s manufacturing process within its factories located across the globe.
Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment. ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 1):
- Data Collection – data ingestion and monitoring at the edge (whether the edge be industrial sensors or people in a vehicle showroom)
- Data Enrichment – data pipeline processing, aggregation and management to ready the data for further analysis
- Reporting – delivering business insight (sales analysis and forecasting, budgeting as examples)
- Serving – controlling and running essential business operations (dealer operations, production monitoring)
- Predictive Analytics – predictive analytics based upon AI and machine learning (predictive maintenance, demand-based inventory optimization as examples)
- Security & Governance – an integrated set of security, management and governance technologies across the entire data lifecycle
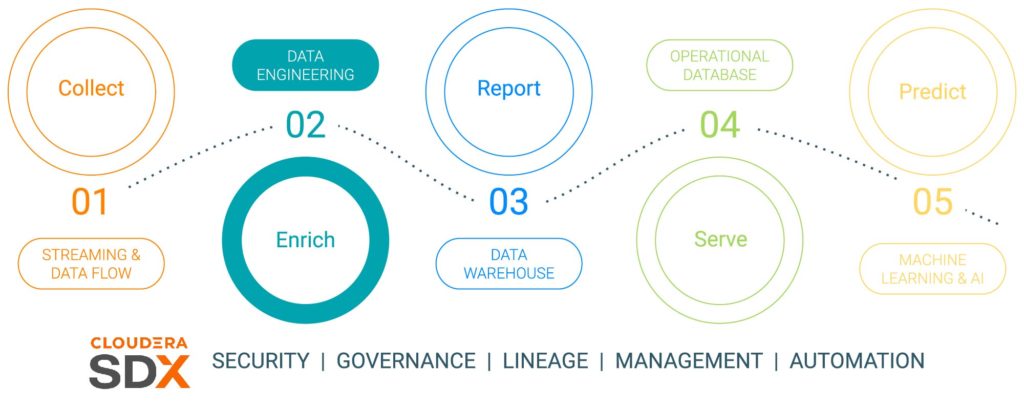
Fig. 1 The enterprise data lifecycle
Data Enrichment Challenge
ECC needs a comprehensive view and robust understanding of all the data related to the manufacturing, the dealer operations, and shipment of their vehicles. They’ll also need to quickly identify issues with the data such as operational sensors spinning off data that might include false temperature spikes caused by unplanned machine stoppages or abrupt start-ups. Data that has no relation to the process when maintenance workers remove a sensor from an acid dip tank while doing routine inspections, for instance, should not be taken into account in the analysis.
Additionally, ECC faces the following data challenges that need to be addressed to successfully move the motor manufacturing through its supply chain. These data challenges include the following:
- Retrieving data in various formats from different sources: Data engineering pipelines require data to be brought in from various sources and in many different formats. Whether data is sourced from sensors sitting on the production line, supporting manufacturing operations, or ERP data controlling the supply chain, it must all be brought together for further analysis.
- Filtering out redundant or irrelevant data: Removing duplicate or invalid data, and assuring accuracy of remaining data, is a key step in preparing the data for further use in advanced predictive analytics.
- Ability to identify inefficient processes: ECC requires the ability to see what data processes are taking up the most time and resources, making it easy to target underperforming parts of the pipeline in order to speed up the overall process.
- Capability to monitor all processes from a single pane: ECC requires a centralized system that allows them to monitor all ongoing data processes as well as an avenue to expand their current infrastructure while maintaining transparency.
Curated, quality datasets are the backbone of any advanced analytics initiative. To achieve this, a data engineering framework must be used to allow the building of all of the piping and plumbing needed to move, manipulate, and manage data of the different vehicle parts in the data lifecycle.
Building a Pipeline Using Cloudera Data Engineering
Before the data is enriched and discussed in the first blog, IT and OT data streams collected from the factory will be cleaned, manipulated, and modified. Factory ID, machine ID, timestamp, part number, and serial number could be captured from a QR-code imprinted on the electric motor. As the motor is assembled into the connected vehicle, data is captured such as model type, VIN, and base vehicle cost.
After the vehicle is sold, the sales information such as customer name, contact information, final sales price, and customer location are recorded separately. This data will be crucial for contacting the customer for any potential recalls or targeted preventative maintenance. Geolocation data is also stored, which will help map customer locations to latitudes and longitudes to better understand where these motors are located after being sold in a vehicle.
ECC will use Cloudera Data Engineering (CDE) to address the above data challenges (see Fig. 2). CDE will then make the data available to Cloudera Data Warehouse (CDW), where it will be made available for advanced analytics and business intelligence reports. The CDE steps are outlined below.
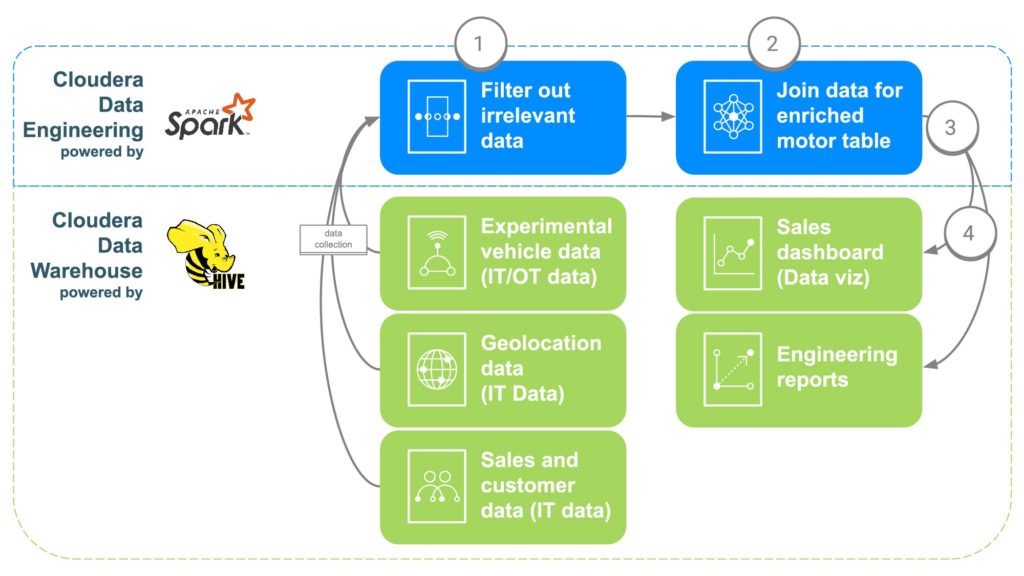
Fig. 2 ECC data enrichment pipeline
STEP 1: Filter and separate the data
The first step in using CDE is to create a PySpark job that brings in the data from these various “raw” sources from step 1. This is an opportunity to filter any irrelevant data such as customers under 16 years old, for example, since that is typically the minimum driving age. Duplicate data and other irrelevant data can also be filtered or separated out.
STEP 2: Combine the data
In order to combine all the data, CDE will correlate common links together. First, the car sales data will be tied into the customer who purchased the car in order to get the customer metadata, such as contact information, age, salary, etc. Geolocation data will then be used to get more precise location information for the customer, which will help in mapping the motors later. Part installation data will be used to identify the serial numbers for each motor that was installed in the customer’s car. Finally, factory data will be aligned to match the motor’s serial number that will identify which factory, machine, and when each specific motor was created.
STEP 3: Send data to Cloudera Data Warehouse
Once all the data is brought together in an enriched table, a simple Apache Spark command will write the data into a new table within Cloudera Data Warehouse. This will make the data accessible to any data scientists that may want to access it to do some additional analysis.
STEP 4: Generate data visualization dashboards and reports
With the data all in one place, reports can now be created that will let employees make better informed decisions and open up capabilities that didn’t exist. Heatmaps can be made to track motor location and correlate any issues with potential geographic locations, such as failure due to extreme cold or heat. This data could also be used to track exactly what customers may be affected if there were an issue at a certain factory over a time range, making it easy to track down customers who may need a recall or some preventive maintenance.
Conclusion
Cloudera Data Engineering enables ECC to build a pipeline that can correlate manufacturing and parts data, customer use type, environmental conditions, sales information, and more in order to improve customer satisfaction and vehicle reliability. ECC achieved its objectives and addressed their challenges by tracking the data related to the manufacturing of its motors and benefitting in the following ways:
- ECC sped time to value by orchestrating and automating data pipelines to deliver curated, quality datasets securely and transparently from various data sources.
- ECC was able to identify relevant data and filter out any redundant and duplicate data.
- ECC was able to achieve data pipeline monitoring from a single pane, while being in a position to be alerted to catch issues early through visual troubleshooting to quickly resolve problems before business was impacted.
Look for the next blog that will delve into Reporting that will show how ECC engineers run ad-hoc queries in CDW against this curated data as well as join the data to other relevant sources inside an enterprise data warehouse. CDW facilitates bringing all of the data together and provides a built-in data visualization tool to go from queried results to dashboards. Stay tuned for the next one!
More Data Collection Resources
To see all this in action, please click on the related links below to learn more data enrichment:
- Video – If you’d like to see and hear how this was built, see video at the link.
- Tutorials – If you’d like to do this at your own pace, see a detailed walkthrough with screenshots and line by line instructions of how to set this up and execute.
- Meetup – If you want to talk directly with experts from Cloudera, please join a virtual meetup to see a live stream presentation. There will be time for direct Q&A at the end.
- Users – To see more technical content specific for users, click on the link.
Editor's Choice

