

Digital transformation is a hot topic for all markets and industries as it’s delivering value with explosive growth rates. Consider that Manufacturing’s Industry Internet of Things (IIOT) was valued at $161b with an impressive 25% growth rate, the Connected Car market will be valued at $225b by 2027 with a 17% growth rate, or that in the first three months of 2020, retailers realized ten years of digital sales penetration in just three months. Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like data warehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data. The missing chapter is not about point solutions or the maturity journey of use cases. The missing chapter is about the data–it’s always about the data–and, most importantly, the journey data weaves from edge to artificial intelligence insight.
This is the first in a six-part blog series that outlines the data journey from edge to AI and the business value data produces along the journey. The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. We have simplified this journey into five discrete steps with a common sixth step speaking to data security and governance. The six steps are:
- Data Collection – data ingestion and monitoring at the edge (whether the edge be industrial sensors or people in a brick and mortar retail store)
- Data Enrichment – data pipeline processing, aggregation & management to ready the data for further refinement
- Reporting – delivering business enterprise insight (sales analysis and forecasting, market research, budgeting as examples)
- Serving – controlling and running essential business operations (ATM transactions, retail checkout, or production monitoring)
- Predictive Analytics – predictive analytics based upon AI and machine learning (Fraud detection, predictive maintenance, demand based inventory optimization as examples)
- Security & Governance – an integrated set of security, management and governance technologies across the entire data lifecycle
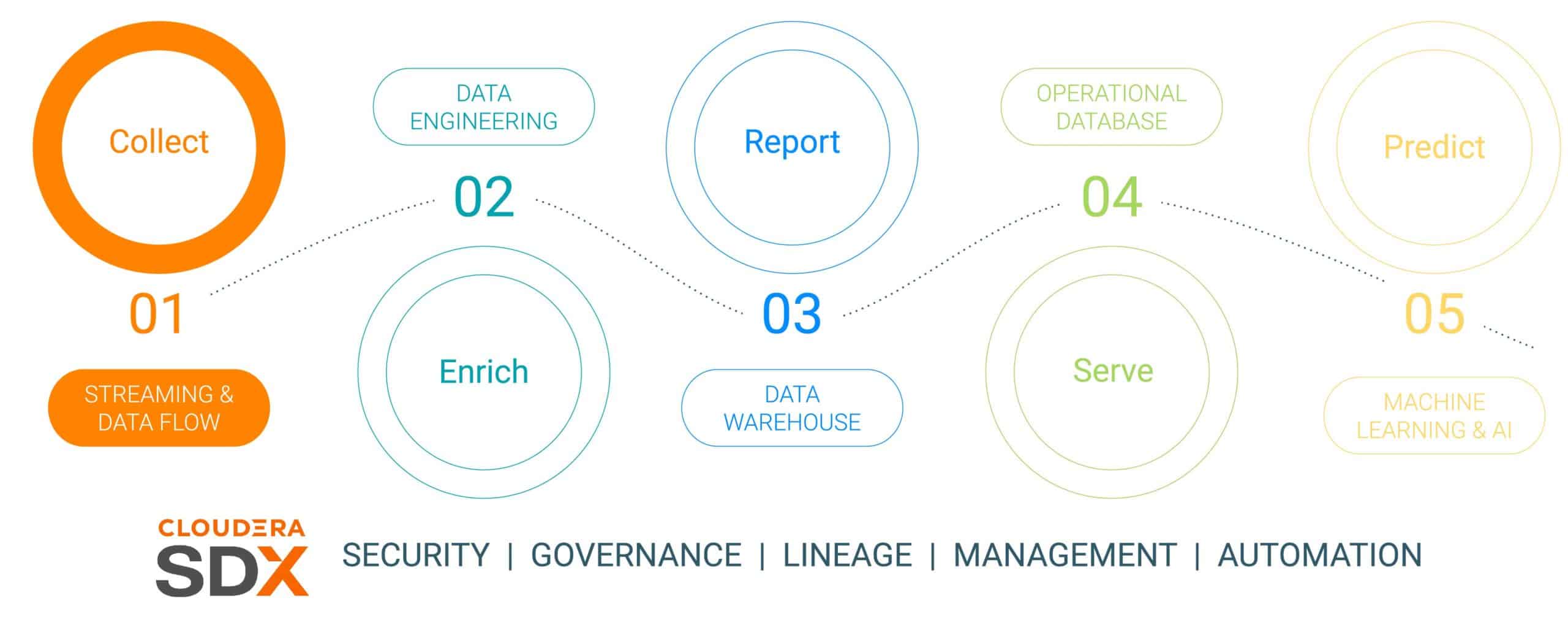
Fig 1: The Enterprise Data Lifecycle
To illustrate the data journey, we have chosen a very relevant and sustainably-minded manufacturing topic – manufacture of an electric car, chosen because the manufacturing operations are usually revolutionary in nature (high digital maturity deploying the most up-to-date data tools), compared to “old-school evolutionary” (of lower maturity) and that most of these cars are built as Connected Mobility platforms making the car more than just transportation, but a platform for data-powered knowledge and insight. This story will show how data is collected, enriched, stored, served, and then used to predict events in the car’s manufacturing process using Cloudera Data Platform.
This story will feature a mock connected vehicle manufacturing company of electric vehicles called (with a highly original name of) The Electric Car Company (ECC). ECC operates multiple manufacturing factories located across the globe, is vertically integrated building its own cars as well as many of the critical components, including electric motors, batteries, and auxiliary parts. Each factory is charged with manufacturing different components with final assembly taking place in a few select, strategically located factories.
Data Collection Challenge
Managing the collection of all the data from all factories in the manufacturing process is a significant undertaking that presents a few challenges:
- Difficulty assessing the volume and variety of IoT data: Many factories utilize both modern and legacy manufacturing assets and devices from multiple vendors, with various protocols and data formats. Although the controllers and devices may be connected to an OT system, they are not usually connected in a way that they can easily share the data with IT systems as well. In order to enable connected manufacturing and emerging IoT use cases, ECC needs a solution that can handle all types of diverse data structures and schemas from the edge, normalize the data, and then share it with any type of data consumer including Big Data applications.
- Managing the complexity of real-time data: In order for ECC to drive predictive analytics use cases, a data management platform needs to enable real-time analytics on streaming data. The platform also needs to effectively ingest, store, and process the streaming data in real-time or near-real time in order to instantly deliver insights and action.
- Freeing data from independent silos: Specialized processes (innovation platforms, QMS, MES, etc.) within the manufacturing value chain reward disparate data sources and data management platforms that tailor to unique siloed solutions. These niche solutions limit enterprise value, considering only a fraction of the insight cross-enterprise data can offer, while dividing the business and limiting collaboration opportunities. The right platform must have the ability to ingest, store, manage, analyze and process streaming data from all points in the value chain, combine it with Data Historians, ERP, MES and QMS sources, and leverage it into actionable insights. These insights will deliver dashboards, reports and predictive analytics that drive high value manufacturing use cases.
- Balancing the edge: Understanding the right balance between data processing at the edge and in the cloud is a challenge, and this is why the entire data lifecycle needs to be considered. There is a troubling trend in the industry as companies choose to focus on one or the other without realizing they can, and should, do both. Cloud computing has its benefits for long-term analysis and large-scale deployment, but it is limited by bandwidth and often collects vast amounts of data while only using a small portion. The value of the edge lies in acting at the edge where it has the greatest impact with zero latency before it sends the most valuable data to the cloud for further high-performance processing.
Data Collection Using Cloudera Data Platform
STEP 1: Collecting the raw data
Data from ECC’s manufacturing operation encompasses a multitude of sources – industrial robots, body-in-white phosphate coating process tanks (temperature, concentration or replenishment), supply chain telematics, or master part information, etc. For this specific example, the raw part master data for each of ECC’s five factories has been collected in preparation to be fed to Apache NiFi (see Fig 2).
STEP 2: Configure data sources for each factory
Data collection will be illustrated using Cloudera’s Data Flow experience (powered by Apache NiFi) to retrieve this raw data and to split it into individual factory streams (managed by Apache Kafka) to more accurately resemble a real-world scenario (see Fig 2). To keep the example simple, the following data attribute tags were chosen for each part generated by the factories:
- Factory ID
- Machine ID
- Manufactured timestamp
- Part number
- Serial number
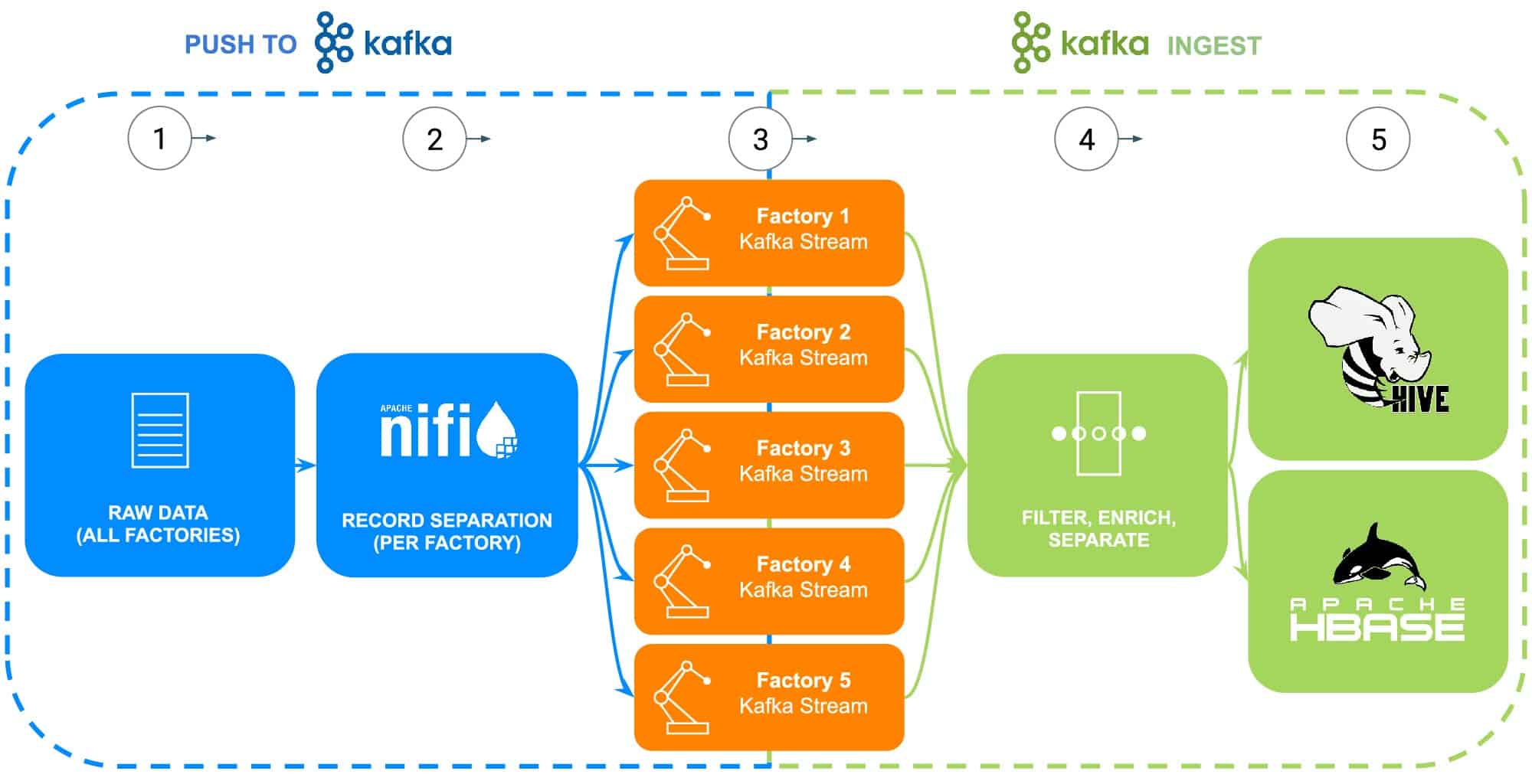
Fig 2: Data collection flow diagram.
STEP 3: Monitor data throughput from each factory
With all the data now flowing into individual Kafka streams, a data architect is monitoring data throughput from each factory as well as adjusting compute and storage resources needed to make sure that each factory has the required throughput to send data into the platform.
STEP 4: Capture data from Apache Kafka streams
Kafka captures all the factory data streams and collects it into processors that will both filter and enrich for use in controlling and running essential business operations powered by an operational database, or delivering business enterprise insight through an enterprise data warehouse or used in advanced analytics.
ECC has recently started production of an upgraded version of their electric motor that’s only being produced in Factory 5, this data will be used as illustration of the next steps in the data lifecycle
STEP 5: Push data to storage solutions
Since the ECC manufacturing and quality engineers will want to closely monitor the deployment and field use of this motor, the specific manufacturing traceability data is filtered into a separate route and saved into its own table in Apache Hive. This will allow the engineers to run ad-hoc queries in Cloudera Data Warehouse against the data later as well as join it to other relevant data in the enterprise data warehouse, such as repair orders or customer feedback to produce advance use cases like warranty, predictive maintenance routines, or product development input.
Alternatively, if controlling and running essential business operations are desired, the entire dataset with the addition of a processed timestamp will be sent into the Apache HBase powered Cloudera Operational Database. This data will serve as the foundation for ECC to run their inventory platform, which will require the use of constant read/write operations as inventory can be both added and removed thousands of times per day. Since HBase is designed to handle these kinds of data transactions on a large scale, it serves as the best solution for this unique challenge.
Conclusion
This simple illustration shows the importance of getting data ingestion right, as it is foundational for insights delivered from both operational databases, enterprise data warehouses or advanced analytic machine learning predictive analytics. Value in “getting it right” include using data from any enterprise source thus breaking down data silos, using all data whether it be streaming or batch-oriented, and the ability to send that data to the right place producing the desired down stream insight.
Using CDP, ECC data engineers and other line of business users can start using collected data for various tasks ranging from inventory management to parts forecasting to machine learning. Since Cloudera Data Flow promotes real-time data ingestion from any enterprise source, it can be expanded and maintained without extensive knowledge of various programming languages and proprietary data collection methodologies. If unique issues are encountered, engineers can also create their own processes for truly, fine-grained control.
Look for the next blog that will delve into data enrichment and how it supports the data lifecycle story. In addition, this story will be augmented with data-driven demos showing the data journey through each step of the data lifecycle.
More Data Collection Resources
To see all this in action, please click on the related links below to learn more Data Collection:
- Video – If you’d like to see and hear how this was built, see video at the link.
- Tutorials – If you’d like to do this at your own pace, see a detailed walkthrough with screenshots and line by line instructions of how to set this up and execute.
- Meetup – If you want to talk directly with experts from Cloudera, please join a virtual meetup to see a live stream presentation. There will be time for direct Q&A at the end.
- Users – To see more technical content specific for users, click on the link.
Editor's Choice

