

Introduction
Cloud data warehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. With the ability to quickly provision on-demand and the lower fixed and administrative costs, the costs of operating a cloud data warehouse are driven mostly by the price-performance of the specific data warehouse platform. With pay-as-you-go pricing, platforms that deliver high-performance benefit users not only through faster results but also through direct cost savings.
Cloudera Data Warehouse is a highly scalable service that marries the SQL engine technologies of Apache Impala and Apache Hive with cloud-native features to deliver best-in-class price-performance for users running data warehousing workloads in the cloud. But don’t just take our word for it. McKnight Consulting Group recently published their own third party benchmark study comparing the price-performance of Cloudera Data Warehouse to 4 other prominent cloud data warehouse vendors. The results demonstrate superior price performance of Cloudera Data Warehouse on the full set of 99 queries from the TPC-DS benchmark. The following price-performance summary is directly from the McKnight report:
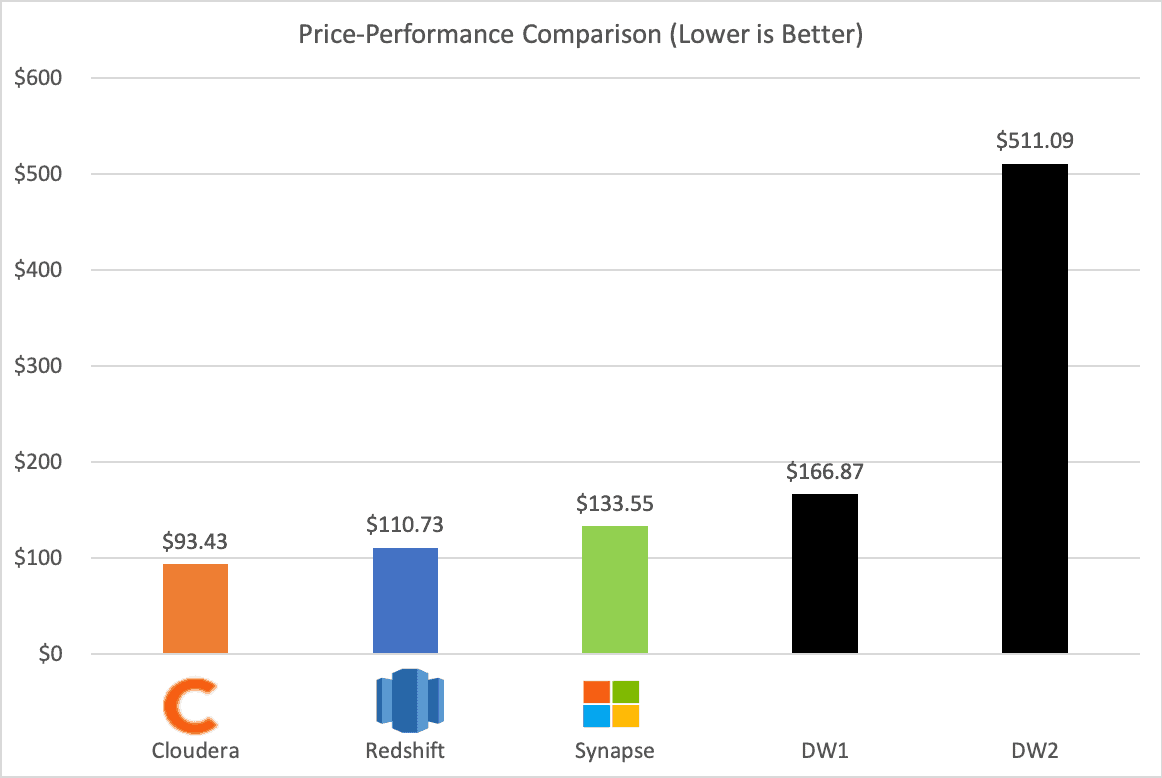
The chart compares the cost to run the full 99 query TPC-DS workload at a scale factor of 30 TB on Cloudera Data Warehouse (CDW) vs the 4 competitors. DW1 is an anonymized cloud data warehouse running on AWS and DW2 is an anonymized data warehouse running on GCP. As depicted in the chart, Cloudera Data Warehouse ran the benchmark with significantly better price-performance than any of the other competitors tested. Compared to CDW, Amazon Redshift ran the workload at 19% higher cost, Azure Synapse Analytics had 43% higher cost, DW1 had 79% higher cost, and DW2 had 5.5x higher cost.
This post will describe some of the features of CDW that allow it to deliver this leading price-performance and explore the McKnight benchmark results in more detail.
Overview of Cloudera Data Warehouse
Cloudera Data Warehouse is a cloud-native data warehouse based on the Apache Impala and Apache Hive SQL engines, deployed using a containerized architecture based on Kubernetes. CDW is one of several managed services that comprise the broader Cloudera Data Platform (CDP).
Much of the performance benefit of CDW stems from the high performance of the underlying SQL engines. CDW supports running queries on either Apache Hive or Apache Impala engines. The benchmark run by McKnight Consulting Group used the Impala engine. Impala has a longstanding reputation for high performance and concurrency, low latency for interactive queries, and the CPU efficiency of it’s C++ backend with dynamic code generation based on LLVM. The Impala team continues to innovate to ensure continuing performance leadership. Some examples of recent optimizations in Impala include:
- New multithreading model (see dedicated blog post).
- Remote read optimizations:
- Impala use of KRPC (see dedicated blog post).
- General backend improvements:
- IMPALA-5444: Asynchronous code generation
- IMPALA-9655: Dynamic intra-node balancing for HDFS scans
- Parquet page indexes (see dedicated blog post)
- Planning improvements:
CDW benefits from all of these optimizations in the core SQL engine and combines them with a set of additional cloud-native features that deliver the best-of-breed performance demonstrated in the McKnight benchmark:
- Containerized deployment via Kubernetes for fast cluster provisioning.
- Elastic resource management including autoscaling and auto-shutdown to ensure resources are dynamically and correctly sized based on workload requirements.
- Optimized read and write paths to cloud object stores (S3, Azure Data Lake Storage, etc) with local caching, allowing workloads to run directly against data in shared object stores without explicit loading to local storage.
- Tuned default configurations for “out-of-the-box” performance without requiring custom tuning.
- Isolation of compute to prevent contention between tenants.
In addition to its strong performance, CDW has a number of other differentiators that make it a compelling choice compared to other cloud data warehouses including:
- Support for hybrid cloud deployments with a consistent experience, using the same containerized architecture to run on multiple public clouds and also on-premise in private cloud deployments.
- CDW fully separates compute and storage and runs queries directly against data in cloud object stores using fully open and standard data formats (Apache Parquet and Apache ORC). Multiple analytical engines within the broader CDP (data warehousing, machine learning, data engineering) can operate on the same shared data in these file formats. Other vendors in this benchmark use closed, proprietary data formats and/or require an explicit loading step to import data from shared object storage prior to query execution.
- As part of the broader CDP, CDW participates in a centralized security and governance model managed by CDP’s Shared Data Experience (SDX). This provides consistent security and metadata architecture as CDW interacts with other services within CDP.
Benchmark Description
The details of the benchmark are fully described in the McKnight report, but the key points are summarized below.
- The data sets and queries used were derived from the industry-standard TPC-DS benchmark.
- The scale factor used for the benchmark was 30 TB and the data was generated using the standard data generation tool from TPC.
- The benchmark included 99 queries, 4 of which have 2 parts (queries 14, 23, 24, and 39) for a total of 103 queries. The queries were compliant with version 2.13 of the TPC-DS specification.
- The cluster configurations for each vendor were chosen to achieve similar hourly costs for each vendor, to the extent possible. The cluster size for the CDW run used 64 executor nodes. Cluster size details for other vendors can be found in the McKnight report.
- Three runs of the full set of 103 queries were executed for each vendor and the primary metric reported was the total execution cost of the fastest of the three runs.
- For the CDW runs, no benchmark specific tuning was performed on the cluster. The desired 64 node cluster size was specified during provisioning and default settings were used.
- The CDW runs were done against Parquet formatted data in S3. No local data loading step was required prior to query execution. Note the contrast between this and Amazon Redshift which requires an explicit data loading step from S3 into managed/local storage (the time required for this step in the case of Redshift wasn’t included in the reported benchmark timing).
- For those interested in the details of the schema used for the CDW runs, both the CDW schema and queries are available here: https://github.com/cloudera/impala-tpcds-kit
Results Drill Down
The chart in the introduction above highlighted the fact that CDW has the lowest total cost to run the full 99 query workload. In addition to this aggregate metric, it’s interesting to look at results for individual queries from the benchmark. The McKnight report includes a table with individual per query costs for each vendor. Below we explore a few alternative visualizations using this same per query data.
First, let’s look at the individual query execution times and costs for Cloudera Data Warehouse, using a visualization that makes it easy to see the distribution of performance across the queries.
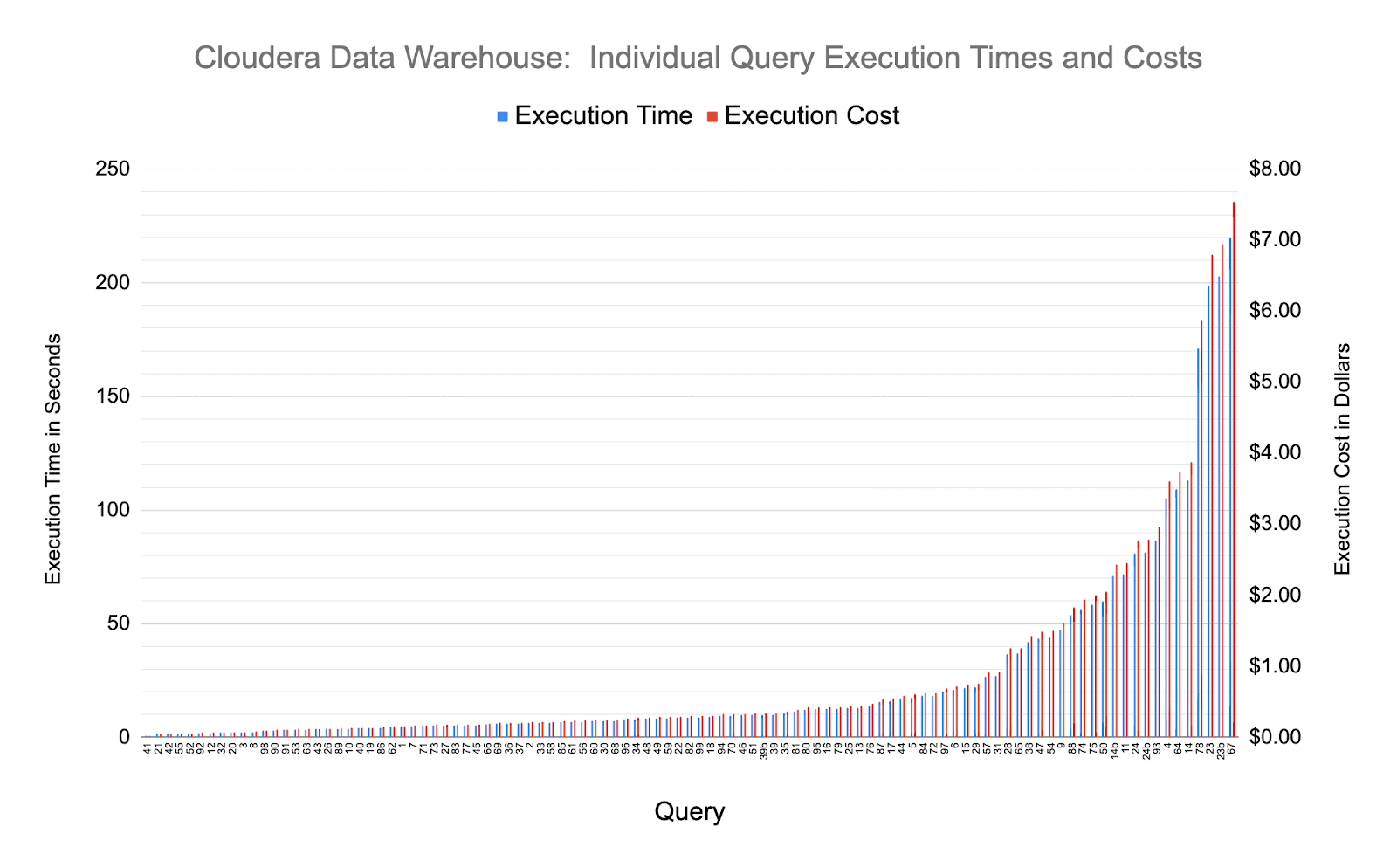
One takeaway from this chart is that CDW provides interactive performance for the majority of queries in the benchmark, with two-thirds of the queries completing in less than 15 seconds (15 seconds equates to a cost of 50 cents using the CDW hourly cluster cost of $123.26).
We can also look at how well other vendors do in achieving this kind of consistently low per query cost. The following chart compares the percentage of queries for each of the vendors that run with individual query cost < 50 cents.
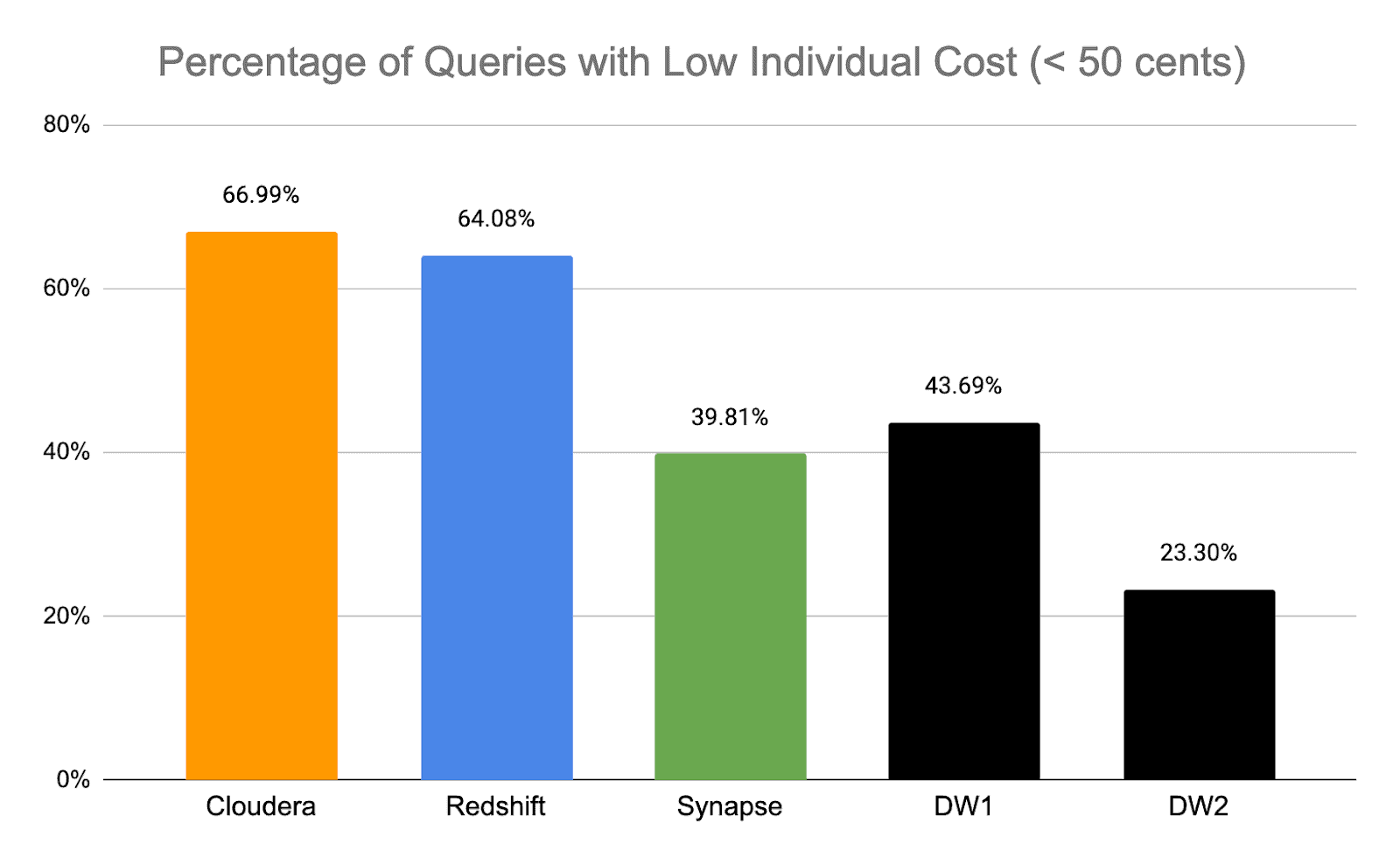
Again, we see the strong interactive performance of CDW which has the highest percentage of queries meeting this low-cost threshold.
Finally, we can look at the ability of different vendors to limit worst-case costs for longer running queries.
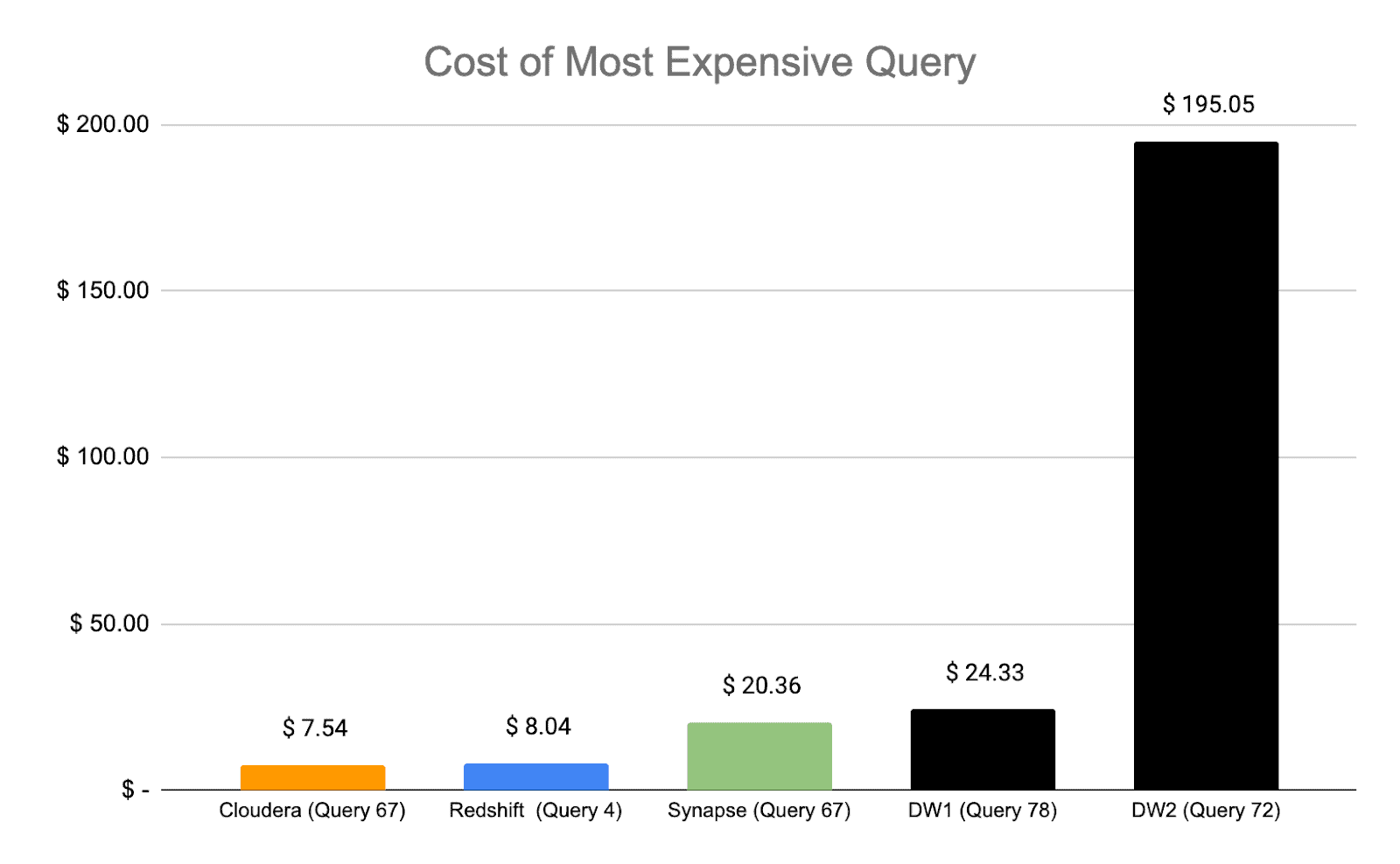
CDW is also strong in this dimension, with the lowest cost for its worst-performing query.
We’ve highlighted just a few of the interesting dimensions of the individual query results here. Readers interested in exploring the details in more depth can find the full results in the McKnight report.
Summary
Performance is a critical attribute to consider when choosing a cloud data warehouse. Because usage costs are a function of execution time, a high-performance platform benefits users not only through faster results but also through direct cost savings. Cloudera Data Warehouse builds on the high-performance foundation of Apache Impala and Apache Hive, with an optimized cloud-native architecture and support for both public cloud and on-premise private cloud deployments. The recent benchmark by McKnight Consulting Group demonstrates the best-in-class price-performance of CDW.
You can download the McKnight report here, and learn more by exploring other blog posts about CDW, Impala, and Hive.
Editor's Choice


Costing seems a bit inconsistent here, if you could kindly address. The pricing for Azure DW7500c is listed as $113.25 per hour though public pricing is $90. That would be a 20% reduction, resulting in price performance of $106? Unless you include monthly 1TB cost, though managed RA3 storage costs don’t seem to be factored in either. Any idea why that is?
From a quick look at the published Azure pricing, it looks like pricing varies per region. 5 of the 8 regions in the U.S. have published pricing of $113.25 per hour for DW7500c and 3 regions are priced at $90. The McKnight report states they did their testing for all the platforms, including Azure, in East US so it seems the pricing is based on that region where the published price is $113.25 per hour.
Thanks for the quick response David – agree, as a Cloudera user in Azure, East US is a costly choice in general, all our clusters are in “East US 2” which is generally cheaper, incl. Synapse at $90. Worth noting to preempt people calling bias.
Resource efficiency is the key to high productivity and savings. Both of these metrics are important for storage. That’s why Cloudera is a great choice.