

Key Takeaways
We have significantly improved Impala in CDH 5.15.0 to address some of the scalability bottlenecks in query execution. 64 concurrent streams of TPC-DS queries at 10TB scale in a 135-node cluster now run at 6x query throughput compared to previous releases. In addition to running faster, the query success rate also improved from 73% to 100%. Overall, Impala in CDH 5.15.0 provides massive improvements in throughput and reliability while reducing the resource usage significantly. It can now reliably handle concurrent complex queries on large data sets that were not possible before.
Motivation
Apache Impala is a massively-parallel SQL execution engine, allowing users to run complex queries on large data sets with interactive query response times. An Impala cluster is usually comprised of tens to hundreds of nodes, with an Impala daemon (Impalad) running on each node. Communication between the Impala daemons happens through remote procedure calls (RPCs) using the Apache Thrift library. When processing queries, Impala daemons frequently have to exchange large volumes of data with all other nodes in the cluster, for example during a partitioned hash join.
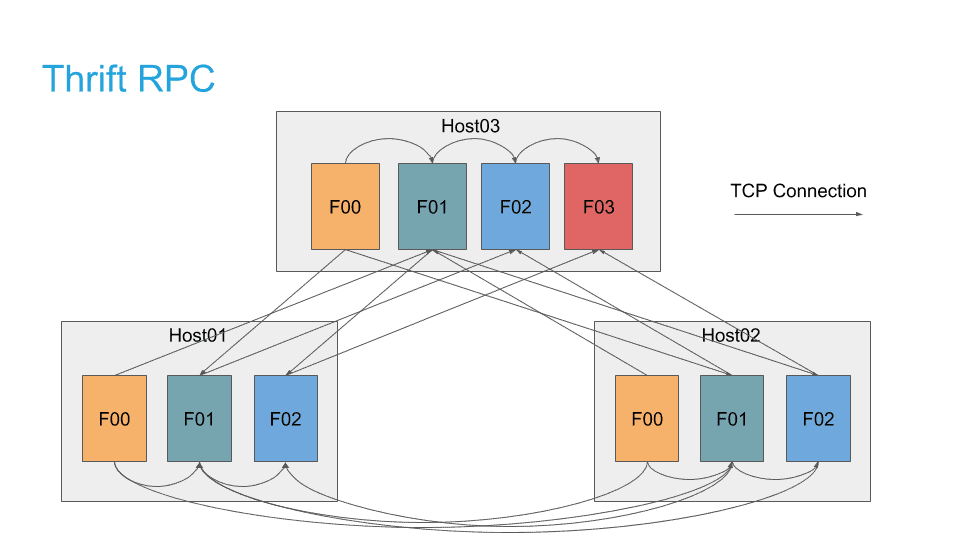
The previous RPC implementation in Impala only supported synchronous Thrift RPCs. To simulate asynchronous RPC, RPC threads were created in per-query-fragment thread pools. The RPC server implementation also used the thread-per-connection model. Due to the architectural limitations of this implementation, the number of RPC threads on each host scaled with the product of:
(Number of Hosts) x (Query Fragments per Host)
For a 100-node cluster with 32 concurrent queries, each of which had 50 fragments, this resulted in 100 x 32 x 50 = 160,000 connections and threads per host. Across the entire cluster, there would be 16 million connections.
In addition, each RPC thread had to open and maintain its own connection. There was no mechanism to support multiplexing of parallel requests between two machines over a single connection. This means that each fragment of each query would have to maintain connections to all other hosts in the cluster. To avoid creating too many connections, Impalad implemented a connection cache to recycle network connections. However, the connection cache didn’t handle stale connections cleanly, which has led to unexpected query failures or even wrong results in the past.
As more nodes are added to a CDH cluster due to growth of data and workloads, Impalad prior to CDH 5.15.0 runs into scalability limitations. The excessive number of RPC threads and network connections created under load led to instability and poor Impala performance. Often times, administrators needed to tune operating system parameters in order to keep Impalad from exceeding default system limits while running highly concurrent workloads even in a modest-sized cluster (for example, 100 nodes). Even then, the performance still suffered.
On top of these scale limitations, the Thrift library does not support SASL authentications and we had to maintain our own implementation of SASL for Thrift.
The Solution
To address the pain points above, we explored alternate RPC frameworks for Impala’s RPC stack and decided to adopt the RPC implementation of the Apache Kudu project for our internal RPCs.
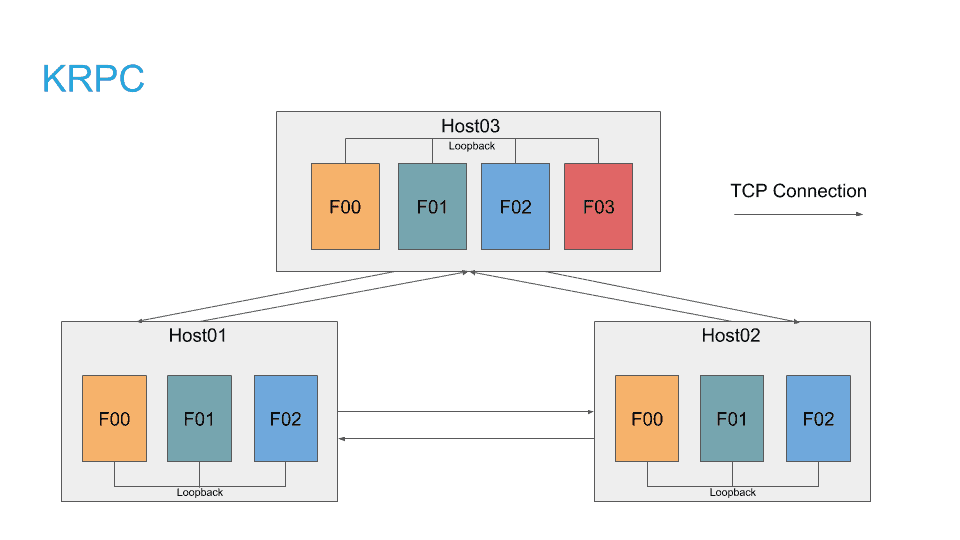
Kudu RPC (KRPC) supports asynchronous RPCs. This removes the need to have a single thread per connection. Connections between hosts are long-lived. All RPCs between two hosts multiplex on the same established connection. This drastically cuts down the number of TCP connections between hosts and decouples the number of connections from the number of query fragments.
The error handling semantics are much cleaner and the RPC library transparently re-establishes broken connections. Support for SASL and TLS are built-in. KRPC uses protocol buffers for payload serialization. In addition to structured data, KRPC also supports attaching binary data payloads to RPCs, which removes the cost of data serialization and is used for large data objects like Impala’s intermediate row batches. There is also support for RPC cancellation which comes in handy when a query is cancelled because it allows query teardown to happen sooner.
Results
We did an evaluation of TPC-DS 10TB in a cluster with 135-nodes using different levels of concurrency. Each node in the cluster had 88 vcores and 264 GB of memory and was deployed with Centos 6.7. This configuration was similar to a medium scale cluster in a typical deployment. For both RPC implementations, we measured the throughput (queries per hour) and the query success rate (percentage of queries which completed without any error). The cluster was set up as follows:
- One node used as the dedicated coordinator, which did not act as an executor
- 132 nodes as executors
- One node used to run the catalog daemon
- One node used to run the statestore daemon
The file handle cache size was also configured to 131K which was larger than the default value of 20K to prevent the HDFS name node from being the bottleneck. The cluster was restarted between runs of the experiment, and each iteration did an initial warm-up run of all queries to pull in the metadata. This ensured a consistent environment for reproducibility of the results, which are shown in the below sections.
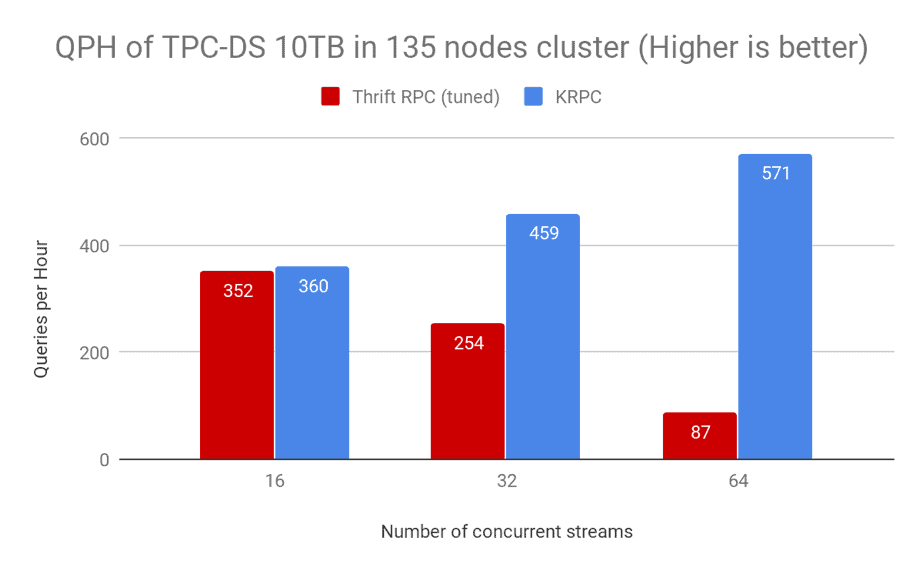
As shown in the above graph, 32 concurrent streams of TPC-DS queries show a 2x throughput when using KRPC. The improvement is even more dramatic (6x) with 64 concurrent streams.
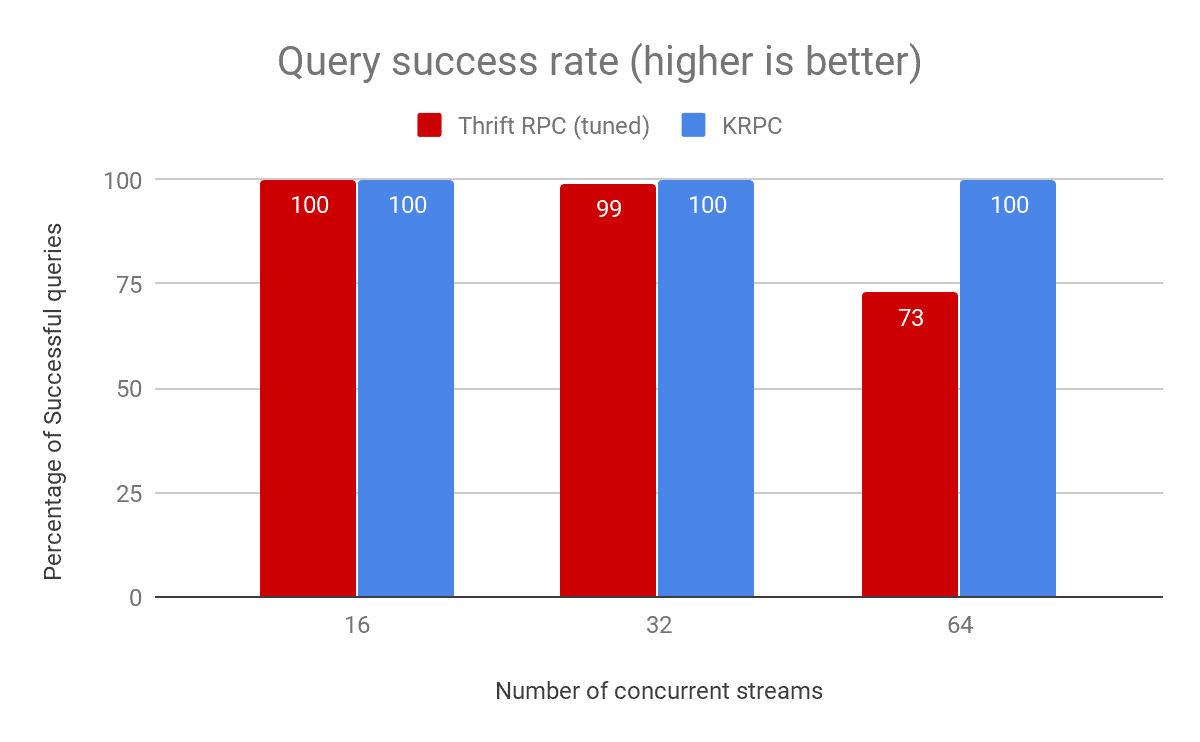
Running these benchmarks using Thrift RPC required tuning operating system parameters to allow for the increased resource usage. Without this tuning, the query success rate is significantly lower. For KRPC, we get a 100% success rate out of the box without having to change those operating system parameters as shown in the following graph.
Outlook and Roadmap
KRPC is enabled by default in Impala in CDH 5.15.0. It can be optionally disabled with a startup flag in the Impala Command Line Argument Advanced Configuration Snippet in Cloudera Manager. A handful of Cloudera customers upgraded their production clusters to newer releases with KRPC and have seen significant improvement in performance and stability, especially under highly concurrent workloads.
While the above results look promising, Impala in CDH 5.15.0 has only adopted KRPC for a subset of internal RPCs. Even with CDH 5.15.0, the number of RPC threads on the coordinator is still significantly higher than that on executors because the status reporting RPCs are still implemented with Thrift. To prevent queries from hanging or failing in workloads with extremely high concurrency, multiple dedicated coordinators are required. This will be improved subsequently by converting the rest of Thrift-based internal RPCs in Impala to the KRPC framework. For those who are interested in tracking the progress, please see IMPALA-5865.
For Impala clients such as the impala-shell, we continue to support Thrift RPC only.
Acknowledgement
This project was started by Henry Robinson and he did a lot of the heavy lifting of integrating the subset of the Kudu code base into Impala. Todd Lipcon, the founder of the Apache Kudu project, is the original author of the Kudu RPC framework. There was a lot of help from various Impala contributors, including Dan Hecht, Sailesh Mukil, Mostafa Mokhtar, Joseph McDonnell, and Michael Brown.
Michael Ho is a software engineer at Cloudera. He has been contributing to the Apache Impala project for the past 3+ years.
Lars Volker is a software engineer at Cloudera. He has been contributing to the Apache Impala project for the past 3+ years.
Laurel Hale is a technical writer at Cloudera. She has been documenting various Cloudera data warehousing products for the past 3+ years.
Editor's Choice

