


Introduction
Today we are introducing a new series of blog posts that will take a look at recent enhancements to Apache Impala. Many of these are performance improvements, such as the feature described below which will give anywhere from a 2x to 7x performance improvement by taking better advantage of all the CPU cores. In addition, a lot of work has also been put into ensuring that Impala runs optimally in decoupled compute scenarios, where the data lives in object storage or remote HDFS. This is especially important now that more and more users are running containerized Impala clusters, such as what is offered in the Cloudera Data Warehouse (CDW) service.
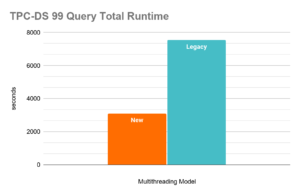
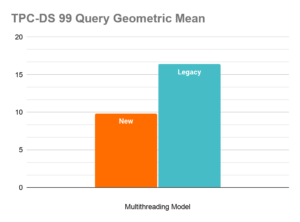
Figure 1. Performance Improvements with Apache Impala’s New Multithreading Model (20 executors, mt_dop=12)
Purpose of the new multithreading model
In this first post we will focus on work that was recently completed to expand the multithreading model used during query execution. But first, some context. Two of the key tenets of Impala’s design philosophy are:
- Parallelism – for each part of query execution, run it in parallel on as many resources as possible
- Open File Formats – provide native querying over open source file formats like Apache Parquet and ORC to prevent lock-in and encourage interoperability
From day one Impala has been able to break a query up and run it across multiple nodes – a true Massively Parallel Processing (MPP) engine. This is scale out at its best. A few years ago we added multithreaded scans, whereby many threads on each node scan the required data simultaneously. This further increased parallelism by adding the ability to scale up within a node, albeit for a limited number of operations. That brings us to today, where we are now able to multithread both joins and aggregations, letting us parallelize each part of query execution – both by scaling out and by scaling up. With this new change, the key operations in a query can be scaled vertically within a node if the input data is large enough (i.e. enough rows or distinct values.)
This is where the point about open file formats becomes relevant. No other cloud data warehouse engine currently offers native querying over open file formats stored in object stores with competitive performance on joins and aggregations. These are the common bottlenecks in analytic queries, and are notoriously difficult to optimize.
Most query engines achieve performance improvements at the join and aggregation level by taking advantage of tight coupling between the query layer and the storage layer. Their secret sauce usually results in proprietary formats and/or a requirement for local storage. So performance is improved at the expense of flexibility, interoperability, and cost. Impala is the first SQL engine that has effectively married this class of SQL optimizations with open file formats in the cloud storage context.
How the new multithreading model works
If you are a TL;DR person, here you go:
- We parallelize queries within a node in the same way that we parallelize them across nodes – by running multiple instances of a fragment.
- Each instance runs single-threaded and sends data to other instances via the exchange operator – the same mechanism used for inter-node communication.
- The degree of parallelism (dop) for a query or session is controlled by a parameter called mt_dop (MultiThreading Degree Of Parallelism).
Read on if you want more details…
Plan Generation
Impala’s existing plan generation proceeds in two phases: first a single-node plan is generated from analysis output; then that is transformed into a distributed plan. With this new multithreading model a third phase is added. The distributed plan, which is a tree of plan fragments, is transformed into a parallel plan, which is a tree of distributed plans. The distributed plans are connected by join build operators that set up a join operator in the parent plan for streaming in-memory execution, e.g. building in-memory hash tables for a hash join.
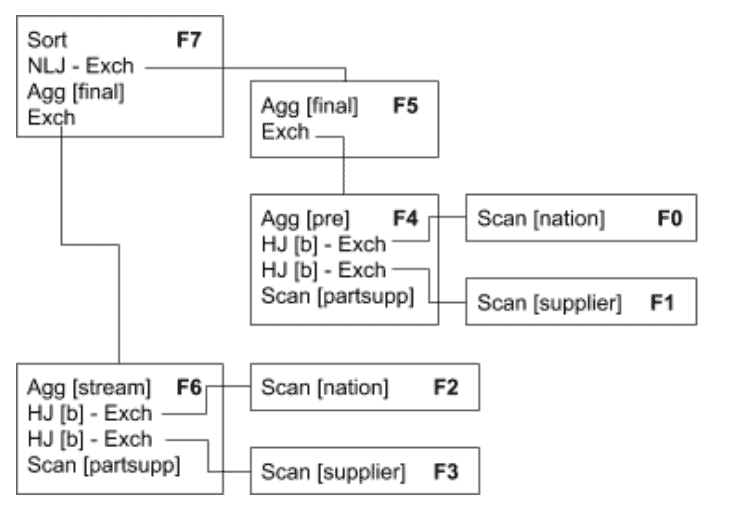
The following images show an example using TPC-H query 11. The first one is a distributed plan, where each box is fragment.
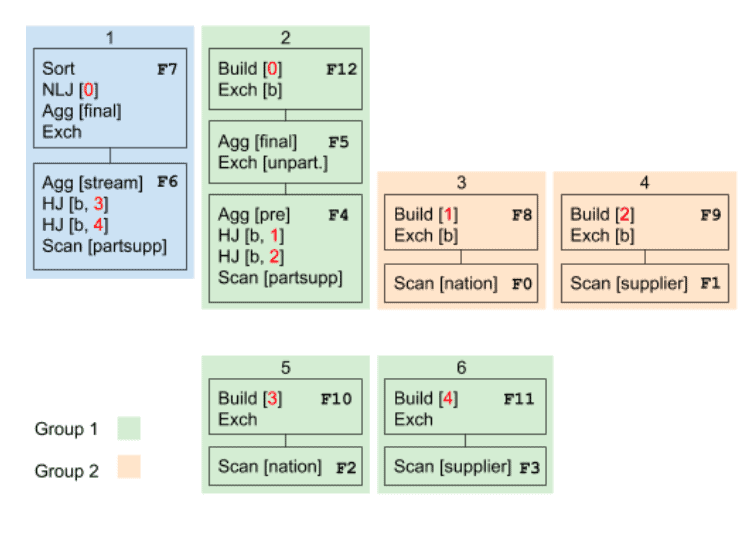
The second is the corresponding parallel plan, where:
- the root of the tree of plans, plan 1, is shown in blue
- its immediate children form group 1, which has an additional parallel planning phase, and are shown in green
- the build output ids are shown in red
- the immediate children of the Build[0] plan form group 2 and are shown in orange
Scheduling
Impala’s scheduler takes a parallel plan, which has been divided up into fragments, and determines how many instances of those fragments to run and on which nodes. The process is summarized below.
- Allocate scan ranges to nodes based on data locality and the scheduler’s load balancing heuristics.
- Create fragment instances on those nodes, with scan ranges divided between instances. mt_dop caps the maximum number of instances that will be created per node.
From the example above, if the partsupp table is divided into 32 evenly-sized remote scan ranges and run on 4 nodes with mt_dop=4, each node might be allocated 8 scan ranges (depending on data locality), which could then be divided between up to 4 instances of F6 per node. Each of these F6 instances is then executed by a different thread, utilizing 4 CPUs on each node in parallel. In the diagram below each fragment instance is represented by a white square, which illustrates both the scale out and the scale up of this scan operation.
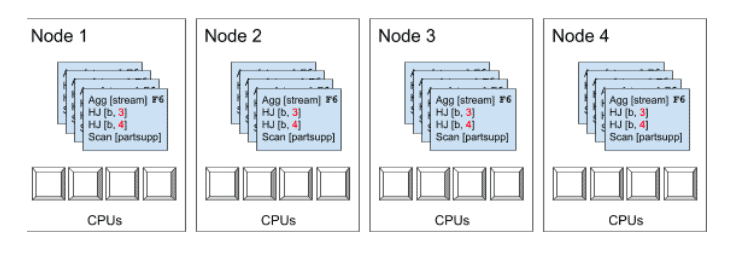
Config Options
It was a conscious decision to keep the tuning options for the new multithreading model simple. This is why the single mt_dop option was chosen. It determines the maximum degree of parallelism for a query, and Impala will automatically reduce the level of parallelism if the query is smaller. This option can be set at the server, resource pool, session and query level. In addition to giving users a knob to tune the level of intra-node parallelism, this has an important side effect of making scheduling easier and query latencies more predictable.
Admission Control
Introducing the mt_dop variable means that Impala queries can have very different CPU requirements. Therefore we have to factor this into admission control decisions to avoid underutilization as well as oversaturation. For example, more concurrent queries can be run with low dop than with high dop, since the cores are not oversubscribed.
Impala has a concept of “admission control slots” – the amount of parallelism that should be allowed on an impala daemon. This defaults to the number of processors, and can be overridden with –admission_control_slots. The admission control slot model offers the best path forward for admission control and multithreading.
A query running on an executor will consume slots based on the effective dop, which is computed as the maximum number of instances of a fragment running on the executor. E.g. if there are 2 instances of F0 and 4 instances of F1, the effective dop is 4.
It is desirable in some cases to oversubscribe Impala to maximise CPU utilization, or, on the flipside, to achieve predictability by avoiding oversubscription. This trade-off can be managed by changing –admission_control_slots to be greater than, or equal to the number of cores on the system.
Impact to Resource Consumption
We have sought to minimize or eliminate the additional impact to CPU, memory, and network related to overhead from this new multithreading model. Some notable points are below:
- I/O continues to benefit from multithreading as it has in the past, and there is no additional overhead introduced by this new model.
- There may be some impact on total network traffic in high-cardinality grouping aggregations.
- We will see a bounded increase in minimum memory reservation per additional fragment instance because of the minimum memory reservation of the hash join, hash aggregation, sort, analytic and runtime filters – typically 1MB to 40MB per instance. If memory limits are set very low or the plan is very complex, users can reduce mt_dop to address this.
- The peak memory requirements for a query may increase somewhat because of the increased number of threads, but we made efforts to avoid a significant increase for most queries by reducing memory requirements per thread. Aggregate memory consumption of each query is often reduced because the queries finish and release resources faster.
Query Execution Impact Examples
In this section we look at a few examples of the impact that this new multithreading model has on various steps of the execution process. This gives an idea of implementation details, as well as the work that is done to minimize the amount of CPU and memory overhead required to use the multithreading model.
Grouping Aggregation
The Grouping Aggregation is parallelized by a) replicating the pre-aggregation in each fragment instance, and b) partitioning the input to the merge aggregation across all fragment instances.
Broadcast Hash Join
For the Broadcast Hash Join, the parallelization is based on a separation of the build and probe phases into distinct plans. One builds the data structures needed for the Hash Join and Nested Loop Join, and one probes them and produces result rows.
Exchange
One consequence of this is a significant increase in the number of fragment instances participating in each exchange. For example a hash exchange for a partitioned join previously would have data streams from at most # nodes instances; now it has data streams from # nodes * dop instances. To offset this KRPC will multiplex all these logical streams onto a single point-to-point connection between each pair of nodes, which avoids many potential scalability problems.
Analytic Functions
Analytic functions depend on the PARTITION BY clause for parallelism. Input rows are hash-partitioned across instances, then evaluation of each partition is done independently. Potential speedup from multithreading is only possible if there are more partitions than nodes. If that is the case, then linear speedup can be achieved since evaluation of each partition is independent.
Runtime Code Generation
Runtime code generation in Impala was historically done for each fragment instance. This approach could still work with the new multithreading model, but it would be wasteful – it redundantly generates the code dop times per fragment instance. Instead, we have refactored code generation so that it is done once for all instances of the same fragment on an impala daemon. Other improvements to minimize the impact of runtime code generation include the recently implemented asynchronous codegen improvement (IMPALA-5444), as well as the work on codegen caching that is currently in progress.
Runtime Filters
Runtime filters are currently generated by the relevant fragment instances, then sent to the Coordinator, which then sends them independently to each fragment on all relevant nodes. Due to multithreading, the number of filters for partitioned joins will increase by a factor of dop, potentially resulting in the Coordinator becoming a bottleneck. To prevent this, we aggregate partitioned join filters locally on each node before sending to the Coordinator so that the total amount of work done on the coordinator does not depend on the degree of parallelism.
Sample showing effects of multithreading
To drill down into how multithreading may impact your query performance we took query 84 from the TPC-DS benchmark below as an example. This query involves joining two large fact tables together with four dimension tables. The query plan graph below indicates that the brightly colored operations take the largest part of the query execution time. In this case the bulk of the time is dedicated to performing join operations, which means the query is likely more bottlenecked by CPU than I/O, making it a good candidate for multithreaded execution.
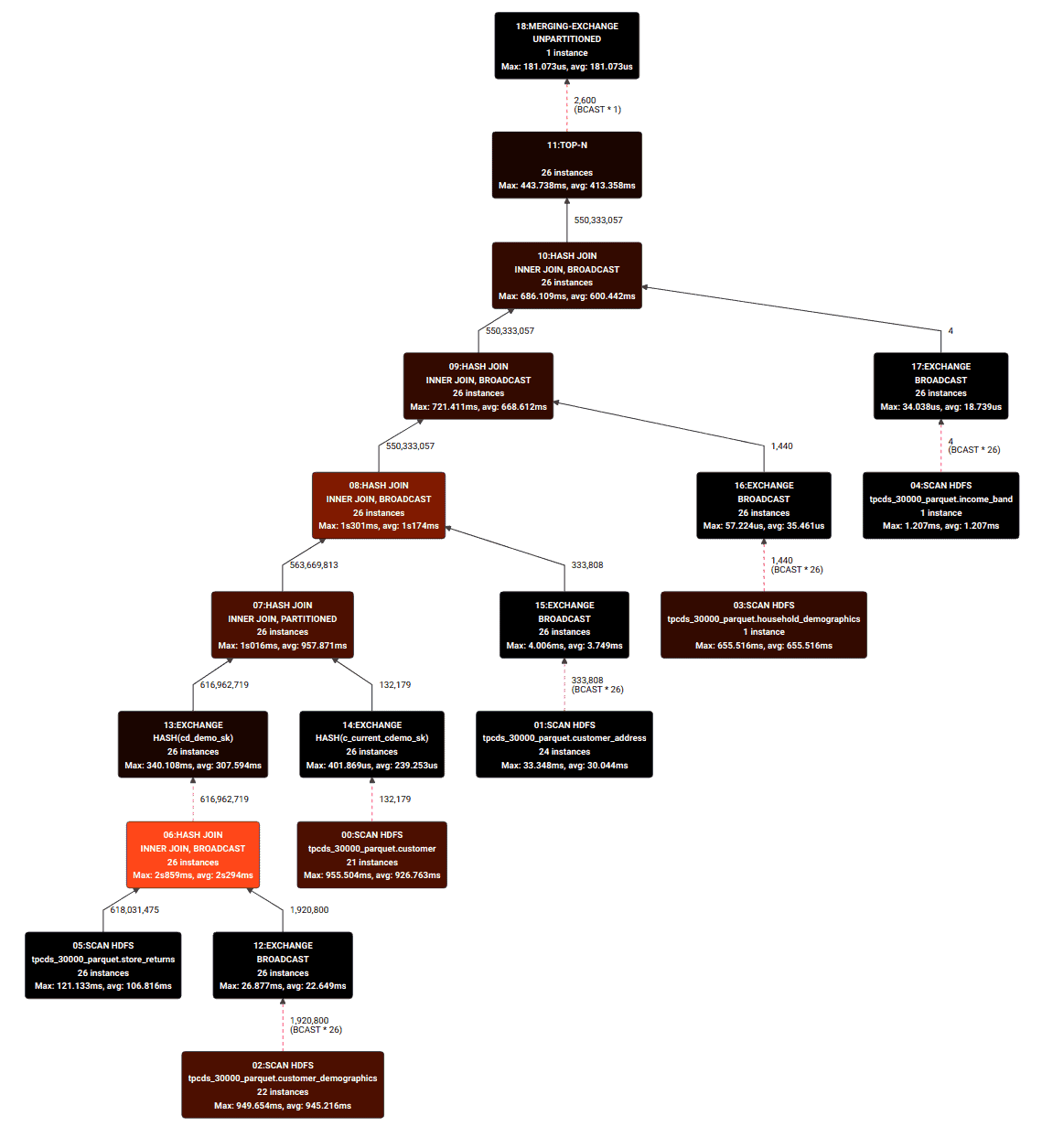
To see how well this query might scale up with more CPU cores we ran it with a dop equal to 1 and then subsequently ramped up the configured parallelism. This test was done on the CDW service, using instances with 16 vCPUs (r5d.4xlarge) querying a 10TB TPC-DS dataset stored as Apache Parquet files in S3.
| Degree of Parallelism | Runtime (sec) |
| mt_dop=1 | 151.85 |
| mt_dop=2 | 73.48 |
| mt_dop=4 | 38.03 |
| mt_dop=8 | 22.88 |
| mt_dop=12 | 20.07 |
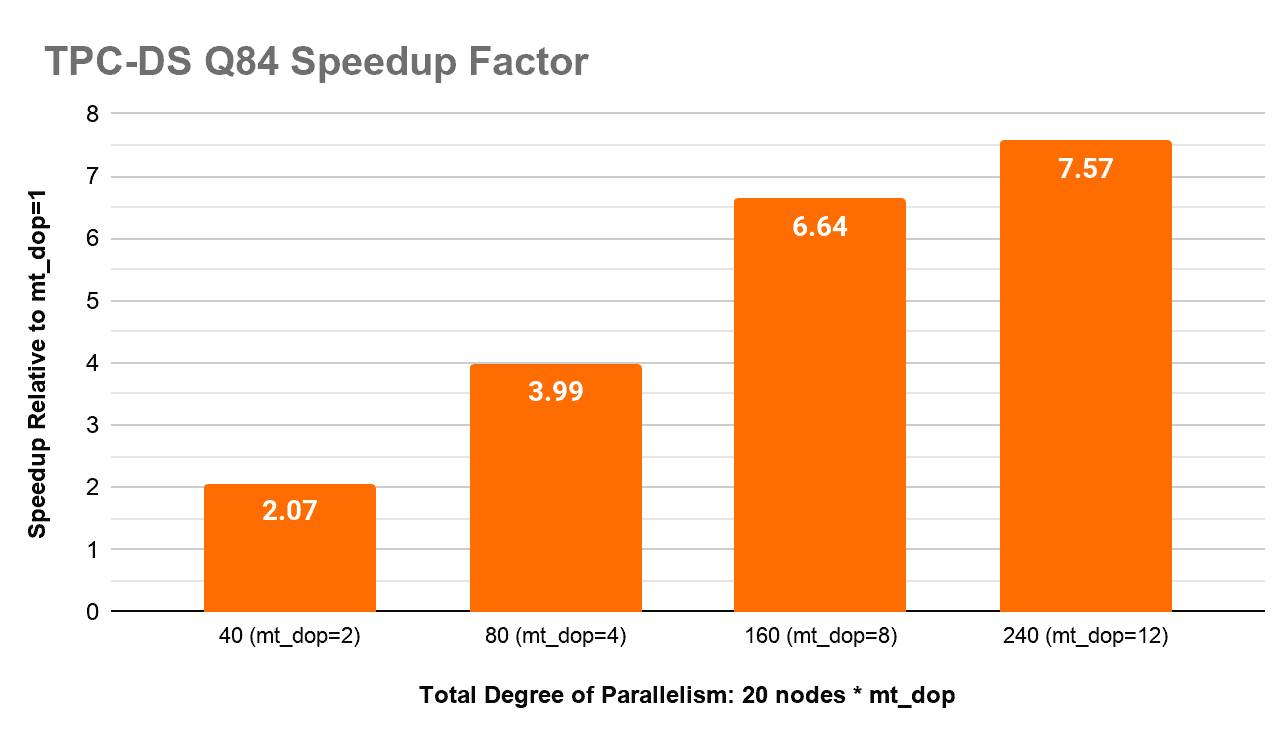
Using the runtime from a dop of one as the baseline we can see a near-linear increase in performance up to a degree of 4. However, we have a slight tapering off at 8 and with a parallelism of 12, we aren’t doing better than a 7.5x performance improvement. Many things can be a factor for the diminishing returns, including data skew, 16 virtual versus 8 physical CPUs, or other implementation inefficiencies discussed in later sections. We believe this is a great start and we see many opportunities to continue improving the parallel scalability of Impala. We know picking the correct degree of parallelism can be a nuisance for the end-user or Impala administrator, so we plan to work on automatically determining the best value during query execution in future releases.
Performance analysis
In an internal TPC-DS benchmark analyzing performance improvements resulting from this new multithreading model (comparing mt_dop=1 vs mt_dop=12), we saw:
- Total runtime improvement across all 99 queries of 2.43x (from 7,549 sec to 3,104 sec)
- Geometric mean runtime improvement across all 99 queries of 1.66x (from 16.38 to 9.84)
The chart below shows the 36 queries that had 2x or more runtime improvements to give examples of where we saw the biggest gains.
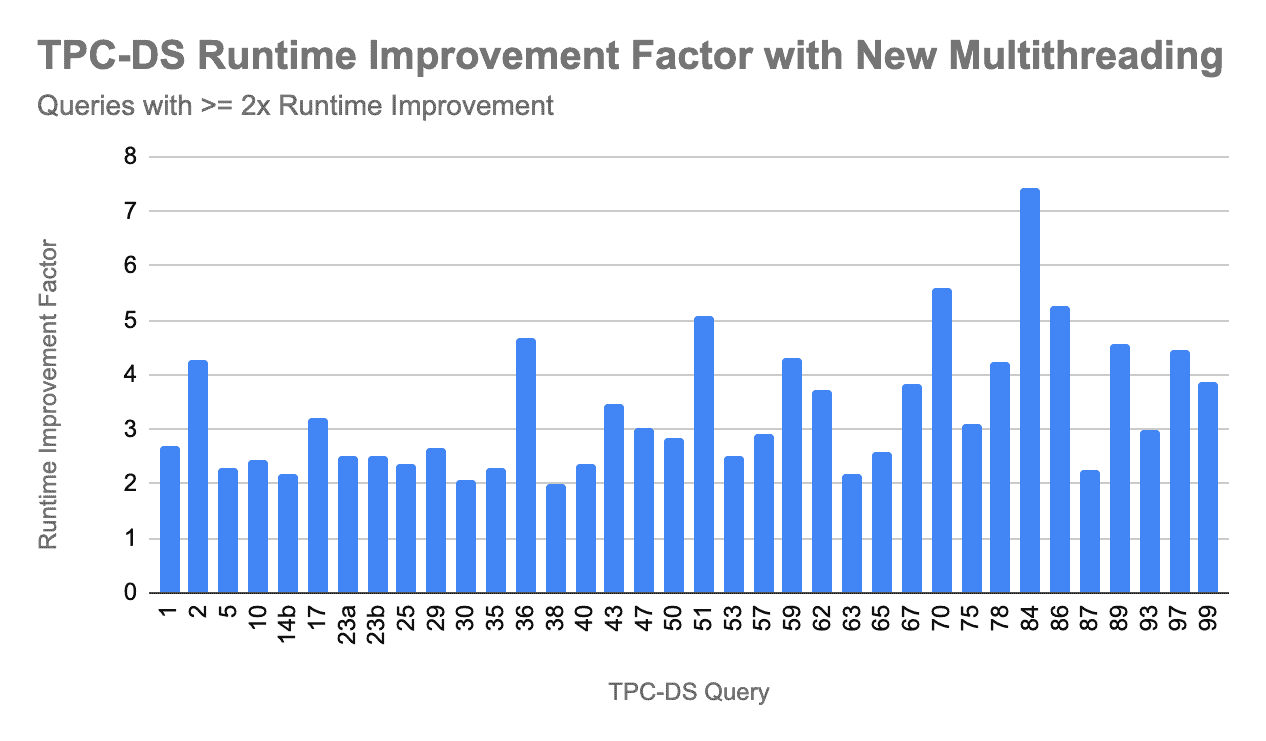
Some important notes about this testing are worth mentioning:
- For queries that aggregate or hash join on skewed keys, the benefit from multithreading is not as pronounced, because only a very small number of nodes are able to benefit from higher CPU utilization (i.e. the nodes with the skewed keys)
- For short queries, defined as having runtime less than 5 secs for the run without using the new multithreading model, the runtime improvements were less pronounced. This is mainly because the time spent in other steps during execution (e.g. planning, profile aggregation) tend to dominate more in short-running queries. We are working to improve efficiency in those other areas as well, with IMPALA-9378 as an example.
- Conversely, for longer queries, the runtime improvements were more pronounced.
- Keep in mind Impala previously ran some parts of the query execution such as data scanning, file I/O, the build side of a join, and certain pipelined query fragments in a multithreaded manner. Therefore some queries, particularly those bottlenecked on scan performance, were already highly parallelized and have less room for improvement in the new multithreading model.
- And yes recently Apache Impala added support for SQL features that enabled it to run all 99 TPC-DS queries.
👀 some awesome new SQL features landing in master ahead of Apache Impala 4.0 – INTERSECT, EXCEPT, ROLLUP, CUBE, GROUPING SETS, more subquery support.
— Apache Impala (@ApacheImpala) July 31, 2020
Discussion on the impact of this feature
This new multithreading model will provide the biggest benefit in the following scenarios:
- Workloads with a limited number of queries running concurrently – because most aspects of query execution were previously single threaded, under low concurrency it was hard to achieve high CPU utilization rates. Once most of the query execution path is multithreaded that same low concurrency workload will be able to take advantage of more CPU cores.
- High-CPU clusters – with compute nodes that are very dense with CPU cores (e.g. 48 cores), it becomes hard to achieve high CPU utilization, even with higher levels of concurrency. This lets Impala take full advantage of that high core count, regardless of the scenario.
- Compute-bound workloads – for queries that are bottlenecked on compute, unless CPU utilization is always maxed out, they will run faster with this new multithreading model.
On the flipside, one area where you can expect to see less improvement is in scan-intensive queries, such as searching string columns with the LIKE operator or performing a regexp_extract. Because scans were already multithreaded, there are not as many more CPU utilization gains to be had.
This optimization becomes even more important when running Impala in the cloud context, where the compute cluster can automatically start and stop itself, or grow and shrink. When your workload runs faster…
- the sooner the auto-suspending DW can shut down, the less you pay for it
- the sooner the auto-scaling DW can scale down, the less you pay because it uses fewer compute resources
Furthermore, if you can utilize a greater number of the available cores for a given workload, you might be able to use a smaller number of compute nodes. This reduces the overall costs.
Finally, given the ease of provisioning Impala clusters in the cloud – which is important for workload isolation and self-service agility – it is common to see a larger number of clusters dedicated to a single workload which are likely to not be fully utilized at the CPU level. This optimization ensures that even in this scenario the workload can achieve high levels of utilization.
Summary and call to action
To recap… Impala now has the ability to multithread some of the most heavyweight operations in analytic query use cases – namely the joins and aggregations. And we have done this without sacrificing the ability to use open source file formats and without requiring colocated storage. This will result in much higher CPU utilization, faster query times, and lower cloud costs.
You can try this out yourself via Cloudera’s CDP trial experience.
Go to the Cloudera engineering blog to learn more about Impala’s performance and architecture.
Acknowledgment
Special thanks goes out to the many people who built this new multithreading model. Tim Armstrong, Joe McDonnell, Bikramjeet Vig, David Rorke, and Kurt Deschler worked on the most recent phases of the project. Other Impala committers and contributors who did foundational work for scalability and multithreading include Marcel Kornacker and Alex Behm.
Appendix
TPC-H Query 11
# Q11 - Important Stock Identification select * from ( select ps_partkey, sum(ps_supplycost * ps_availqty) as value from tpch.partsupp, tpch.supplier, tpch.nation where ps_suppkey = s_suppkey and s_nationkey = n_nationkey and n_name = 'GERMANY' group by ps_partkey ) as inner_query where value > ( select sum(ps_supplycost * ps_availqty) * 0.0001 from tpch.partsupp, tpch.supplier, tpch.nation where ps_suppkey = s_suppkey and s_nationkey = n_nationkey and n_name = 'GERMANY' ) order by value desc |
Editor's Choice


Thank you so much for this article. It was well written. I enjoyed reading your blog.
This is a very helpful site for anyone, each and every man can easily operate this site and can get benefits