

Introduction
In database systems one of the most effective ways to improve performance is to avoid doing unnecessary work, such as network transfers and reading data from disk. One of the ways Apache Kudu achieves this is by supporting column predicates with scanners. Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. See the documentation on runtime filtering in Impala for details.
CDP Runtime 7.1.5 and CDP Public Cloud added support for Bloom filter column predicate pushdown in Kudu and the associated integration in Impala.
Bloom filter
A Bloom filter is a space-efficient probabilistic data structure used to test set membership with a possibility of false-positive matches. In database systems, these are used to determine whether a set of data can be ignored when only a subset of the records are required. See the wikipedia page for more details.
The implementation used in Kudu is a space, hash, and cache efficient block-based Bloom filter from “Cache-, Hash- and Space-Efficient Bloom Filters” by Putze et al. This Bloom filter was taken from the implementation in Impala and further enhanced. The block-based Bloom filter is designed to fit in CPU cache, and it allows SIMD operations using AVX2, when available, for efficient lookup and insertion.
Consider the case of a broadcast hash join between a small table and a big table where predicate pushdown is not available. This typically involves the following steps:
- Read the entire small table and construct a hash table from it.
- Broadcast the generated hash table to all worker nodes.
- On the worker nodes start fetching and iterating on slices of the big table, check whether the key in the big table exists in the hash table, and only return the matched rows.
Step 3 is the heaviest since it involves reading the entire big table and could involve heavy network IO if the worker and the nodes hosting the big table are not on the same server.
Before 7.1.5, Impala supported pushing down only the Minimum/Maximum (MIN_MAX) runtime filter to Kudu which filters out values not within the specified bounds. In addition to the MIN_MAX runtime filter, Impala in CDP 7.1.5+ now supports pushing down a runtime Bloom filter to Kudu. With the newly introduced Bloom filter predicate support in Kudu, Impala can use this feature to perform drastically more efficient joins for data stored in Kudu.
Performance
As in the scenario described above, we ran an Impala query that joins a big table stored on Kudu and a small table stored as Parquet on HDFS. The small table was created using Parquet on HDFS to isolate the new feature, but could also be stored in Kudu just the same. We ran the queries first using only the MIN_MAX filter and then using both the MIN_MAX and BLOOM filter (ALL runtime filters). For comparison, we created the same big table in Parquet on HDFS. Using Parquet on HDFS is a great baseline for comparison because Impala already supports both MIN_MAX and BLOOM filters for Parquet on HDFS.
Setup
The following test was performed on a 6 node cluster with CDP Runtime 7.1.5.
Hardware Configuration:
Dell PowerEdge R430, 20c/40t Xeon e5-2630 v4 @ 2.2Ghz, 128GB Ram, 4-2TB disks 1 for WAL and 3 for data directories.
Schema:
- Big table consists of 260 million rows with randomly generated data hash partitioned by primary key across 20 partitions on Kudu. The Kudu table was explicitly rebalanced to ensure a balanced layout after the load.
- Small table consists of 2000 rows of top 1000 and bottom 1000 keys from the big table stored as Parquet on HDFS. This prevents the MIN_MAX filters from doing any filtering on the big table as all rows would fall under the range bounds of the MIN_MAX filters.
- COMPUTE STATS were run on all tables to help gather information about the table metadata and help Impala optimize the query plan.
- All queries were run 10 times and the mean query runtime is depicted below.
Join Queries
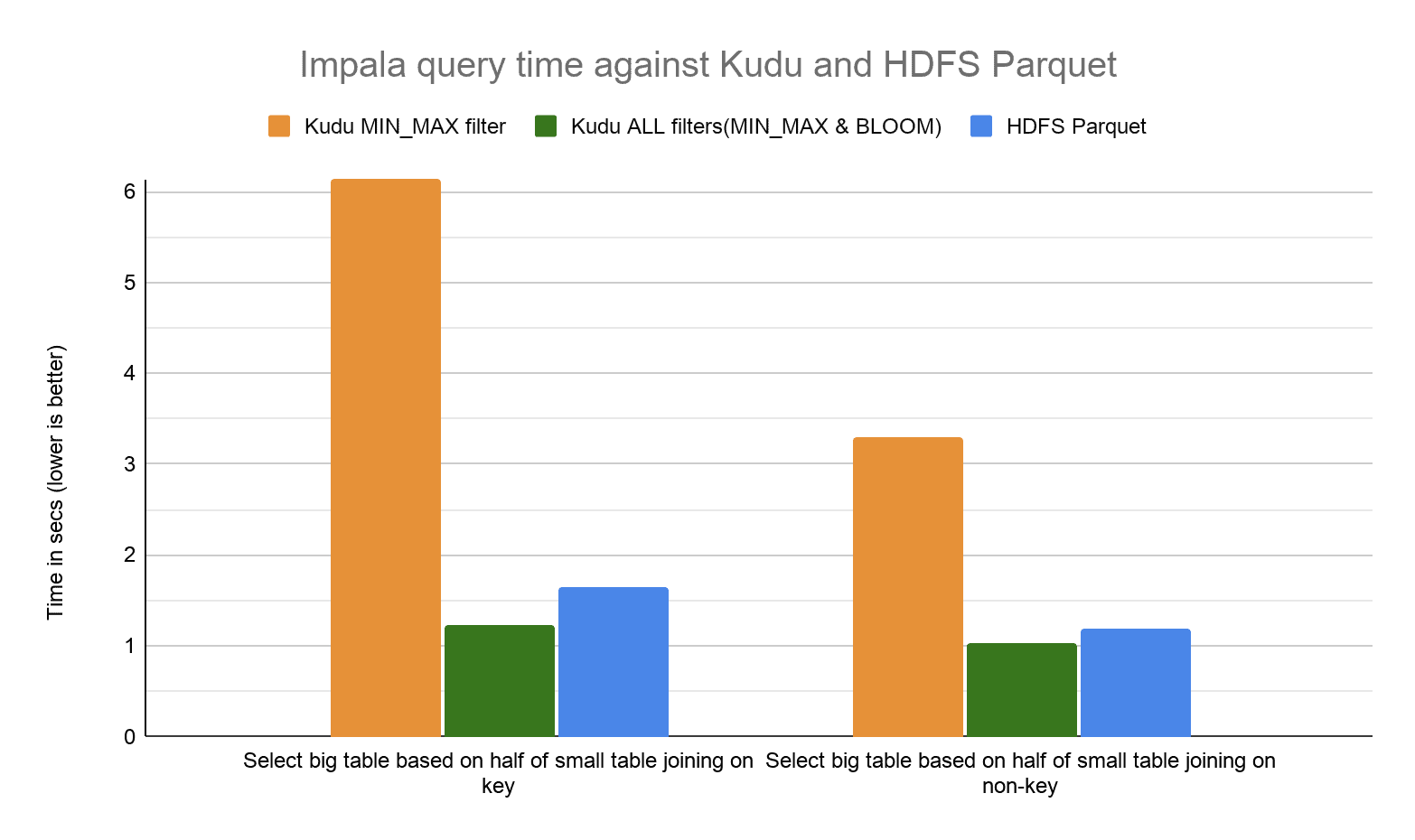
For join queries, we saw performance improvements of 3X to 5X in Kudu with Bloom filter predicate pushdown. We expect to see even better performance multiples with larger data sizes and more selective queries.
Compared to Parquet on HDFS, Kudu performance is now better by around 17-33%.
Update Query
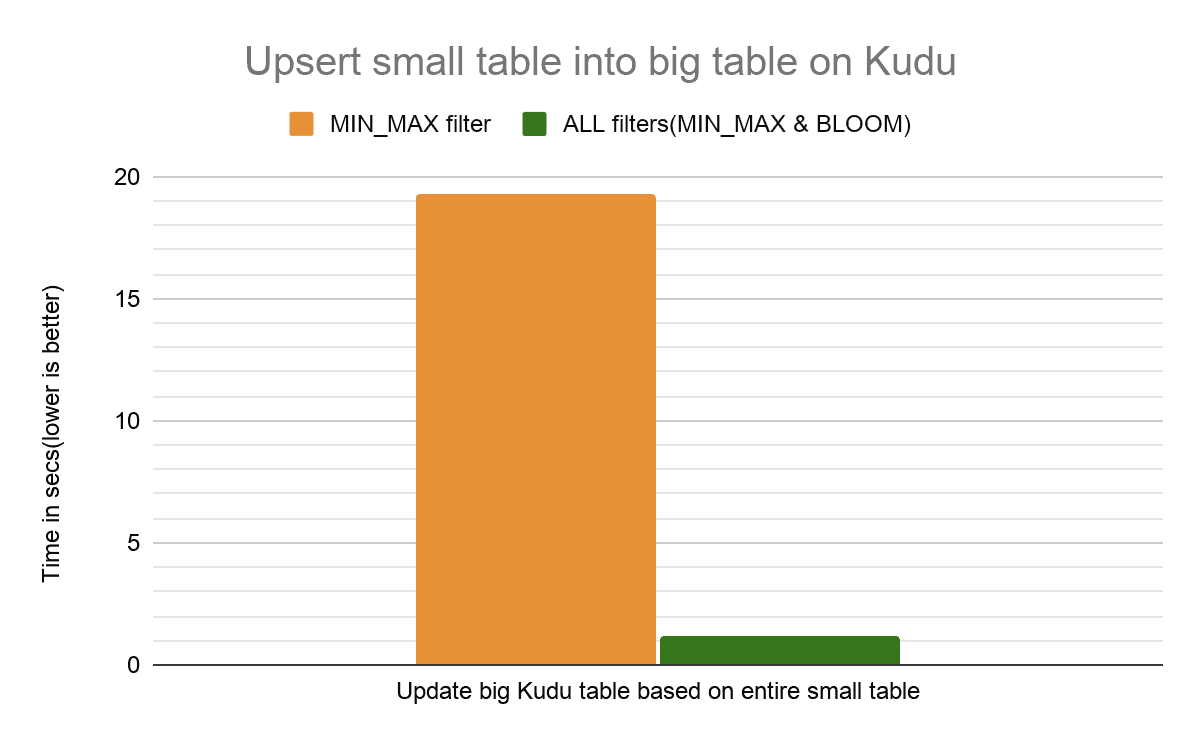
For an update query that basically upserts the entire small table into the existing big table, we saw 15X improvement. This is primarily due to the increased query performance when selecting the rows to update.
See the references section below for details on the table schema, loading process, and queries that were run.
TPC-H
We also ran the TPC-H benchmark on a single node cluster with a scale factor of 30 and saw performance improvements in the range of 19% to 31% with different block cache capacity settings.
Kudu automatically disables Bloom filter predicates that are not effectively filtering data to avoid any performance penalties from the new feature. During the development of the feature, query 9 in the TPCH benchmark (TPCH-Q9) exhibited regression of 50-96%. On further investigation, the time required to scan the rows from Kudu increased by up to 2X. When investigating this regression we found that the Bloom filter predicate that was pushed down was filtering out less than 10% of the rows, leading to increased CPU usage in Kudu which outweighed the benefit of the filter. To resolve the regression we added a heuristic in Kudu wherein if a Bloom filter predicate is not filtering out a sufficient percentage of rows then it’s disabled automatically for the remainder of the scan. This is safe because Bloom filters can return false positives and hence false matches returned to the client are expected to be filtered out using other deterministic filters.
Feature Availability
Users querying Kudu using Impala will have the feature enabled by default from CDP 7.1.5 onward and CDP Public Cloud. We highly recommend users upgrade to get this performance enhancement and many other performance enhancements in the release. For custom applications that use the Kudu client API directly, the Kudu C++ client also has the Bloom filter predicate available from CDP 7.1.5 onward. The Kudu Java client does not have the Bloom filter predicate available yet, KUDU-3221.
References:
- Performance testing related schema and queries: https://gist.github.com/bbhavsar/006df9c40b4b0528e297fac29824ceb4
- Kudu C++ client documentation: https://kudu.apache.org/cpp-client-api/classkudu_1_1client_1_1KuduTable.html#a356e8d0d10491d4d8540adefac86be94
- Example code to create and pass Bloom filter predicate: https://github.com/apache/kudu/blob/master/src/kudu/client/predicate-test.cc#L1416
- Block-based Bloom filter: https://github.com/apache/kudu/blob/master/src/kudu/util/block_bloom_filter.h#L51
Acknowledgment
This feature was implemented jointly by Bankim Bhavsar and Wenzhe Zhou with guidance and feedback from Tim Armstrong, Adar Dembo, Thomas Tauber-Marshall, Andrew Wong, and Grant Henke. We are also grateful for our customers especially Mauricio Aristizabal from Impact for providing us valuable feedback and benchmarks.
Editor's Choice

