


A key part of business is the drive for continual improvement, to always do better. “Better” can mean different things to different organizations. It could be about offering better products, better services, or the same product or service for a better price or any number of things. Fundamentally, to be “better” requires ongoing analysis of the current state and comparison to the previous or next one. It sounds straightforward: you just need data and the means to analyze it. Right?
Yes and no. The data is there, in spades. Data volumes have been growing for years and are predicted to reach 175 ZB by 2025. Yet there are two things blocking success. First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. What previously was nicely defined and structured data in a few fully owned and controlled places, like a data center, is now churning torrents of data of all shapes and sizes spread across edge and cloud environments. Organizations don’t know what they have anymore and so can’t fully capitalize on it—the majority of data generated goes unused in decision making. And second, for the data that is used, 80% is semi- or unstructured. Combining and analyzing both structured and unstructured data is a whole new challenge to come to grips with, let alone doing so across different infrastructures. Both obstacles can be overcome using modern data architectures, specifically data fabric and data lakehouse. Each is powerful in their own right, but used together they drive synergies that create more options to be “better.”
Unified data fabric
For many organizations, a data fabric is a first step to becoming more data driven. A data fabric answers perhaps the biggest question of all: what data do we have to work with? Managing and making individual data sources available through traditional enterprise data integration, and when end users request them, simply does not scale—especially in light of a growing number of sources and volume. The tremendous overhead placed on IT hampers the speed with which organizations can bring together ever more data to deploy new use cases. What’s more, data users are forever plagued by the feeling that more data, perhaps better data, is out there somewhere, which causes teams to second-guess results or resort to the use of unsanctioned sources, which creates compliance risks.
A data fabric flips the traditional “as needed” enterprise data integration approach, with data fabric teams able to integrate all data sources in a fully controlled way, understand them, and make them available via self-service.
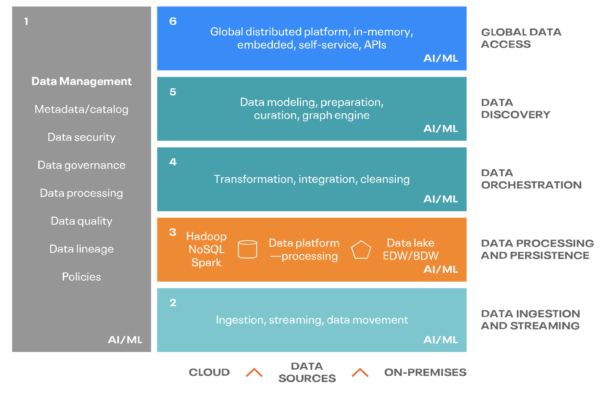
With solid data management across the whole process, a data fabric ingests any and all data sources regardless of variety or velocity. The data sources can then be processed and stored as well as integrated and cleaned to uncover what they represent and makes the data sources available to users, where needed, in a safe and compliant manner.
It won’t surprise you that all of Cloudera Data Platform’s (CDP) capabilities come to bear when companies deploy a data fabric architecture; our customers have been creating data fabrics before it was even named. Where CDP really shines, and what makes for a truly unified data fabric, is via the Shared Data Experience (SDX). SDX provides a comprehensive approach to data security and governance with powerful fine-grained access control triggered by data classifications uncovered through automated data discovery. This makes it possible to open up data access to more users, even for previously unknown data sources. And it does so—here’s the kicker!—not just in one infrastructure but across all infrastructures: hybrid and multi-cloud. Consistent data security and governance across all fabrics. Through a single pane of glass, SDX’s Data Catalog provides self-service data access to end users, letting them find the data they need, appreciate the context, and give them the confidence they’ve found all the data they need.
Open data lakehouse
Once you have the access to all the data you need at the right time, the next step is to be able to use the data efficiently, opening the door for new analytic use cases. This is where the data lakehouse comes in. More and more organizations are realizing that it is the most efficient and performant architecture for running multi-function analytics because it makes all their data more usable and effective. Companies need answers to more complex business questions that require integration of unstructured data, real time data with use of modern, best-of-breed engines for analytics, stream processing, and for AI and ML for predictive analytics. These answers must be reliable and delivered quickly. If data has to be transformed to proprietary formats and moved around for each of the compute engines you want to use, it would result in data silos, stale data, and delayed insights. A data lakehouse that enables multiple engines to run on the same data improves speed to market and productivity of users.
Cloudera has supported data lakehouses for over five years. We have delivered the performance and reliability of the data warehouse with the flexibility and scale of a data lake with our data service engines and the Hive metastore. With the integration of Apache Iceberg—an open standard, open source based table format in SDX—Cloudera is taking the data lakehouse to the next level by creating an open data lakehouse. Applying the Iceberg table format to all the organization’s data in the data lake makes it more performant and usable at scale. An open data lakehouse, powered by Iceberg, makes the organization’s data agnostic to processing engines, providing greater flexibility and choice. It simplifies data management at scale and adds superpowers like time travel, snapshot isolation, and partition evolution to the traditional data lakehouse.
Better together
Organizations need the two data architectures working together in harmony to drive value and insight from ever more data, faster. A data fabric combined with a data lakehouse is the ideal foundation for most organizations. This combo allows companies to orchestrate their data and optimize getting value and insight from it. However, both architectures must be deployed based on the same platform and support hybrid cloud for organizations to achieve maximum value from their investment. That’s what companies get with CDP’s unified data fabric powered by SDX, an open data lakehouse made possible by integration with Apache Iceberg. Cloudera Data Platform is a single hybrid platform for modern data architectures with data anywhere.
For example, a multinational health information technology and clinical research organization realized the challenges they themselves experienced were shared by their customers. They not only combined and deployed both architectures for their own use, but also made them an integral part of the products they provide. Both the organization as well as their customers can now unlock data sources in a safe and compliant manner, as well as drive insight faster from both structured and unstructured data. Their healthcare PaaS effectively combines both data fabric and data lakehouse capabilities, leading to higher productivity for research and development teams while also ensuring HIPAA and PII compliance. What’s more, both the organization and their customers benefit from lower TCO for service delivery.
This is the value companies get with CDP’s unified data fabric powered by SDX and an open data lakehouse made possible by integration with Apache Iceberg. Cloudera Data Platform is a single hybrid platform for modern data architectures with data anywhere.
To find out more on how CDP unleashes the potential of your data with modern data architectures, check out Cloudera Now.
Editor's Choice

