


Cloudera customers run some of the biggest data lakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake. In a rush to own this term, many vendors have lost sight of the fact that the openness of a data architecture is what guarantees its durability and longevity.
On data warehouses and data lakes
Data lakes and data warehouses unify large volumes and varieties of data into a central location. But with vastly different architectural worldviews. Warehouses are vertically integrated for SQL Analytics, whereas Lakes prioritize flexibility of analytic methods beyond SQL.
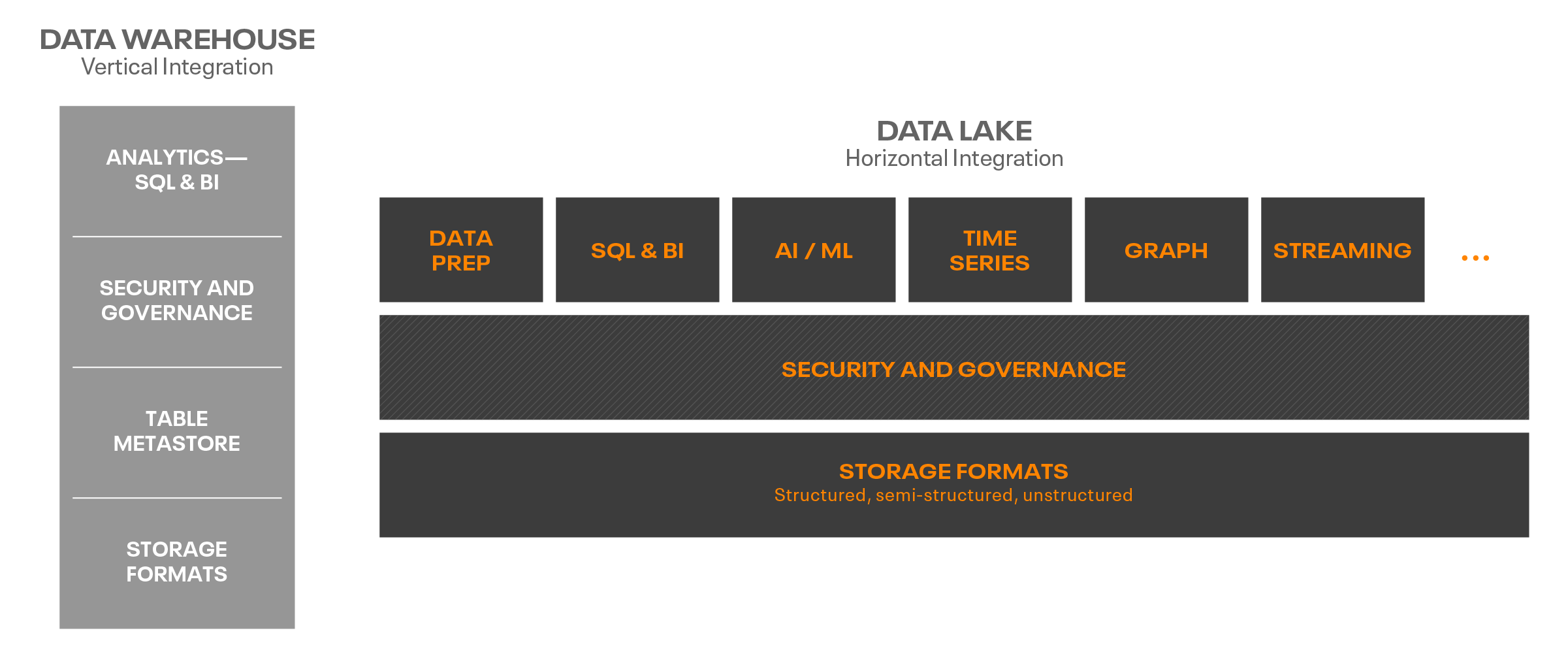
In order to realize the benefits of both worlds—flexibility of analytics in data lakes, and simple and fast SQL in data warehouses—companies often deployed data lakes to complement their data warehouses, with the data lake feeding a data warehouse system as the last step of an extract, transform, load (ETL) or ELT pipeline. In doing so, they’ve accepted the resulting lock-in of their data in warehouses.
But there was a better way: enter the Hive Metastore, one of the sleeper hits of the data platform of the last decade. As use cases matured, we saw the need for both efficient, interactive BI analytics and transactional semantics to modify data.
Iterations of the lakehouse
The first generation of the Hive Metastore attempted to address the performance considerations to run SQL efficiently on a data lake. It provided the concept of a database, schemas, and tables for describing the structure of a data lake in a way that let BI tools traverse the data efficiently. It added metadata that described the logical and physical layout of the data, enabling cost-based optimizers, dynamic partition pruning, and a number of key performance improvements targeted at SQL analytics.
The second generation of the Hive Metastore added support for transactional updates with Hive ACID. The lakehouse, while not yet named, was very much thriving. Transactions enabled the use cases of continuous ingest and inserts/updates/deletes (or MERGE), which opened up data warehouse style querying, capabilities, and migrations from other warehousing systems to data lakes. This was enormously valuable for many of our customers.
Projects like Delta Lake took a different approach at solving this problem. Delta Lake added transaction support to the data in a lake. This allowed data curation and brought the possibility to run data warehouse-style analytics to the data lake.
Somewhere along this timeline, the name “data lakehouse” was coined for this architecture pattern. We believe lakehouses are a great way to succinctly define this pattern and have gained mindshare very quickly among customers and the industry.
What have customers been telling us?
In the last few years, as new data types are born and newer data processing engines have emerged to simplify analytics, companies have come to expect that the best of both worlds truly does require analytic engine flexibility. If large and valuable data for the enterprise is managed, then there has to be openness for the business to choose different analytic engines, or even vendors.
The lakehouse pattern, as implemented, had a critical contradiction at heart: while lakes were open, lakehouses were not.
The Hive metastore followed a Hive-first evolution, before adding engines like Impala, Spark, among others. Delta lake had a Spark-heavy evolution; customer options dwindle rapidly if they need freedom to choose a different engine than what is primary to the table format.
Customers demanded more from the start. More formats, more engines, more interoperability. Today, the Hive metastore is used from multiple engines and with multiple storage options. Hive and Spark of course, but also Presto, Impala, and many more. The Hive metastore evolved organically to support these use cases, so integration was often complex and error prone.
An open data lakehouse designed with this need for interoperability addresses this architectural problem at its core. It will make those who are “all in” on one platform uncomfortable, but community-driven innovation is about solving real-world problems in pragmatic ways with best-of-breed tools, and overcoming vendor lock-in whether they approve or not.
An open lakehouse, and the birth of Apache Iceberg
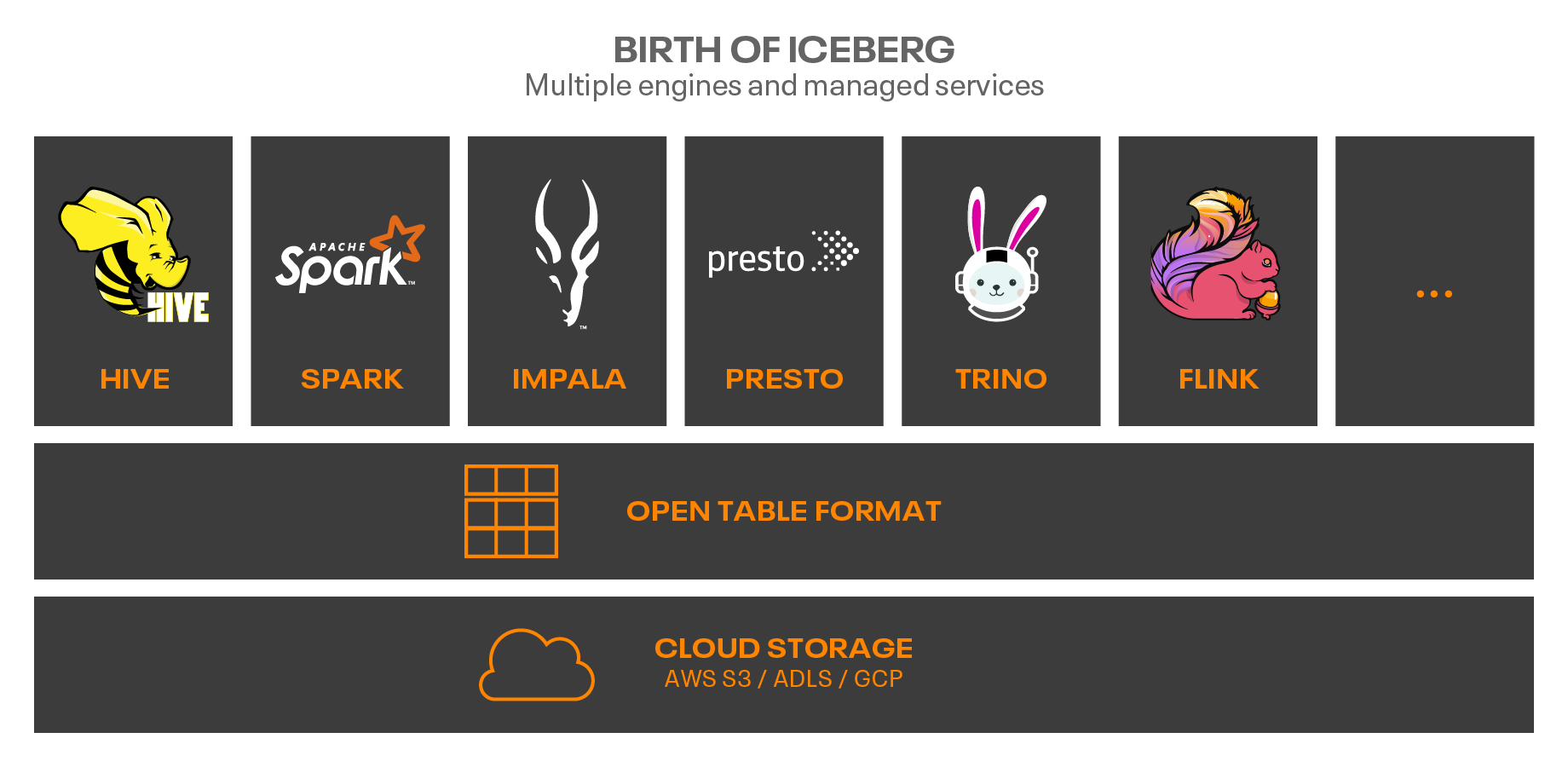
Apache Iceberg was built from inception with the goal to be easily interoperable across multiple analytic engines and at a cloud-native scale. Netflix, where this innovation was born, is perhaps the best example of a 100 PB scale S3 data lake that needed to be built into a data warehouse. The cloud native table format was open sourced into Apache Iceberg by its creators.
Apache Iceberg’s real superpower is its community. Organically, over the last three years, Apache Iceberg has added an impressive roster of first-class integrations with a thriving community:
- Data processing and SQL engines Hive, Impala, Spark, PrestoDB, Trino, Flink
- Multiple file formats: Parquet, AVRO, ORC
- Large adopters in the community: Apple, LinkedIn, Adobe, Netflix, Expedia and others
- Managed services with AWS Athena, Cloudera, EMR, Snowflake, Tencent, Alibaba, Dremio, Starburst
What makes this varied community thrive is the collective need of thousands of companies to ensure that data lakes can evolve to subsume data warehouses, while preserving analytic flexibility and openness across engines. This enables an open lakehouse: one that offers unlimited analytic flexibility for the future.
How are we embracing Iceberg?
At Cloudera, we are proud of our open-source roots and committed to enriching the community. Since 2021, we have contributed to the growing Iceberg community with hundreds of contributions across Impala, Hive, Spark, and Iceberg. We extended the Hive Metastore and added integrations to our many open-source engines to leverage Iceberg tables. In early 2022, we enabled a Technical Preview of Apache Iceberg in Cloudera Data Platform allowing Cloudera customers to realize the value of Iceberg’s schema evolution and time travel capabilities in our Data Warehousing, Data Engineering and Machine Learning services.
Our customers have consistently told us that analytic needs evolve rapidly, whether it is modern BI, AI/ML, data science, or more. Choosing an open data lakehouse powered by Apache Iceberg gives companies the freedom of choice for analytics.
If you want to learn more, join us on June 21 on our webinar with Ryan Blue, co-creator of Apache Iceberg and Anjali Norwood, Big Data Compute Lead at Netflix.
Editor's Choice

