




Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists. This unprecedented level of big data workloads hasn’t come without its fair share of challenges. The data architecture layer is one such area where growing datasets have pushed the limits of scalability and performance. The data explosion has to be met with new solutions, that’s why we are excited to introduce the next generation table format for large scale analytic datasets within Cloudera Data Platform (CDP) – Apache Iceberg. Today, we are announcing a private technical preview (TP) release of Iceberg for CDP Data Services in the public cloud, including Cloudera Data Warehousing (CDW) and Cloudera Data Engineering (CDE).
Apache Iceberg is a new open table format targeted for petabyte-scale analytic datasets. It has been designed and developed as an open community standard to ensure compatibility across languages and implementations. Apache Iceberg is open source, and is developed through the Apache Software Foundation. Companies such as Adobe, Expedia, LinkedIn, Tencent, and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets.
To satisfy multi-function analytics over large datasets with the flexibility offered by hybrid and multi-cloud deployments, we integrated Apache Iceberg with CDP to provide a unique solution that future-proofs the data architecture for our customers. By optimizing the various CDP Data Services, including CDW, CDE, and Cloudera Machine Learning (CML) with Iceberg, Cloudera customers can define and manipulate datasets with SQL commands, build complex data pipelines using features like Time Travel operations, and deploy machine learning models built from Iceberg tables. Along with CDP’s enterprise features such as Shared Data Experience (SDX), unified management and deployment across hybrid cloud and multi-cloud, customers can benefit from Cloudera’s contribution to Apache Iceberg, the next generation table format for large scale analytic datasets.
Key Design Goals
As we set out to integrate Apache Iceberg with CDP, we not only wanted to incorporate the advantages of the new table format but also expand its capabilities to meet the needs of modernizing enterprises, including security and multi-function analytics. That’s why we set the following innovation goals that will increase scalability, performance and ease of use of large scale datasets across a multi-function analytics platform:
- Multi-function analytics: Iceberg is designed to be open and engine agnostic allowing datasets to be shared. Through our contributions, we have extended support for Hive and Impala, delivering on the vision of a data architecture for multi-function analytics from large scale data engineering (DE) workloads to fast BI and querying (within DW) and machine learning (ML).
- Fast query planning: Query planning is the process of finding the files in a table that are needed for a SQL query. In Iceberg, instead of listing O(n) partitions (directory listing at runtime) in a table for query planning, Iceberg performs an O(1) RPC to read the snapshot. Fast query planning enables lower latency SQL queries and increases overall query performance.
- Unified security: Integration of Iceberg with a unified security layer is paramount for any enterprise customer. That is why from day one we ensured the same security and governance of SDX apply to Iceberg tables.
- Separation of physical and logical layout: Iceberg supports hidden partitioning. Users do not need to know how the table is partitioned to optimize the SQL query performance. Iceberg tables can evolve partition schemas over time as data volume changes. No costly table rewrites are required and in many cases the queries need not be rewritten either.
- Efficient metadata management: Unlike Hive Metastore (HMS), which needs to track all Hive table partitions (partition key-value pairs, data location and other metadata), the Iceberg partitions store the data in the Iceberg metadata files on the file system. It removes the load from the Metastore and Metastore backend database.
In the subsequent sections, we will take a closer look at how we are integrating Apache Iceberg within CDP to address these key challenges in the areas of performance and ease of use. We will also talk about what you can expect from the TP release as well as unique capabilities customers can benefit from.
Apache Iceberg in CDP : Our Approach
Iceberg provides a well defined open table format which can be plugged into many different platforms. It includes a catalog that supports atomic changes to snapshots – this is required to ensure that we know changes to an Iceberg table either succeeded or failed. In addition, the File I/O implementation provides a way to read / write / delete files – this is required to access the data and metadata files with a well defined API.
These characteristics and their pre-existing implementations made it quite straightforward to integrate Iceberg into CDP. In CDP we enable Iceberg tables side-by-side with the Hive table types, both of which are part of our SDX metadata and security framework. By leveraging SDX and its native metastore, a small footprint of catalog information is registered to identify the Iceberg tables, and by keeping the interaction lightweight allows scaling to large tables without incurring the usual overhead of metadata storage and querying.
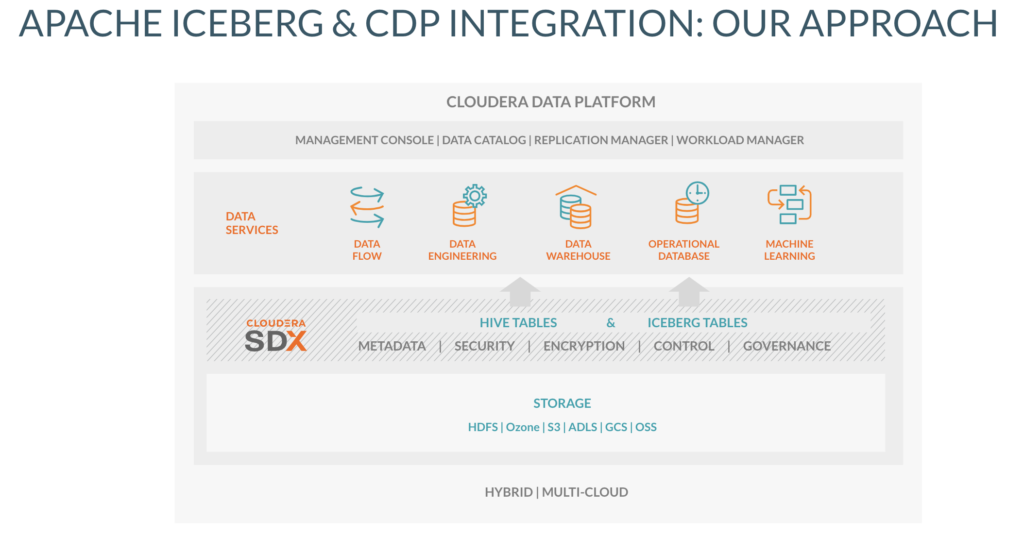
Multi-function analytics
After the Iceberg tables become available in SDX, the next step is to enable the execution engines to leverage the new tables. The Apache Iceberg community has a sizable contribution pool of seasoned Spark developers who integrated the execution engine. On the other hand, Hive and Impala integration with Iceberg was lacking so Cloudera contributed this work back into the community.
During the last few months we have made good progress on enabling Hive writes (above the already available Hive reads) and both Impala reads and writes. Using Iceberg tables, the data could be partitioned more aggressively. As an example, with the repartitioning one of our customers found that Iceberg tables perform 10x times better than the previously used Hive external tables using Impala queries. Previously this aggressive partitioning strategy was not possible with Metastore tables because the high number of partitions would make the compilation of any query against these tables prohibitively slow. A perfect example of why Iceberg shines at such large scales.
Unified Security
Integrating Iceberg tables into SDX has the added benefit of the Ranger integration which you get out of the box. Administrators can leverage Ranger’s ability to restrict full tables / columns / rows for specific groups of users. They can mask the column and the values can be redacted / nullified / hashed in both Hive and Impala. CDP provides unique capabilities for Iceberg table fine grained access control to satisfy enterprise customers requirements for security and governance.
External Table Conversion
In order to continue using your existing ORC, Parquet and Avro datasets stored in external tables, we integrated and enhanced the existing support for migrating these tables to the Iceberg table format by adding support for Hive on top of what is there today for Spark. The table migration will leave all the data files in place, without creating any copies, only generating the necessary Iceberg metadata files for them and publishing them in a single commit. Once the migration has completed successfully, all your subsequent reads and writes for the table will go through Iceberg and your table changes will start generating new commits.
What’s Next
First we will focus on additional performance testing to check for and remove any bottlenecks we identify. This will be across all the CDP Data Services starting with CDE and CDW. As we move towards GA, we will target specific workload patterns such as Spark ETL/ELT and Impala BI SQL analytics using Apache Iceberg.
Beyond the initial GA release, we will expand support for other workload patterns to realize the vision we layed out earlier of multi-function analytics on this new data architecture. That’s why we are keen on enhancing the integration of Apache Iceberg with CDP along the following capabilities:
- ACID support – Iceberg v2 format was released with Iceberg 0.12 in August 2021 laying the foundation for ACID. To utilize the new features such as row level deletes provided by the new version, further enhancements are needed in Hive and Impala integration. With these new integrations in place, Hive and Spark will be able to run UPDATE, DELETE, and MERGE statements on Iceberg v2 tables, and Impala will be able to read them.
- Table replication – A key feature for enterprise customers’ requirements for disaster recovery and performance reasons. Iceberg tables are geared toward easy replication, but integration still needs to be done with the CDP Replication Manager to make the user experience seamless.
- Table management – By avoiding file listings and the associated costs, Iceberg tables are able to store longer history than Hive ACID tables. We will be enabling automatic snapshot management and compaction to further increase the performance of the queries above Iceberg tables by keeping only the relevant snapshots and restructuring the data to a query-optimized format.
- Time Travel – There are additional time travel features we are considering , such as querying change sets (deltas) between two points in time (potentially using keywords such as between or since). The exact syntax and semantics of these queries are still under design and development.
Ready to try?
If you are running into challenges with your large datasets, or want to take advantage of the latest innovations in managing datasets through snapshots and time-travel we highly recommend you try out CDP and see for yourself the benefits of Apache Iceberg within a mult-cloud, multi-function analytics platform. Please contact your account team if you are interested in learning more about Apache Iceberg integration with CDP.
To try out CDW and CDE, please sign up for a 60 day trial, or test drive CDP. As always, please provide your feedback in the comments section below.
Editor's Choice

