

Cloudera Contributor: Mark Ramsey, PhD ~ Globally Recognized Chief Data Officer
July brings summer vacations, holiday gatherings, and for the first time in two years, the return of the Massachusetts Institute of Technology (MIT) Chief Data Officer symposium as an in-person event. The gathering in 2022 marked the sixteenth year for top data and analytics professionals to come to the MIT campus to explore current and future trends. A key area of focus for the symposium this year was the design and deployment of modern data platforms. Modern data platforms deliver an elastic, flexible, and cost-effective environment for analytic applications by leveraging a hybrid, multi-cloud architecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. While all of this may sound like a marketing mouthful, there are some genuinely interesting new concepts here. I spoke to Mark Ramsey of Ramsey International to unpack what this all means and how it can help teams create an architecture that delivers business use cases faster. Here’s what I learned while talking with the top chief data officers from around the world about creating an architecture to deliver not just one, but multiple, business use cases faster.
- Luke: What is a modern data platform?
- Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. The high-level architecture shown below forms the backdrop for the exploration. The collection of source data shown on your left is composed of both structured and unstructured data from the organization’s internal and external sources. One of the tenets of a modern data platform is a focus on the entire source data landscape versus the traditional approach of limiting to project-level requirements.
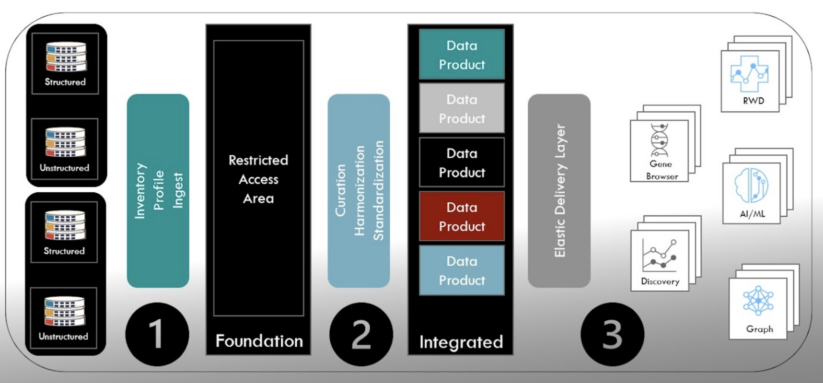
Ramsey International Modern Data Platform Architecture
- Luke: That’s a good high-level overview, can you break it down a little bit more? What are the steps or elements that companies need to think about?
- Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source data lake. In a modern data platform, this step involves key source data activities, including inventory, profiling, acquisition, and ingestion. For advanced organizations, this step will inventory, profile, and ingest all of the source data into the foundation, and not be limited to a project-by-project approach.
- The second element is the link between the raw source data in the foundation layer, and the data products that are delivered in what RI defines as the “integrated layer.” The data products are packaged around the business needs and in support of the business use cases. This step requires curation, harmonization, and standardization from the raw data into the products
- The third element in the process is the connection between the data products and the collection of analytics applications to provide business results. The consumption of the data should be supported through an elastic delivery layer that aligns with demand, but also provides the flexibility to present the data in a physical format that aligns with the analytic application, ranging from the more traditional data warehouse view to a graph view in support of relationship analysis.
- Luke: Let’s talk about some of the fundamentals of modern data architecture. What is a data fabric?
- Mark: Gartner states that a data fabric “enables frictionless access and sharing of data in a distributed data environment.” NetApp provides a more robust definition of data fabric as “an architecture and set of data services that provide consistent capabilities across hybrid, multi-cloud environments.” The data fabric provides direct support for the first element of the architecture—linking the distributed source data into the hybrid, multi-cloud environment.
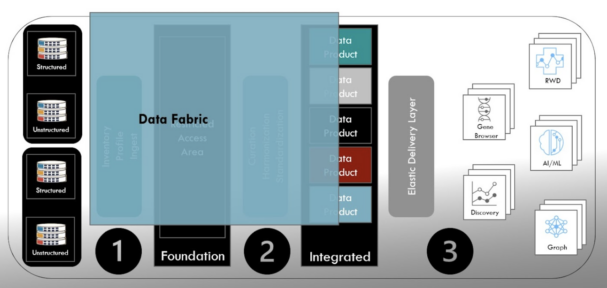
Ramsey International Modern Data Platform Architecture
- Luke: In your experience, what’s the most practical definition of data fabric for companies thinking about implementing it?
- Mark: While definitions vary slightly, the idea is a flexible “fabric” versus a ridgid collection of disparate tools to ease data sharing and governance. As shown above, the data fabric provides the data services from the source data through to the delivery of data products, aligning well with the first and second elements of the modern data platform architecture. Foundational to the data fabric are metadata driven pipelines for scalability and resiliency, a unified view of the data from source through to the data products, and the ability to operate across a hybrid, multi-cloud environment.
- Luke: I’ve also talked to Cloudera customers about a new concept that there’s a lot of excitement around—data mesh. What is a data mesh? How does it compare to data fabric?
- Mark: Yes, another concept gaining traction with data leaders is the data mesh, which was introduced by Zhamak Dehghani in 2019 as an approach to address the challenges when deploying data programs. Prior to data mesh, a central curation team quickly became a bottleneck in the delivery of data. Rather than considering the packaging of data into data products to be an extension of the DataOps process, the data mesh approach focuses on leveraging decentralized teams for the creation, delivery, and ongoing support of data products. As shown below, the data mesh teams leverage the architecture and data services of the data fabric in the delivery of the data products for consumption. Organizations that attempt to implement a data mesh without a data fabric risk moving the bottleneck of their data program from the creation of data products to the acquisition and organization of the data.
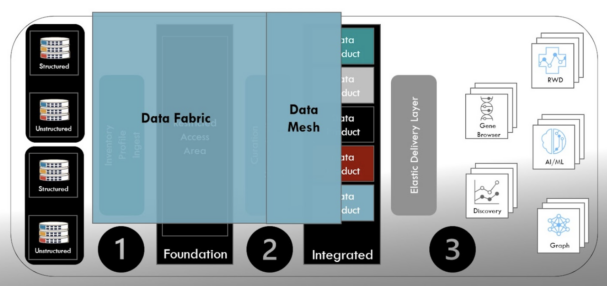
Ramsey International Modern Data Platform Architecture
The data fabric is domain agnostic, in contrast to the data mesh, in which domain knowledge and expertise is fundamental. Dash mesh accelerates the delivery of domain-specific data products by moving curation from a serial, specification driven process to a parallel, data product driven process.
- Luke: Last, but certainly not least, is the data lakehouse, which has gotten a lot of traction as a term in the last couple of years. How would you describe a data lakehouse?
- Mark: Data lakehouse came to the forefront as a component of a modern data platform in 2020 after being introduced a few years earlier. S&P Global’s Matt Aslett explains that a data lakehouse “blurs the lines between data lakes and data warehousing by maintaining the cost and flexibility advantages of persisting data in cloud storage while enabling schema to be enforced for curated subsets of data in specific conceptual zones of the data lake, or an associated analytic database, in order to accelerate analysis and business decision-making.”
As shown below, the data lakehouse is an excellent approach to allow the data products created by the data mesh to be delivered to the consumers of the data in the format that aligns with their needs.
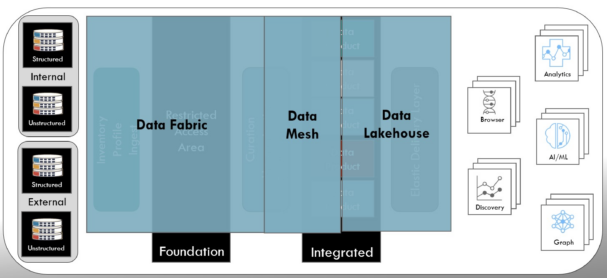
Ramsey International Modern Data Platform Architecture
The data may be in various file formats within cloud storage, but the data lakehouse delivers it as a virtual relational data warehouse for consumption. Another business consumer of the data may require the data to be delivered for a past period, such as the previous year. Accessing data over specific time periods is easily handled within the data lakehouse, and supports the need for reproducibility of analytics applications.
- Luke: How should organizations think about a data lakehouse in comparison to data fabric and data mesh? Are there things they should keep in mind?
- Mark: The data lakehouse is powerful at delivering data products that align with business use cases; however, organizations must avoid viewing the data lakehouse as the complete solution. Implementing a data lakehouse independently without also considering the data fabric and data mesh risks delivering a one-off solution that cannot scale to meet the broader needs of the organization.
- Luke: We’ve covered a lot of ground in discussing modern data architecture and where we are today. What’s a trend you see on the horizon?
- Mark: Another concept gaining ground is the idea of data observability. In June 2022, Barr Moses of Monte Carlo expanded on her initial article defining data observability. What started as a concept of monitoring the DataOps process has now evolved into visibility into a combination of data flow, data quality, data governance, and data lineage. Data observability provides insight into the condition and evolution of the data resources from source through the delivery of the data products. See below.
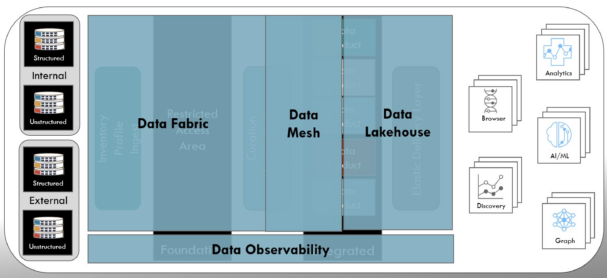
Ramsey International Modern Data Platform Architecture
The data observability five pillars are: freshness, distribution, volume, schema, and lineage. Freshness monitors the frequency of when the data resources are updated, which helps identify the most ideal data for decision making. In addition, freshness can help direct a focus toward stale data in an organization that can be pruned to reduce overall complexity. Distribution monitors the statistical characteristics of the data resource, which is an excellent linkage with data quality.
For example, having a data attribute for age that suddenly contains values of 167 or -23 can help identify areas that must be investigated. Monitoring volume provides another data quality checkpoint. Monitoring data volumes can alert in situations where a daily update suddenly goes from two million records to 200 million records can be critical. As the number of data sources continues to rise, monitoring schema allows an organization to quickly recognize when data format has changed—new data being added or removed—and has the potential to impact the data ecosystem. Finally, data lineage monitoring allows the organization to understand the life cycle of each attribute.
Having the full journey for each data resource allows rapid triage when an issue is identified with a data resource. Fundamentally, data observability is about monitoring the journey of each data attribute in the landscape; however, it also provides the ability to understand the heartbeat and reduce the complexity of the ecosystem.
- Luke: What can companies expect out of a modern data architecture? Why should this be on their technology roadmap?
- Mark: Combining data fabric, data mesh, data lakehouse, and data observability allows organizations to deliver elastic, flexible, and cost-effective environments for analytic applications by leveraging a hybrid, multi-cloud approach. In other words, these concepts help you deliver real results faster and cheaper.
To learn more about how Cloudera helps address these modern data architectures, visit https://www.cloudera.com/why-cloudera/hybrid-data-platform.html
Cloudera Contributor: Mark Ramsey, PhD ~ Globally Recognized Chief Data Officer

Mark Ramsey – PhD ~ Globally Recognized Chief Data Officer Ramsey International
Editor's Choice

