


The promise of a modern data lakehouse architecture
Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested. Imagine independently discovering rich new business insights from both structured and unstructured data working together, without having to beg for data sets to be made available. As a data analyst or data scientist, we would all love to be able to do all these things, and much more. This is the promise of the modern data lakehouse architecture.
According to Gartner, Inc. analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support AI, BI, ML, and data engineering on a single platform.” This sounds really good on paper, but how do we build this in reality, in our organizations, and meet the promise of self service across all data?
New innovations bring new challenges
Cloudera has been supporting data lakehouse use cases for many years now, using open source engines on open data and table formats, allowing for easy use of data engineering, data science, data warehousing, and machine learning on the same data, on premises, or in any cloud. New innovations in the cloud have driven data explosions. We’re asking new and more complex questions of our data to gain even greater insights. We’re bringing in new data sets in real time, from more diverse sources than ever before. These new innovations bring with them new challenges for our data management solutions. These challenges require architecture changes and adoption of new table formats that can support massive scale, offer greater flexibility of compute engine and data types, and simplify schema evolution.
- Scale: With the massive growth of new data born in the cloud comes a need to have cloud-native data formats for files and tables. These new formats need to accommodate the massive scale increases while shortening the response windows for accessing, analyzing, and using these data sets for business insights. To respond to this challenge, we need to incorporate a new, cloud-native table format that is ready for the scope and scale of our modern data.
- Flexibility: With the increased maturity and expertise around advanced analytics techniques, we demand more. We need more insights from more of our data, leveraging more data types and levels of curation. With this in mind, it’s clear that no “one size fits all” architecture will work here; we need a diverse set of data services, fit for each workload and purpose, backed by optimized compute engines and tools.
- Schema evolution: With fast-moving data and real-time data ingestion, we need new ways to keep up with data quality, consistency, accuracy, and overall integrity. Data changes in numerous ways: the shape and form of the data changes; the volume, variety, and velocity changes. As each data set transforms throughout its life cycle, we need to be able to accommodate that without burden and delay, while maintaining data performance, consistency, and trustworthiness.
An innovation in cloud-native table formats: Apache Iceberg
Apache Iceberg, a top-level Apache project, is a cloud-native table format built to take on the challenges of the modern data lakehouse. Today, Iceberg enjoys a large active open source community with solid innovation investment and significant industry adoption. Iceberg is a next-generation, cloud-native table format designed to be open and scalable to petabyte datasets. Cloudera has incorporated Apache Iceberg as a core element of the Cloudera Data Platform (CDP), and as a result is a highly active contributor.
Apache Iceberg is purpose built to tackle the challenges of today
Iceberg was born out of necessity to take on the challenges of modern analytics, and is particularly well suited to data born in the cloud. Iceberg tackles the exploding data scale, advanced methods of analyzing and reporting on data, and fast changes to data without loss of integrity through a number of innovations.
- Iceberg handles massive data born in the cloud. With innovations like hidden partitioning and metadata stored at the file level, Iceberg makes querying on very large data sets faster, while also making changes to data easier and safer.
- Iceberg is designed to support multiple analytics engines. Iceberg is open by design, and not just because it is open source. Iceberg contributors and committers are dedicated to the idea that for Iceberg to be most useful, it needs to support a wide array of compute engines and services. As a result, Iceberg supports Spark, Dremio, Presto, Impala, Hive, Flink, and more. With more choices for ways to ingest, manage, analyze, and use data, more advanced use cases can be built with greater ease. Users can select the right engine, the right skill set, and the right tools at the right time, unencumbered by any fixed engine and tool set without ever locking their data into a single vendor solution.
- Iceberg is designed to adapt to data changes quickly and efficiently. Innovations like schema and partition evolution mean changes in data structures are taken in stride. With ACID compliance on fast ingest data, Iceberg takes fast-moving data in stride without loss of integrity and accuracy in the data lakehouse.
An architectural innovation: Cloudera Data Platform (CDP) and Apache Iceberg
With Cloudera Data Platform (CDP), Iceberg is not “yet another table format” accessible by a proprietary compute engine using external tables or similar “bolt-on” approaches. CDP fully integrates Iceberg as a key table format in its architecture making data easy to access, manage, and use.
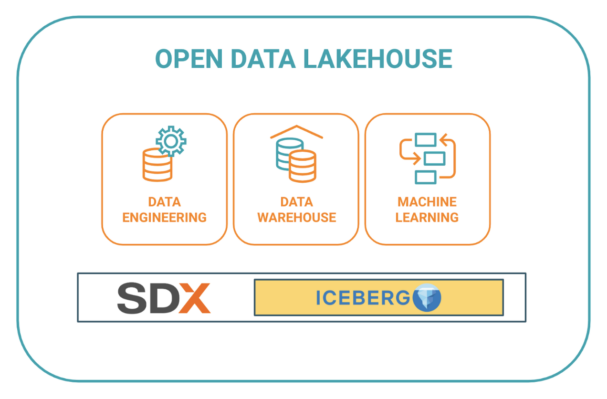
CDP includes a common metastore, and has fully integrated this metastore with Iceberg tables. This means that Iceberg-formatted data assets are fully embedded into CDP’s unique Shared Data Experience (SDX), and therefore take full advantage of this single source for security and metadata management. With SDX, CDP supports the self-service needs of data scientists, data engineers, business analysts, and machine learning professionals with fit for purpose, pre-integrated services.
Pre-integrated services sharing the same data context are key to developing modern business solutions that lead to transformative change. We’ve seen companies struggle to integrate multiple analytics solutions together from multiple vendors. Every new dimension, such as capturing a data stream, automatically tagging data for security and governance, or performing data science or AI/ML work, required moving data in and out of proprietary formats and developing custom integration points between services. CDP with Apache Iceberg brings data services together under a single roof, a single data context.
CDP uses tight compute integration with Apache Hive, Impala, and Spark, ensuring optimal read and write performance. And unlike other solutions that are compatible with Apache Iceberg tables and can read them and perform analytics on them, Cloudera has made Iceberg an integral part of CDP, making it a full native table format across the entire platform, supporting read and write, ACID compliance, schema and partition evolution, time travel, and more, for all use cases. With this approach, it is easy to add new data services, and the data never changes shape or moves unnecessarily just to make the process fit.
In-place upgrade for external tables
Since petabytes upon petabytes of data already exists, serving mission critical workloads across numerous industries today, it would be a shame to see that data left behind. With CDP, Cloudera has added an easy alter table statement that migrates Hive managed tables to Iceberg tables without skipping a beat. So your data never moves, by just changing your metadata you can start benefiting from the Iceberg table format immediately.
Get started now with CDP’s architectural innovation with Iceberg
Whether you’re a data scientist, data engineer, data analyst, or machine learning professional, you can start using Iceberg powered data services in CDP today. Watch our ClouderaNow Data Lakehouse video to learn more about the Open Data Lakehouse, or get started with a few simple steps explained in our blog How to Use Apache Iceberg in CDP’s Open Lakehouse.
Editor's Choice

