

Apache Hadoop Ozone was designed to address the scale limitation of HDFS with respect to small files and the total number of file system objects. On current data center hardware, HDFS has a limit of about 350 million files and 700 million file system objects. Ozone’s architecture addresses these limitations[4]. This article compares the performance of Ozone with HDFS, the de-facto big data file system.
We chose a widely used benchmark, TPC-DS, for this test and a conventional Hadoop stack consisting of Hive, Tez, YARN, and HDFS side by side with Ozone. True to the current industry need for separation of compute and storage, which enables dense storage nodes and elastic compute, we run these tests with the datanodes and node managers segregated. The fundamental ambition of this endeavor, and the subsequent effort in optimizing the product, is to be comparable in terms of stability and performance to HDFS. To that end, we would like to call out the amazing amount of work put in by the community over the past several months towards this goal.
Ozone is currently scheduled for a Beta release along with Cloudera Data Platform – Data Center (CDP-DC) 7.1 release this year.
Hive on Ozone works faster
The following measurements were obtained by generating two independent datasets of 100GB and 1 TB on a cluster with 12 dedicated storage and 12 dedicated compute nodes. The last section of this article will provide information in greater detail about the setup.
The following charts show that considering the total runtime of our 99 benchmark queries Ozone outperformed HDFS by an average 3.5% margin on both datasets.
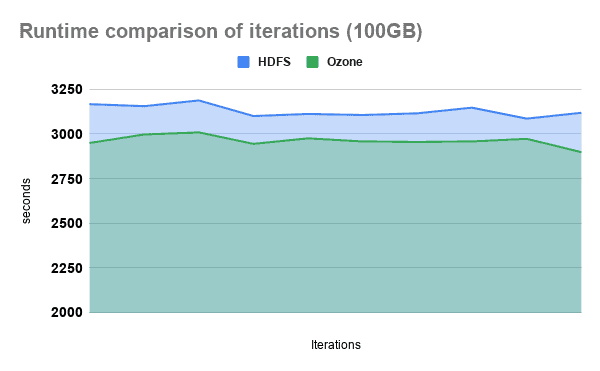
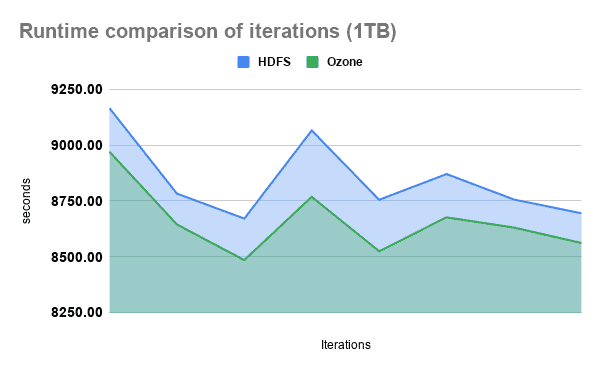
To have a finer grasp of the detailed results, we have categorized our queries into three groups:
- Faster queries (queries in which Ozone outperforms HDFS)
- Marginally slower queries (queries in which Ozone underperforms HDFS by a margin of 25% or less)
- Outliers (queries in which Ozone underperforms HDFS by over a 25% margin)
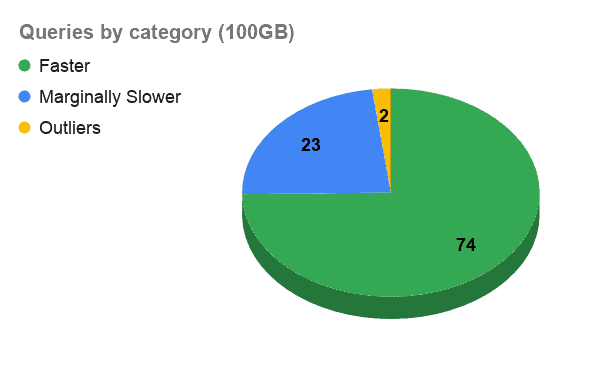
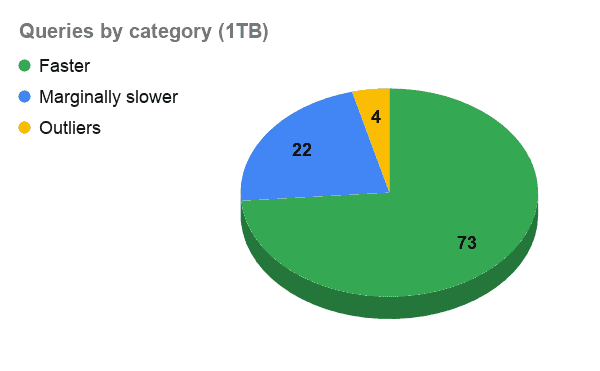
In over 70% of the cases, queries run faster when the data resides in Ozone versus HDFS. The community effort put into stabilization and performance improvements seems to be paying off. But there is still room to grow further.
The following scatter plot maps the average runtime difference between Ozone vs HDFS of each individual TPC-DS query for each dataset. Every query on the plot that hovers around 0% has an insignificant performance difference between Ozone and HDFS. The numbers have been averaged out for each query over 10 consecutive runs to normalize any variance due to noise.
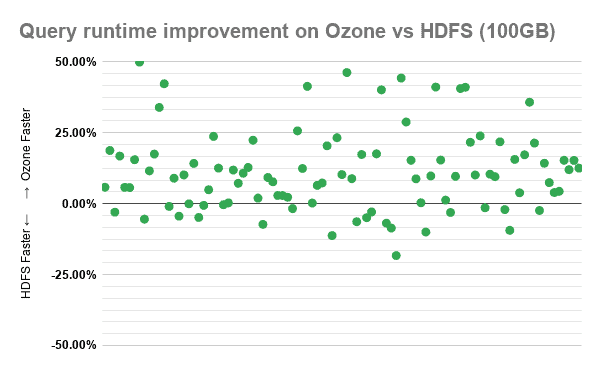
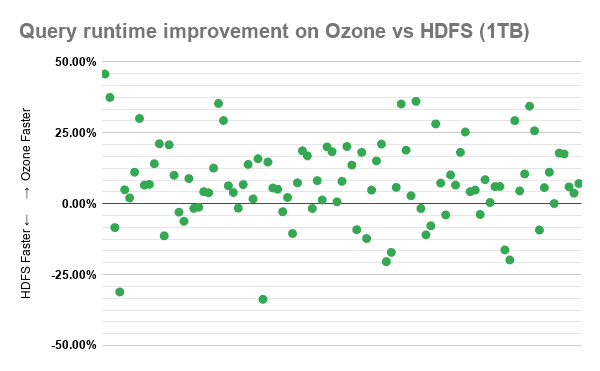
The values on the y-axis represent the proportion of the runtime difference compared to the runtime of the query on HDFS. So for example, 50% means the difference is half of the runtime on HDFS, effectively meaning that the query ran 2 times faster on Ozone while -50% (negative) means the query runtime on Ozone is 1.5x that of HDFS.
Conclusion
The test runs show that Ozone is faster by a small margin on slightly more than 70% of the TPC-DS queries. There are a few outliers that we are actively investigating to find bottlenecks and iron out the kinks with the highest priority.
Ozone is currently released as Tech Preview with CDP-DC and we are in the process of collecting feedback and continuing the evolution of the next-gen Big Data distributed storage system. As mentioned earlier, a Beta release should be coming out very soon, and a GA will follow soon after. The results that we have obtained here and the amount of work that is still ongoing into the stability and performance areas make this goal look like a very realistic target.
Environment Details
- The cluster setup consists of 28 uniform physical nodes coming with 20 core Intel® Xeon® processors, 128GB of RAM, 4x2TB disks and a 10Gb/s network. The nodes running CentOS 7.4, and Cloudera Runtime 7.0.3, which contains Hive 3, Hadoop 3, Tez 0.9, and Ozone built from Apache master branch from early January.
- 4 master nodes, one for Cloudera Manager, Prometheus and Zookeeper, one for YARN, one for Hive, and one for HDFS and Ozone as we use the two at different times.
- 12 storage nodes, with 2 dedicated disks for data storage, and 12 compute nodes with 3 disks dedicated to YARN and logs together.
- SSL/TLS was turned off and simple authentication was used.
- Ozone was configured to use a single volume with a single bucket to mimic the semantics of HDFS
- High availability was not enabled on any of the services.
- The internal network of the cluster is shared with other hosts, and we know that the traffic can be erratic between quite low and spikey. That is partly the reason why we have averaged out the results of ten full test runs on both HDFS and on Ozone before concluding with the final result.
- The result caching in Hive was turned off for all the queries to ensure all data is read from the FileSystem.
The tools we used to do the benchmark are also available and open source if you want to try it out in your environment. All the tools can be found in this repository.
Further reading
- Introducing Apache Hadoop Ozone: An Object Store for Apache Hadoop
- Apache Hadoop Ozone – Object Store Overview
- Open Hybrid Architecture: O3, the New Rocket Ship
- Apache Hadoop Ozone – Object Store Architecture
Editor's Choice


Memory is not balanced.
Not sure what exactly you are trying to point out here.
The tests were conducted with the same settings in YARN, TEZ and HIVE as well. The nodes were separated to 3 groups, management nodes, storage node, and compute nodes. Compute nodes ran only YARN NodeManagers, Storage nodes ran only HDFS DataNodes and Ozone DataNodes, management nodes were running NameNode, Ozone Manager, Storage Container Manager on one node, HiveServer2 and Hive Metastore on an other, YARN ResoruceManager and JobHistory server on a third one, while Cloudera Manager on a fourth one.
Test runs also were separated in time from each other, one test run on one file system at a time, so the systems – we believe – had the same resources available.
I would love to do this in my test environment. But there is nothing in cloudera documentation on how to Configure Hive so that it works with ozone. Nor anything on aby of the stuff that is supposed to be supported
In Cloudera Manager’s Hive configuration page, you can point the Hive Warehouse Directory to a URI. If you do not specify a protocol it points to HDFS by default, but you can specify a location on Ozone using the ofs:// protocol.
An other way of doing this is to point the database or table location to an Ozone path (using ofs:// protocol in the path URI) during table creation, however recent Hive versions restrict the managed tables to be in the Hive Warehouse Directory no matter what, if your version is already containing the restrictions on managed tables, you can still specify location using multi tenancy in hive (metastore.warehouse.tenant.colocation needs to be enabled) and then you can specify the managed table location on a per database basis.
See more about multi tenancy here: https://docs.cloudera.com/runtime/latest/using-hiveql/topics/hive_managed_location.html?
The data in Hive, was it an external or internal table? If internal table, what compression was used zlib or snappy + ORC?