

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
1. Introduction
Apache Hadoop Ozone is a distributed key-value store that can efficiently manage both small and large files alike. Ozone is designed to work well with the existing Apache Hadoop ecosystem and also fill the need for a new open-source object store that is designed for ease of operational use and scale to thousands of nodes and billions of objects in a single cluster.
Earlier articles Introducing Ozone and Ozone Overview introduced the Ozone design philosophy and key concepts. This developer-oriented article dives deeper into the system architecture. We examine the building blocks of Ozone and see how they can be put together to build an scalable distributed storage system.
2. Understanding the Scalability Problems
To scale Ozone to billions of files, we needed to solve two bottlenecks that exist in HDFS.
2.1. Namespace Scalability
We can no longer store the entire namespace in the memory of a single node. The key insight is that the namespace has locality of reference so we can store just the working set in memory. The namespace is managed by a service called the Ozone Manager.
2.2. Block Map Scalability
This is a harder problem to solve. Unlike the namespace, the block map does not have locality of reference since storage nodes (DataNodes) periodically send block reports about each block in the system. Ozone delegates this problem to a shared generic storage layer called Hadoop Distributed DataStore (HDDS).
3. Building Blocks
Ozone consists of the following key components.
- Storage Containers built using an off-the-shelf key-value store (RocksDB).
- RAFT consensus protocol via Apache Ratis. RAFT is a consensus protocol, similar in spirit to Paxos but designed for ease of understanding and implementation. Apache Ratis is an open source Java implementation of RAFT optimized for high throughput.
- Storage Container Manager (SCM) – A service that manages the lifecycle of replicated containers.
- Hadoop Distributed Data Store (HDDS) – a generic distributed storage layer for blocks that does not provide a namespace.
- Ozone Manager (OM) – A namespace manager that implements the Ozone key-value namespace.
4. Putting it Together
Image courtesy of https://pixabay.com/en/lego-building-game-toy-drawing-3388163/
In this section, we see how to put these building blocks together to create a distributed key-value store.
4.1. Storage Containers
At its lowest layer, Ozone stores user data in Storage Containers. A container is a collection of key-value pairs of block name and its data. Keys are block names which are locally unique within the container. Values are the block data and can vary from 0 bytes up to 256MB. Block names need not be globally unique.
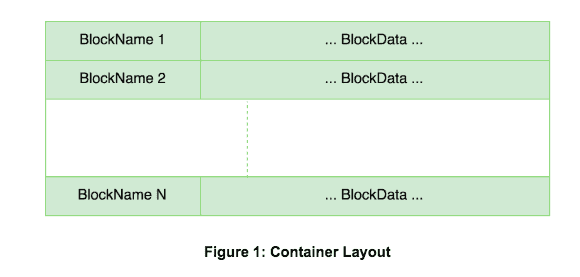
Each container supports a few simple operations:

Containers are stored on disk using RocksDB, with some optimizations for larger values.
4.2. RAFT Replication
Distributed filesystems must tolerate the loss of individual disks/nodes, hence we need a way to replicate containers over the network. To achieve this we introduce a few additional properties of containers.
- A container is the unit of replication. Hence its maximum size is limited to 5GB (admin configurable).
- Each container can be in one of two states: Open or Closed. Open containers can accept new key-value stores whereas closed containers are immutable.
- Each container has three replicas.
Open container state changes (writes) are replicated using RAFT. RAFT is a quorum based protocol in which a quorum of nodes vote on changes. At a given time, a single node acts as a leader and proposes changes. Thus, all container operations are reliably replicated in realtime to at least a quorum of nodes (2).
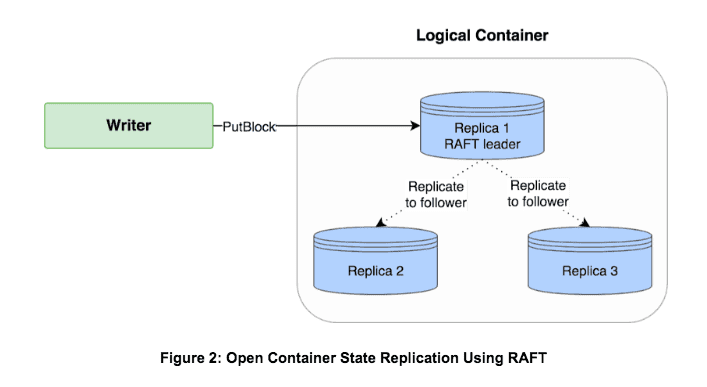
Container replicas are stored on DataNodes.
4.2.1. Container Lifecycle
Containers start out in the open state. Clients write blocks to open containers and then finalize the block data with an commit operation. There are two phases in which a block is written:
- Write the block data. This can take an arbitrarily long time depending on the speed of the client and network/disk bandwidth. If the client dies before the block is committed, the incomplete data will be garbage collected automatically by SCM.
- Commit the block. This operation atomically makes the block visible in the container.
4.3. Storage Container Manager (SCM)
Now we know how to store blocks in containers and replicate containers over the network. The next step is to build a centralized service that knows where all the containers are stored in the cluster. This service is the SCM.
SCM gets periodic reports from all DataNodes telling about the container replicas on those nodes and their current state. The SCM can choose a set of three DataNodes to store a new open container and direct them to mutually form a RAFT replication ring.
SCM also learns when a container is becoming full and direct the leader replica to “close” the container. SCM also detects under/over replicated close containers and ensures three replicas exist for each closed container.
4.4. Containers + RAFT + SCM = HDDS!
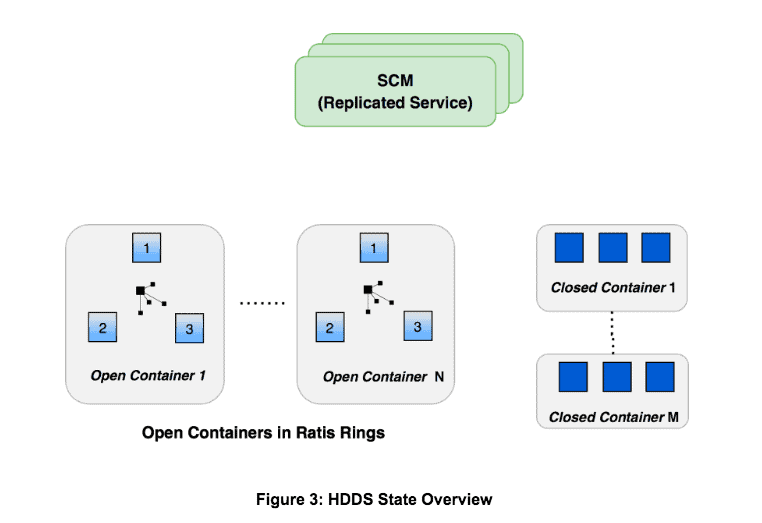
With the above three building blocks, we have all the pieces to create HDDS, a distributed block storage layer without a global namespace.
DataNodes are now organized into groups of three with each group forming a Ratis replication ring. Each ring can have multiple open containers.
SCM receives reports from each DataNode once every 30 seconds informing about open and closed container replicas on each node. Based on this reports SCM makes decisions such as allocating new containers, closing open containers, re-replicating closed containers on disk/data loss.
Clients of SCM can request the allocation of a new block, and then write the block data into the assigned container. Clients can also read blocks in open/closed containers and delete blocks. The key point is that HDDS itself does not care about the contents of individual containers. The contents are completely managed by the application that is using SCM.
4.5. Adding a Namespace – Ozone Manager
With HDDS in place, the only missing ingredient is a global Key-Value Namespace. This is provided by the OzoneManager. OM is a mapping service from key names to the corresponding set of blocks.
Clients can write multiple blocks into HDDS and then commit they key->blocks mapping atomically into OM to make the key visible in the namespace.
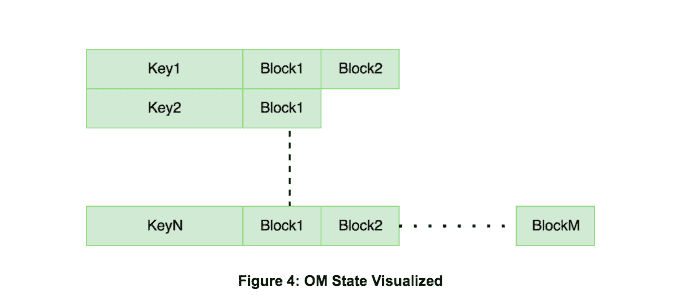
OM stores its own state in a RocksDB database.
5. HDDS Beyond Ozone
HDDS can be used as a block storage layer by other distributed filesystem implementations. Some examples that have been discussed and may be implemented in the future:
- HDFS on HDDS (HDFS-10419) – HDDS can be used to neatly solve the block-space scalability problem by replacing the existing HDFS block manager. This idea is similar to the HDFS-5477 proposal.
- cBlocks (HDFS-11118) – a prototype of mountable iSCSI volumes backed by HDDS storage.
- A hypothetical object store that also stores its namespace in HDDS containers.
And more… Bring your own namespace!
Editor's Choice


Great article!
Can I translate to Chinese?
Yes that would be great, thanks! Please add a link to the original article in your translated version.
Hi Arpit,
I have few questions.
Is Ozone is Production ready ?
Is it easy to implement? The efforts required to implement if it is production ready ?
Will it resolve the purpose of implementing in the 280+ node on prem clusters which has lots of small files..
In Which scenario this products fits well ?
compatible with CDP ? if should be implemented after CDP upgrade or not ?
What is the Cloudera final recommendation Whether we want to use it or not ?