

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Introducing our Storage Environment O3
Building on the last three blogs (vision, key tenets/concepts, real-world use case) in the Open Hybrid Architecture series, we now want to take a deeper dive into our Storage Environment, especially O3 (the molecular formula for Ozone).
![]()
First, we want to look back at the annals of history of Hadoop. Apache Hadoop File System (HDFS) started with 5000 lines of code in 2006. This is the first software defined storage adopted by enterprises, that now stores hundreds of exabytes of big data on commodity hardware to power the analytics revolution that we are familiar with today. We are now taking another giant step and we are strapping on our seat belts as we get on the rocket ship called “O3” (seatbelts are required in space!). There is an interesting back story of how we settled on the name O3, after Jitendra and I met with one of our dear sales engineers and one of our dear early adopter customers and we will save that for a different blog.

Ozone or O3 is the next generation object storage that is designed to:
- Scale to trillions of files, thousands of nodes (imagine, the amount of data created by connected devices)
- Consolidate tiers of secondary storage (hadoop, archive, backup)
- Stay strongly consistent like Apache HDFS, so that analytics applications do not end up building a consistency layer
- Speak multiple protocols (Hadoop API, S3 API, iSCSI block, NFS) for today’s diverse workloads
- Ground up for the new containerized world, with storage interface for Kubernetes and Apache YARN
Foundational Building Block of Open Hybrid Architecture
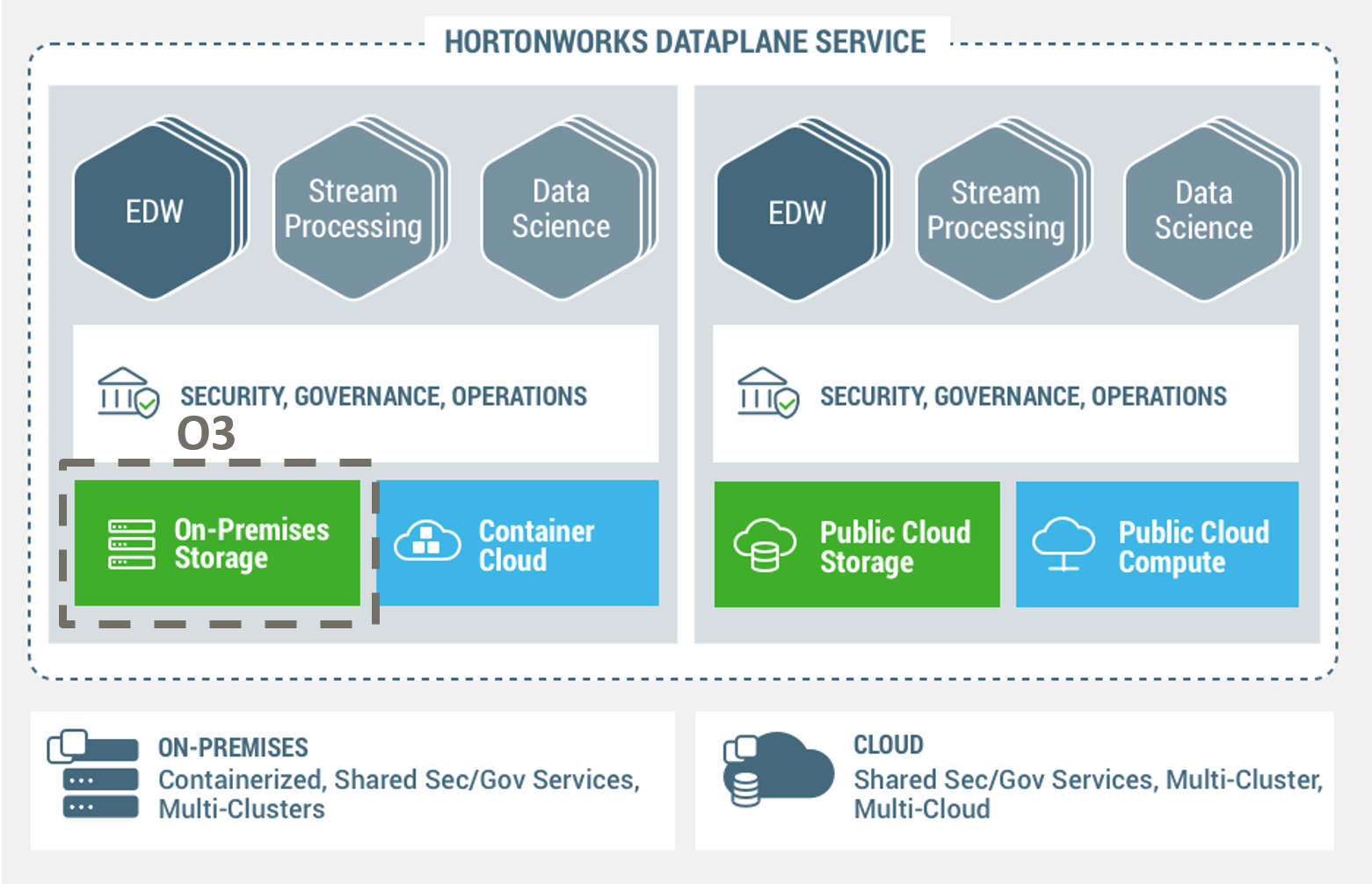
For some of us who lived through the Storage Area Network adoption in early 2000s- this is a deja vu. We are starting to see storage being de-coupled from compute in the cloud world- both compute and storage can be scaled separately as the network is getting faster, bigger with better priority flow control. Our on-premise customers are asking us to decouple the storage so that they can scale the storage environment separately. When the storage is de-coupled and shared, it needs to scale and have multiple protocols to support diverse set of use cases. With support for container orchestration, we can now design our workloads so that they can be deployed on-premises and cloud. However, we will caveat with the statement that some of our core customers still prefer to have coupled compute and storage architecture to benefit from localization and our O3 architecture supports both deployment models.
Leveraging Lessons Learned
O3 leverages over a decade of lessons and is designed by the same community and core team members who have been involved with Apache HDFS from Day 1.
Open
As the “O” in the name denotes, O3 is 100% open source (part of Apache Hadoop project). Our customers don’t have to worry about the lock-in with a proprietary data format.
Scale
We are benefiting from many of Apache HDFS advantages. Like Apache HDFS, O3 will scale to thousands of nodes as we have customers with thousands of nodes in a single cluster in production today. This is an achilles heel for some object storage vendors. The data placement algorithm inhibits the scale of some object storage vendors- as nodes are deleted or added permanently, there is a huge data movement (more than amount of data deleted or added) and the new nodes are not usable for long time. Now, Apache HDFS also suffers from a small file problem, as large number of files are created in a single cluster (to clarify, HDFS can easily scale to 250M+ files in a cluster, but we are talking about Hadoop scale for today’s connected world!). While storing the entire metadata in a JVM memory footprint inside a Name Node helps with the latency, it puts a limit on total number of files in a Hadoop cluster and we now use Name Node Federation to push the scale limit. O3 does solve the small file issue from ground up with the flat key-value and smarter block placement with storage container approach and hence, can scale to tens of billions of objects.
Consolidation
As we are talking to our customers, our customers want to lock the value from the dark data sitting inside their archive storage. Many times, they have to copy data from one tier to another tier, creating duplicate data. They want to apply analytics to the dark data. O3 will provide a scalable solution to consolidate all the secondary data silos-hadoop, logs, backup, archive- into a single solution and break the silos and then we are best positioned to bring all of big data analytics right next to the data.
Consistency
O3 is strongly consistent and stays true to the roots of Apache HDFS. Because many on-premises and cloud object storage solutions are eventually consistent, the upper layer applications need to build a consistency layer to work around the eventual consistency drawbacks. Many times, this means that they stay confined to the archive use cases and can’t truly consolidate all the secondary storage tiers.
Multi-Protocol
While Apache HDFS was designed for immutable data (with append only operation) with Hadoop API, O3 is designed to support the multiple protocols in the new world. In first iteration, O3 will support Hadoop APIs so that existing Hadoop workloads can work as is, without any change. O3 will also support S3 APIs so that our customers can make their applications portable across cloud and on-prem deployment models and we recently launched an alpha version with support for S3 APIs. Once we harden Hadoop and S3 APIs, we are going to provide an iSCSI and NFS interface to O3. We have made decent progress with an initiative (internally, we refer to as Quadra) to demonstrate iSCSI volume working with Kubernetes containers.
In-Place Upgrade
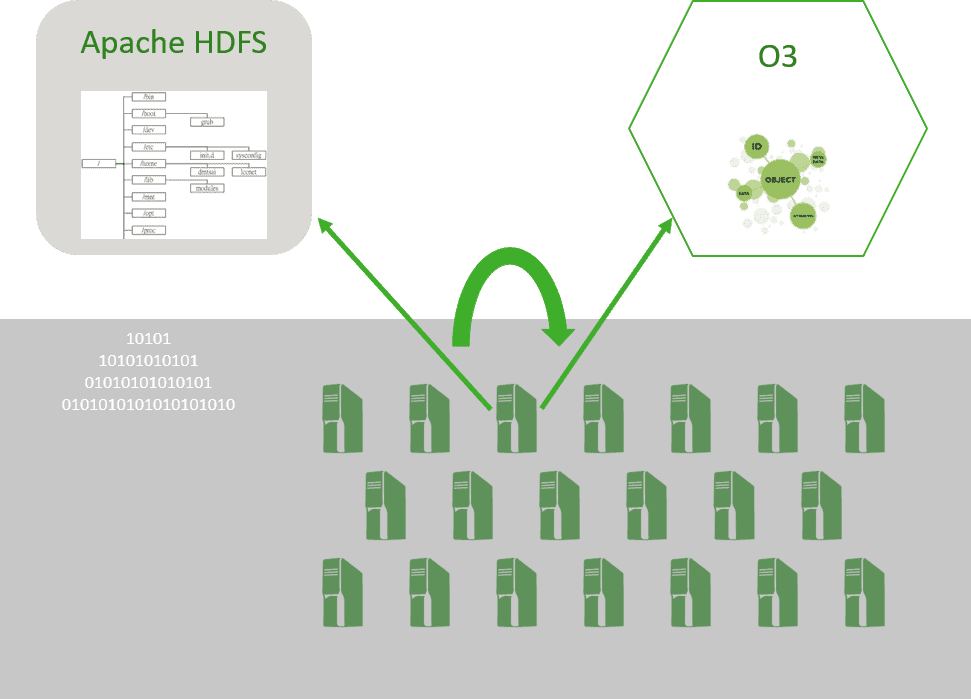
O3 can use the same set of servers (aka data nodes) as Apache HDFS. This helps with co-existence of O3 and HDFS in the same cluster and migration from Apache HDFS to O3. It is our strong intent to provide a seamless in-place upgrade path to our enterprise customers who now have hundreds of Petabytes under management.
Better User Experience
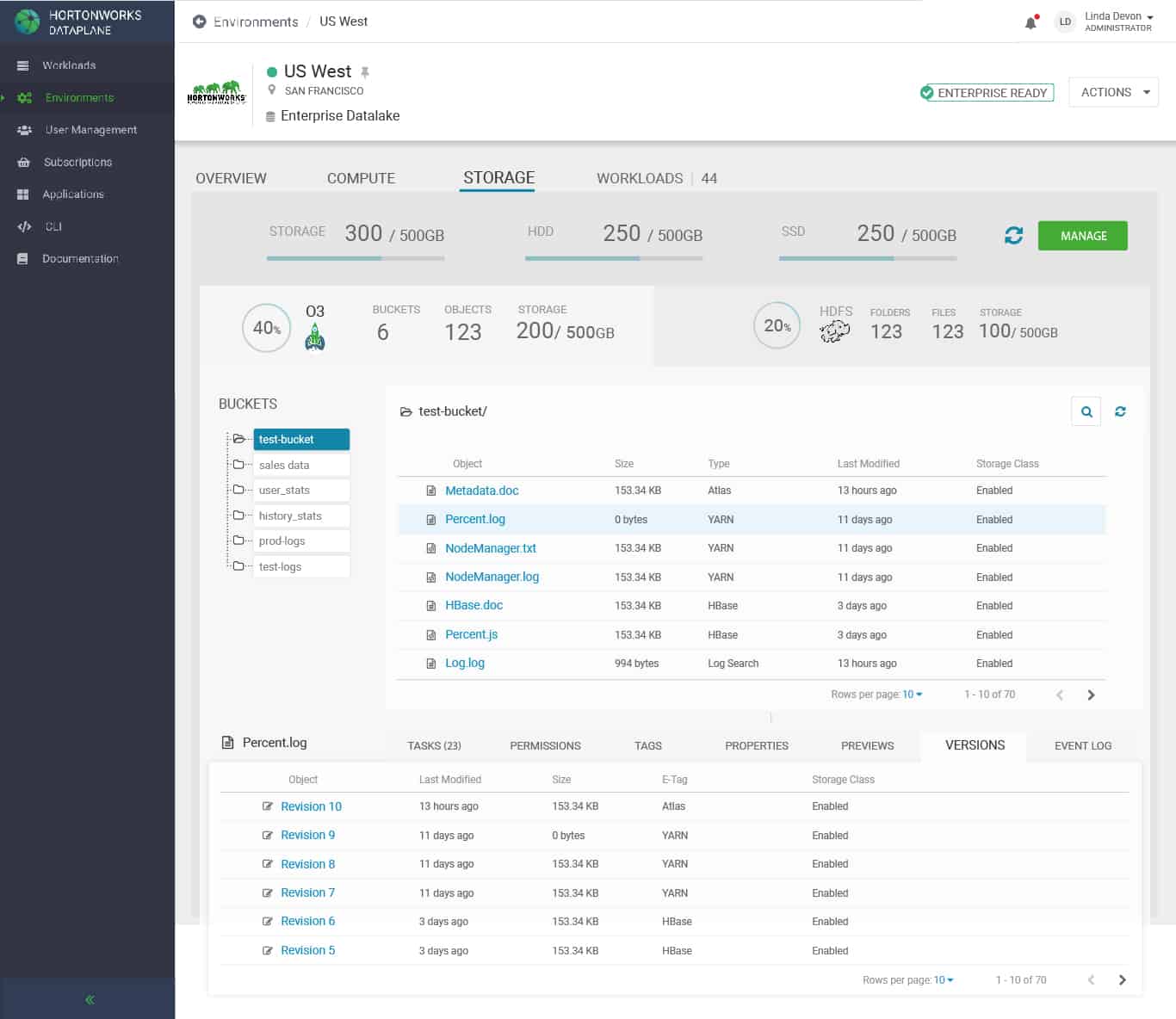
We have traditionally focused on strong file-system functionalities in Apache HDFS and our user experience around Apache HDFS has not been as rich. We are going to invest in the UX of O3 from Day 1 and will provide a rich user experience (additional monitoring or data migration between HDFS and O3) in our DataPlane Services.
Container Ready
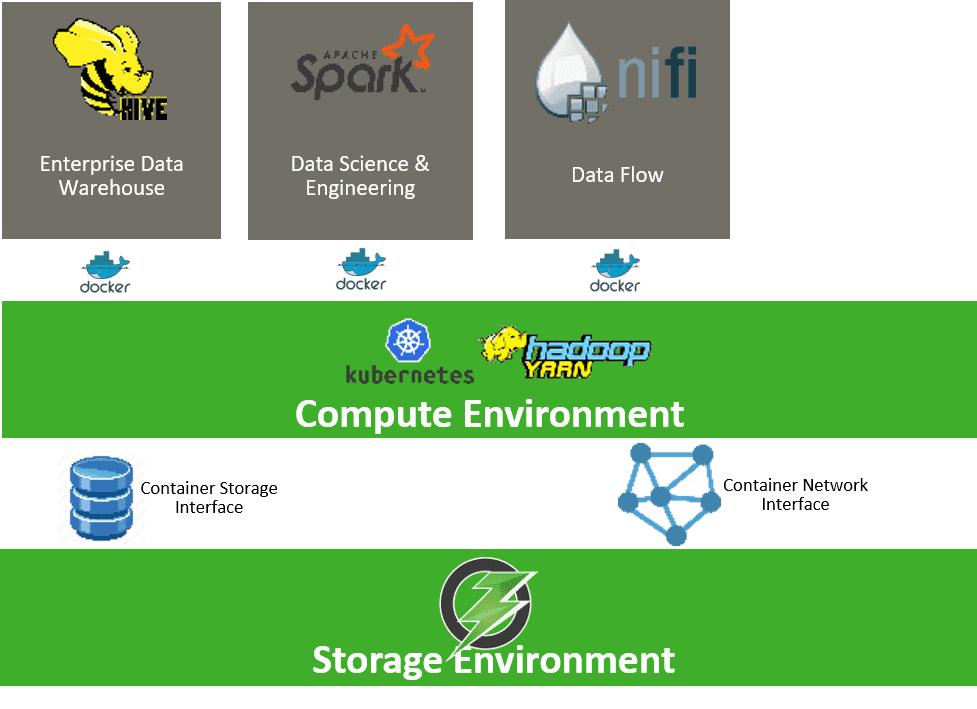
O3 can be deployed on bare-metal servers or Kubernetes containers as we provide options to our customers. O3 will support Container Storage Interface (CSI) so that O3 can provide persistent storage (S3 API or iSCSI interface) to containers on Kubernetes or Apache YARN, which in turn will host our analytics workloads such as Enterprise Data Warehouse or Data Science/Engineering workloads.
What Does It Mean for You
Building a rocket ship like O3 is a huge endeavor and the team has been on this for years (check out the latest O3 alpha (version 0.3) with S3 interface). We are continuing to make progress on Container Storage Interface and User Experience and our goal is to have an O3 orbitting in 2019! Please stay tuned for more blogs in this series and check with your account team if you have any feedback or request. We will look forward to working with you!
Editor's Choice

