



In the previous blog post, we looked at some of the application development concepts for the Cloudera Operational Database (COD). In this blog post, we’ll see how you can use other CDP services with COD.
COD is an operational database-as-a-service that brings ease of use and flexibility to Apache HBase. Cloudera Operational Database enables developers to quickly build future-proof applications that are architected to handle data evolution. Many business applications such as flight booking and mobile banking rely on a database that can scale and serve data at low latency. COD helps you achieve scale for your applications by taking advantage of COD’s auto-scaling features.
In the following sections, we see how the Cloudera Operational Database is integrated with other services within CDP that provide unified governance and security, data ingest capabilities, and expand compatibility with Cloudera Runtime components to cater to your specific use cases.
Integrated across the Enterprise Data Lifecycle
Cloudera Operational Database (COD) plays the crucial role of a data store in the enterprise data lifecycle. You can use COD with:
- Cloudera DataFlow to ingest and aggregate data from various sources
- Cloudera Data Engineering to ingest bulk data and data from mainframes
- Cloudera Data Warehouse to perform ETL operations
- Cloudera Machine learning to train and serve machine learning and AI models
The following image shows you how COD integrates within your enterprise data lifecycle.
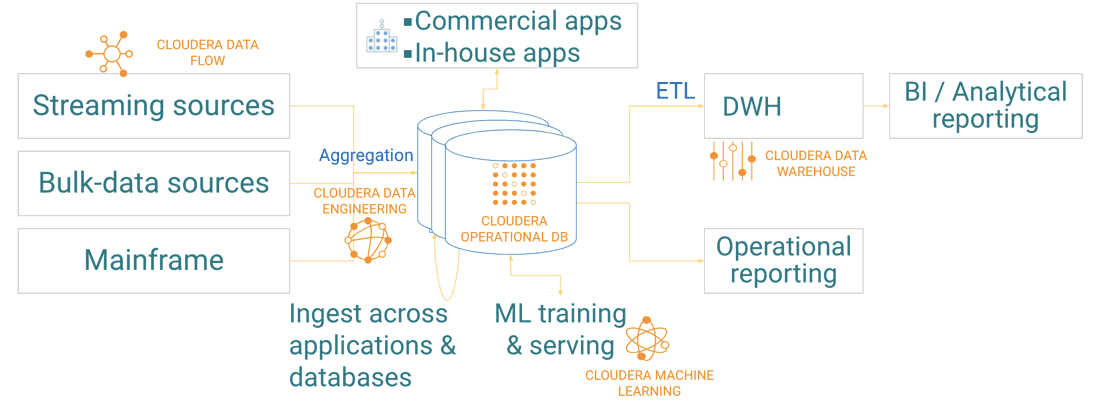
Cloudera Shared Data Experience (SDX)
Cloudera Shared Data Experience (SDX) Data Lake helps you configure and manage authorization and access control through the Apache Ranger user interface that ensures consistent policy administration for Apache HBase in COD. Apache Phoenix security derives its policies applied to the underlying Apache HBase tables in Apache Ranger. You can grant the read or write permissions to an Apache HBase table for a specific user using the Apache Ranger user interface.
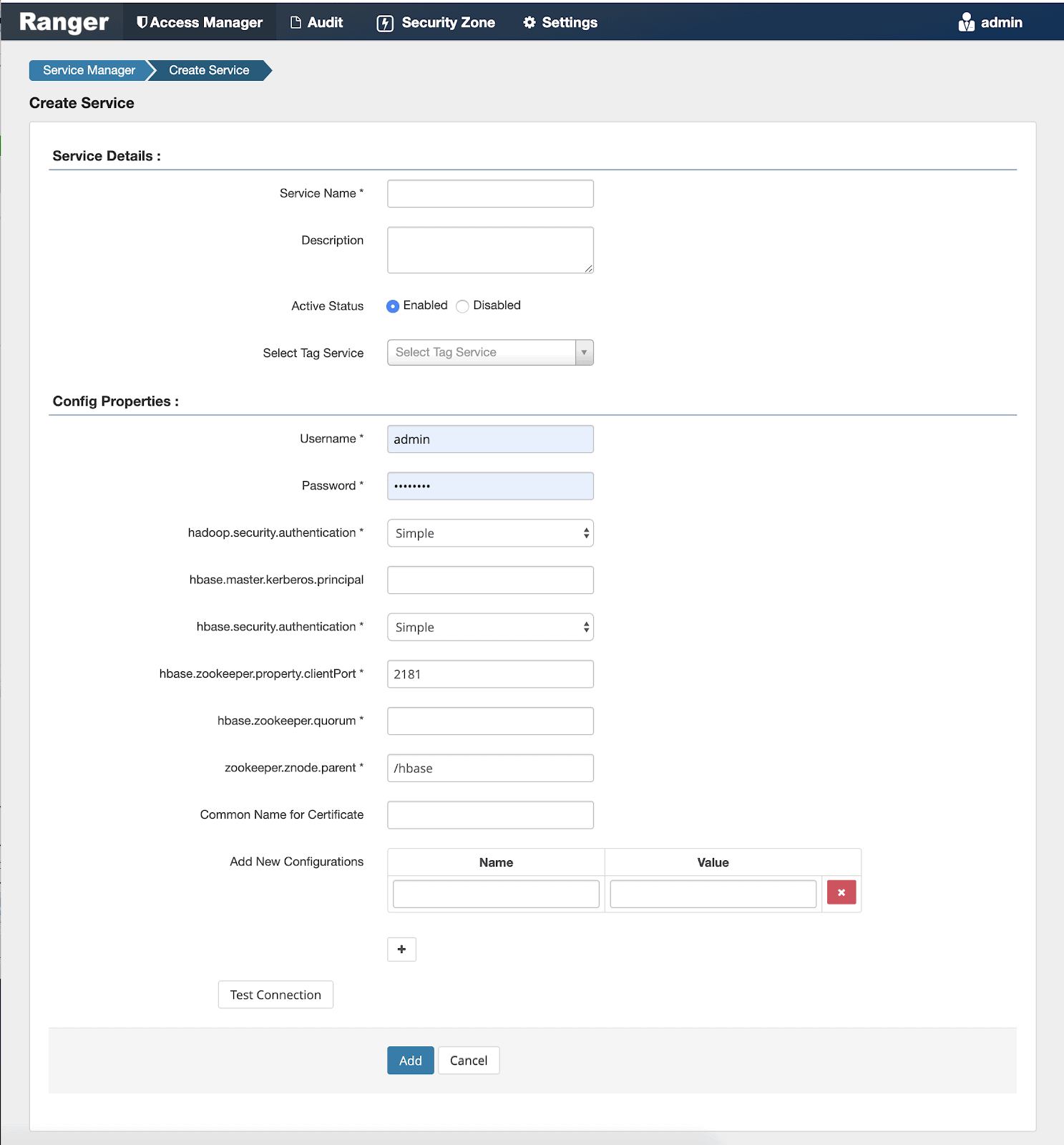
Ranger enables you to create services and add access policies for Apache HBase. Ranger security zones help organize service resources into multiple security zones.
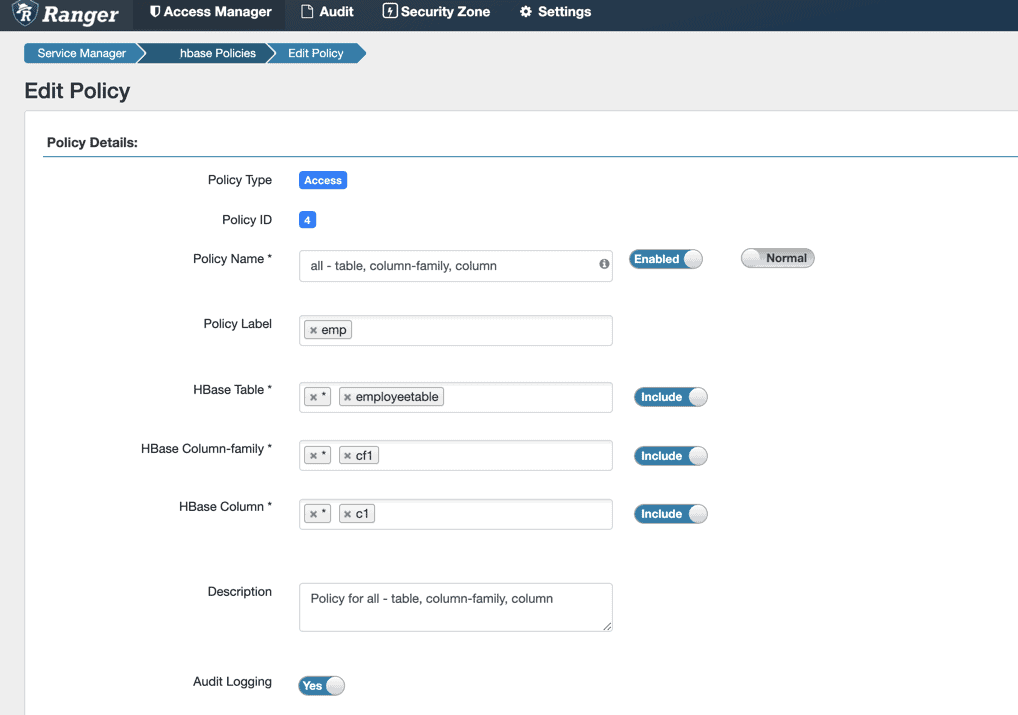
For more information about how security administrators can define security policies at the database, table, column, and file levels, see Using Ranger to Provide Authorization in CDP.
Cloudera DataFlow
You can use Apache NiFi in Cloudera DataFlow to move data from various sources into the Cloudera Operational Database.
Apache NiFi enables your applications running on COD to always have access to the latest data.
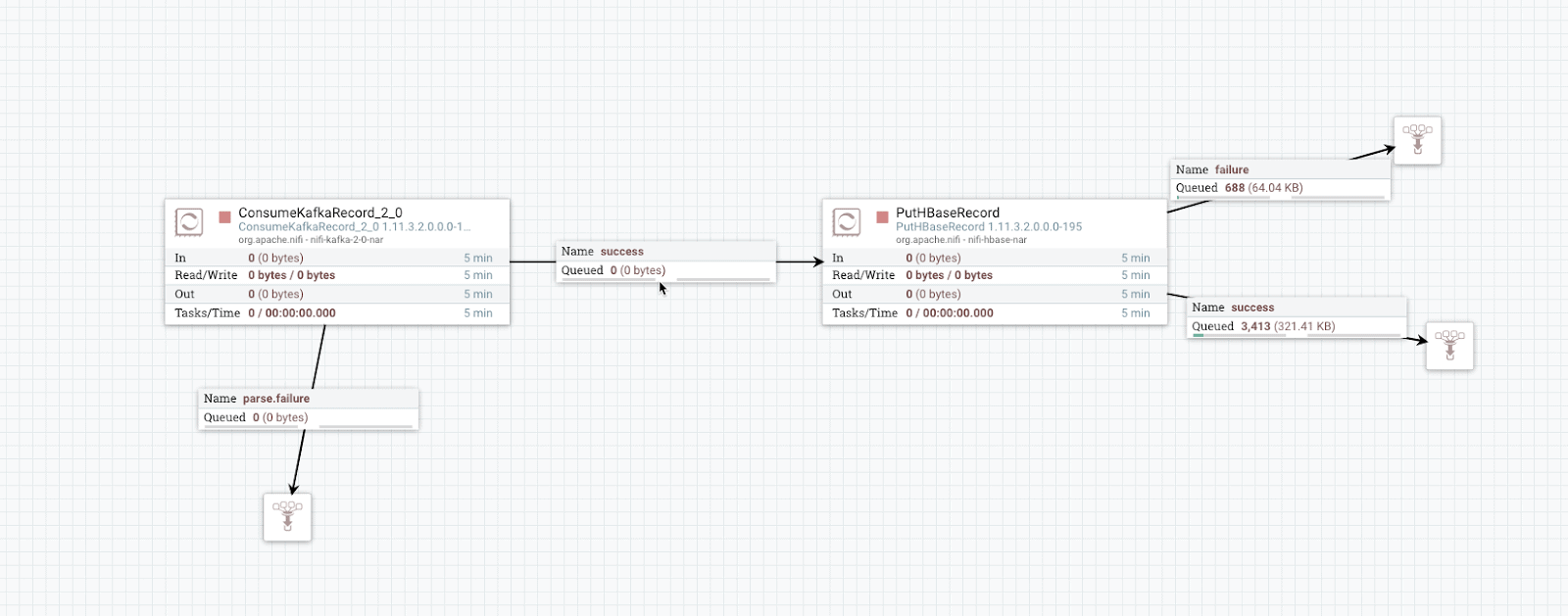
Read the Ingesting Data into Apache HBase in CDP Cloud to know more about how you can ingest data into COD using Apache NiFi.
Read the Cloudera DataFlow for Data Hub documentation for more information about Cloudera DataFlow.
Read about Building a Scalable Process Using NiFi, Kafka, and HBase on CDP.
Cloudera Streaming Analytics
You can use Cloudera Streaming Analytics that offers an Apache HBase connector that enables you to use COD as a data sink. You can use the connector to store the output from a real-time processing application in COD. If you want to use this capability, you must develop your applications defining COD as a data sink, and add the Apache HBase dependency to your application.
Read about how you can use COD for streaming analytics by using HBase sink with Flink.
Cloudera Data Engineering
Apache Spark in the Cloudera Data Engineering experience can be used with Apache HBase and Apache Phoenix in COD. You can read or write data using the Apache Phoenix JDBC driver, the Phoenix-Spark connector, or the HBase-Spark connector. COD web user interface provides you with all the information you require to connect the Apache Spark instance in CDE to COD.
You can use the Phoenix-Spark connector plugin to perform READ and WRITE operations on COD. The Phoenix-Spark connector allows Spark to load Phoenix tables as Resilient Distributed Datasets (RDDs) or DataFrames and lets you save them back to Apache Phoenix.
To know more about how to use the Phoenix-Spark connector, see Using Apache Phoenix-Spark connector.
The HBase-Spark Connector bridges the gap between the simple HBase key-value store and complex relational SQL queries and enables you to perform complex data analytics on top of HBase using Spark.
To know more about how to use the HBase-Spark connector, see Using the HBase-Spark connector.
Read about how to use CDE experience with COD in this Cloudera Community article.
Cloudera Machine Learning
Cloudera Machine Learning (CML) is designed for data scientists and machine learning engineers, enabling them to create and manage machine learning projects from code to production.
CML enables you to govern and automate model cataloging and seamlessly move results to the Cloudera Operational Database (COD). COD auto-scaling and sub-second latency help you build out real-time applications for random reads and writes.
Read about Accessing Data from Apache HBase in CML.
Read about deploying ML models to production using Cloudera Operational Database in How to deploy ML models to production – Cloudera Blog.
Read about a use case with COD and CML in Using COD and CML to build applications that predict stock data – Cloudera Blog.
Conclusion
Cloudera Operational Database (COD) experience works with other CDP services to help you achieve your enterprise data lifecycle goals. COD auto-scales, auto-tunes, and auto-heals, therefore allowing you to focus on application development for your business use cases.
Editor's Choice

