

Currently, many enterprises, including many Cloudera customers, are experimenting with machine learning (ML) and creating models to tackle a wide range of challenges. While today, many models are used for dashboards and internal BI purposes, a small and rapidly growing group of enterprise leaders have begun to realize the potential of ML for business automation, optimization and product innovation. In this blog post we will be diving into the latter—specifically, how lines of business are reorienting their data scientists to work with application engineers and other stakeholders to solve real-time business problems. These use cases vary across industry and business criticality and are growing in breadth and depth as companies learn how much can be done with the data they have.
Examples of these use cases include:
- Cerner, a healthcare leader, utilizes sensor data from patients to identify Sepsis using machine learning models and proactively notifies doctors so that they can further diagnose and treat within the 6 hours that this disease is treatable
- Financial services companies are using machine learning to detect fraudulent transactions in real time and using real-time feedback from customers to do reinforcement learning
- Railroad companies have long-haul freight trains go through special stations where they take thousands of high resolution pictures and apply machine learning to identify failing parts. They then schedule the train to arrive at a repair facility along with parts and technicians — making the stop akin to a formula one pit stop
- Utilities are using smart-meter data to identify potential problems in electrical distribution grid and proactively schedule maintenance
- Media companies are using machine learning to identify and provide relevant content in real time based on what you are viewing
- Ad technology & ecommerce companies have been been using these capabilities the longest to ensure relevance of their offers to various target audiences
Once a problem is identified and a decision is made to invest in a business solution, data scientists will study the data using various ML tools to create the algorithms and work with software engineers to build applications that can leverage those algorithms.
Depending on their needs, the data may reside in their data warehouse or inside their operational databases. Many of Cloudera’s customers will use Spark & SparkMLlib inside of Cloudera Machine Learning (CML) to train their algorithms. Using CML enables seamless workflows for operationalizing models in a single, secure, and governed platform built for faster ML workflows. To learn more about our approach to developing production workflows in CML join this webinar.
Training algorithms can be done in the operational database
One of the primary reasons to use a data warehouse for training algorithms is to avoid adding load to an existing operational database and thereby impacting SLAs of the operational workload. However, in the case with Cloudera’s Operational Database (OpDB), users can set quotas and limits on the amount of resources and the load that machine learning users can put on the system. This protects operational workloads while allowing data scientists to use real-time data without incurring the cost of creating a second copy.
When using Cloudera’s OpDB, customers often use Spark to query data within the operational database eliminating the need to offload data prior to exploring it and using it for training for the purposes of machine learning.
ML algorithms must meet application level availability, resiliency and responsiveness requirements
The development & training of the ML based algorithm is typically done in conjunction with developing the application (assuming that the fact that this is doable has already been established). Typical application requirements for an underlying database often include:
- Sub 1ms response time
- Continuous availability in the face of hardware outages (or high availability but high availability is less preferred)
- Ability to scale-out
- High concurrency (1,000s of requests / second)
When deploying machine learning as part of an application, application requirements on availability, resiliency and responsiveness must be met. In addition, several additional machine learning specific requirements are imposed on the application:
- Ability to audit decisions
- Ability to version models / algorithms
- Ability to support data augmentation for continuous learning (depending on the algorithm that is deployed)
Cloudera’s Operational Database can meet both sets of requirements
In order to meet these requirements, customers will typically flatten the output of the machine learning model into a table — essentially pre-computing all the outputs for the entire input space. This creates additional requirements for the underlying database:
- Ability to create a table that is in the hundreds of gigabytes or terabytes (depending on the size and number of input parameters)
- Simplicity of management (don’t force admins to manage sharding, etc)
From Cloudera’s operational database perspective, a machine learning model is easily represented as a table (and this is the approach many customers have taken) :
- The primary key is composed of the set of inputs required to identify the output (regardless of the number of inputs required)
- Column: Machine learning model recommendation (the output)
- Column: Model version
An audit capability also looks like a table:
- The primary key is composed of the set of inputs required to identify the output (regardless of the number of inputs required)
- Column: who did you serve this output to (eg customer ID)
- Column: what output was served
- Column: what model version was used
- Column: what alternative answer would have been better (augmentation)
Augmentation can be done manually or programmatically (ie., when a credit card company emails you asking for you to verify a transaction — they are doing data augmentation). This audit table that is augmented can be used for reinforcement learning in-place in the database or offloaded into a data warehouse.
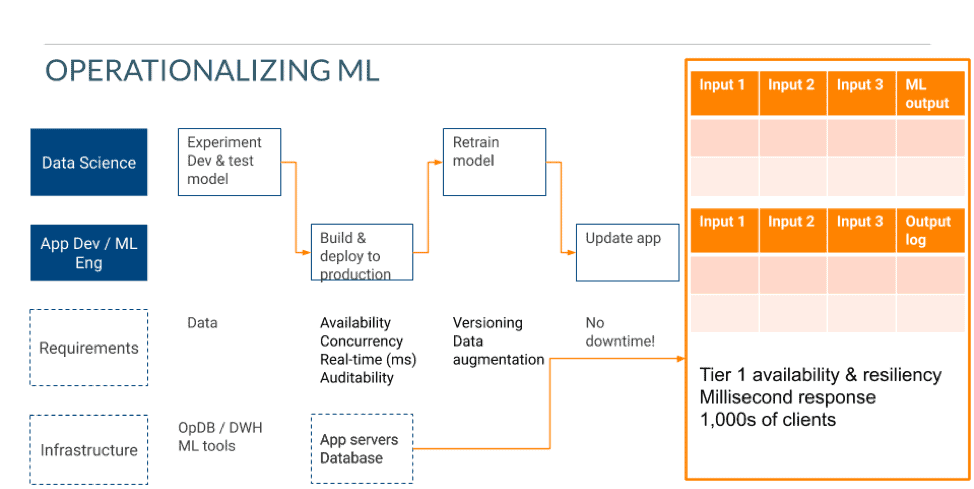
Since the data is in the database, model updates can be done w/o any application down-time.
From a scaling perspective, Cloudera’s Operational Database is built on Apache HBase & Apache Phoenix — both of which have been proven to handle tables that are hundreds of terabytes in size without any problems.
Checkout Cloudera’s Operational Database within the Cloudera Data Platform on Public Cloud to build your next ML based app.
Editor's Choice

