


Cloudera Operational Database is now available in three different form-factors in Cloudera Data Platform (CDP).
If you are new to Cloudera Operational Database, see this blog post. And, check out the documentation here.
In this blog post, we’ll look at Apache HBase and Apache Phoenix concepts relevant to developing applications for Cloudera Operational Database.
But first, these are the various form factors in which Cloudera Operational Database is available to developers:
Public cloud:
- CDP Data Hub Operational Database template
- Cloudera Operational Database (COD) experience that is is a managed dbPaaS solution
On-premises:
- CDP Private Cloud Base
The different form-factors enable you to develop applications that can run On-premises, on the public cloud or both.
Cloudera Operational Database is powered by Apache HBase and Apache Phoenix. In Cloudera Operational Database, you use Apache HBase as a datastore with HDFS and/or S3 providing the storage infrastructure. You have the choice to either develop applications using one of the native Apache HBase applications, or you can use Apache Phoenix for data access. Apache Phoenix is a SQL layer that provides a programmatic ANSI SQL interface. It works on top of Apache HBase, and it makes it possible to handle data using standard SQL queries. (The DML statements are not standard SQL).
Many developers prefer to use the Structured Query Language (SQL) to access data stored in the database and Apache Phoenix in Cloudera Operational Database helps you achieve this. If you are a database administrator or developer, you can start writing queries right-away using Apache Phoenix without having to wrangle Java code.
To store and access data in the operational database, you can do one of the following:
Use native Apache HBase client APIs to interact with data in HBase:
You can also access your data using the Hue HBase app. This app is a console that you can use to access data stored in Apache HBase.
Or, use Apache Phoenix with one of the Apache Phoenix drivers to interact with data stored in Apache HBase:
- Use the JDBC driver for Apache Phoenix
- Use the ODBC driver for Apache Phoenix
- Use the Python driver for Apache Phoenix
Let us look at concepts in Apache HBase and Apache Phoenix that you need for your application development.
Namespace
A namespace is a logical grouping of tables analogous to a database in a relational database system.
Tables and rows
One or more column qualifiers constitute a row; one or more rows constitute a table. Each row can be identified by a row key. When writing applications, you can access a row or a sequence of rows using the unique row key.
Column families
Column families defined at the time of table creation based on how they are related to each other. Column families can have column qualifiers where the values can be stored. Column qualifiers are also sometimes just called columns and are organized into column families. Column families are located together in the storage.
Column families vertically partition data. If you have a use case where you want to access a set of column qualifiers, partitioning column families will reduce the number of store files to read and improve read performance. You must avoid partitioning if you want to access two or more column families at the same time.
Compression and encoding are applied at the column-family level. You do not have to declare data types for each column family and a column family can contain data of multiple data types.
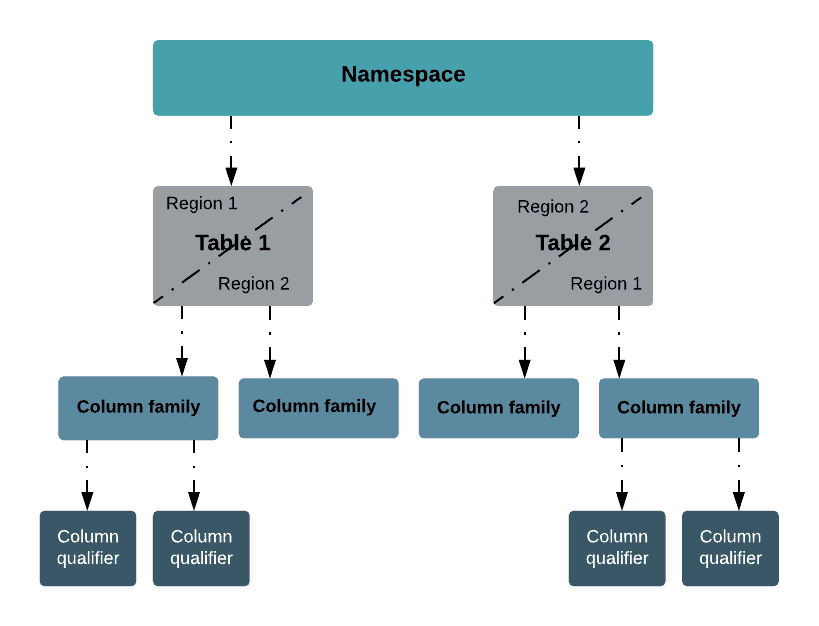
Composition of Apache HBase tables
Apache HBase tables consist of one or more column families and maybe split into multiple regions. The data for each column family in each region is saved on several HFiles, which are in HDFS or object storage such as S3 and ADLS.
Each region stores the rows within a specific keyspace range, that is between a starting row key and an ending row key. Row keys are unique to a region and no two regions overlap. A region is served by one RegionServer at a time, ensuring consistency within a row.
To know more about Apache HBase region splitting and merging, see the blog post here: https://blog.cloudera.com/apache-hbase-region-splitting-and-merging/
Apache HBase data layout
Apache HBase excels in Online Transaction Processing (OLTP) use cases because there can be more than one version of its basic storage unit that is called a column qualifier (CQ) based on a timestamp. The unique value of each column qualifier version is stored separately. A column family can have any number of cells and they can be completely random and have different data types, numbers, and names in each row. You can store any number of cells in a column family, but note that column qualifiers in one column family are stored separately from the column qualifiers in other column families.
If you are interested in how Apache HBase does Multiversion Concurrency Control (MVCC), you can read this blog post: https://blogs.apache.org/hbase/entry/apache_hbase_internals_locking_and.
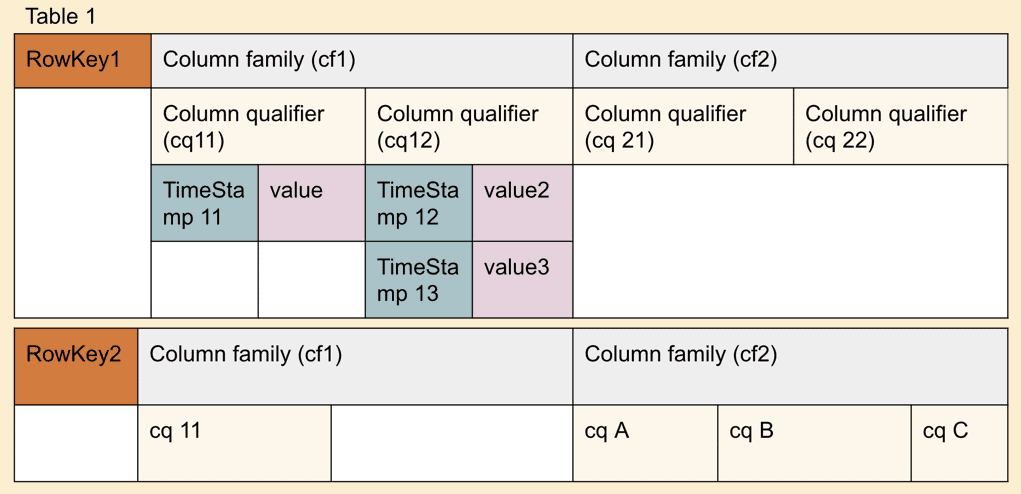

Apache Phoenix tables
Apache Phoenix tables have a 1:1 relationship with an Apache HBase table. You can choose to create a new table using an Apache Phoenix DDL statement like CREATE TABLE, or create a view on an existing Apache HBase table using the VIEW statement.
Create, drop, or modify the contents of an Apache HBase table using Apache Phoenix DDL statements. In many cases, you may be able to alter an Apache Phoenix table directly using Apache HBase native APIs. This is not supported in Cloudera Operational Database and will result in errors, inconsistent indexes, incorrect query results, and sometimes corrupt data.
Data ingest
You can use Apache Phoenix SQL statements to ingest data into Cloudera Operational Database (COD). COD is also closely integrated with other Cloudera Data Platform services. You can see how to use some of the data ingest capabilities in the following links.
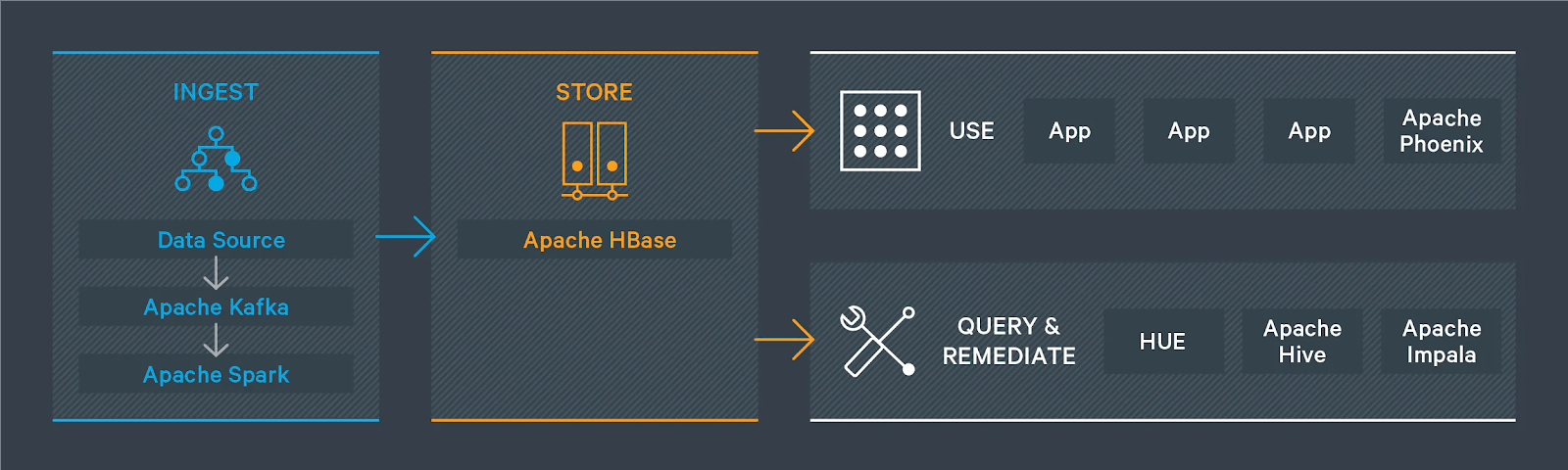
- Use Spark or Hive along with Apache HBase to ingest data. You can use the HBase-Spark connector. Also, see a list of ways in which you can import data into HBase Importing data into HBase.
- Use Spark or Hive along with Apache Phoenix to ingest data. You can use the Phoenix-Spark and Phoenix-Hive connectors. See, Understanding Apache Phoenix-Spark connector and Understanding Apache Phoenix-Hive connector.
- Use Cloudera DataFlow (Apache NiFi) to ingest data. See Ingesting Data into Apache HBase in CDP Public Cloud.
- Use Cloudera Data Engineering (Spark) to ingest data. See Cloudera Operational Database – Cloudera Data Engineering using Phoenix.
Apache Phoenix DML commands
You can use Apache Phoenix DML commands such as UPSERT or DELETE. Ensure that the DML commands that you want to use are supported by Apache Phoenix. For more information see the Apache Phoenix grammar reference.
Hue user interface to access data
Hue is a web-based interactive SQL editor that enables you to interact with data stored in Cloudera Operational Database. For more information about using Hue with the Cloudera Operational Database service, see Cloudera Operational Database Hue access.
Running applications on Data Hub and COD
Cloudera Operational Database supports applications written in these supported languages using Apache Phoenix. You can also develop Apache HBase applications using the native HBase APIs for Java. We will cover more about developing applications and some sample applications you can use in the next few blog posts.
Cloudera Operational Database (COD) experience provides easy access to client connectivity information from the user interface. For more information, see Client connectivity information for compiling your application against your COD. For more information, see Using Apache Phoenix to Store and Access Data.
In CDP Private Cloud Base, you can find this information from the Apache Knox user interface if you want to connect to the Phoenix Query Server (PQS) through Apache Knox, or use JDBC drivers and Phoenix client JARs present in the following location in a cluster node with a phoenix-gateway role /opt/cloudera/parcels/CDH/lib/phoenix.
Conclusion
In the next posts, we will look at development considerations and building applications including sample applications.
You can see some existing sample applications and documentation for Cloudera Operational Database in Data Hub and Cloudera Operational Database experience dbPaaS solution in the following links:
- Cloudera Operational Database experience overview
- Cloudera Operational Database quick start
- Getting Started with Operational Database Data Hub template
- Building a Machine Learning Application With Cloudera Data Science Workbench And Operational Database
Editor's Choice

