

Introduction
A Convolutional Neural Network (CNN) is a class of deep, feed-forward artificial neural networks most commonly applied to analyzing visual imagery. The architecture of these networks was loosely inspired by biological neurons that communicate with each other and generate outputs dependent on the inputs. Though work on CNNs started in the early 1980s, they only became popular with recent technology advancements and computational capabilities that allow the processing of large amounts of data and the training of sophisticated algorithms in a reasonable amount of time. Some of the applications of CNNs include AI-based virtual assistant, automatic photo tagging, video labeling, and self-driving cars. This blog assumes that you have a basic knowledge of neural networks. You can also check out Introduction to convolutional neural networks, which covers everything you need to know for this post.
Why convolutional neural networks are useful
Many of you are familiar with the classic use case of CNN in image classification. For example, a CNN can be used to classify whether an image is a bird or a cat. Sounds simple, right? Why can’t regular neural networks solve the same problem? Here are some of the reasons:
Large image size: Images today are higher resolution. If you consider an image with a size of 224×224 and 3 channels, it corresponds to 224x224x3 = 150528 input features. A typical neural network with a hidden layer of 1000 nodes will have 150528×1000 parameters in the first layer itself, which is a huge computation overhead for the network.
Translation invariance: If you’re training a model to detect a bird, it should be able to detect it regardless of where it appears in an image.
Convolutional neural networks help to solve these problems. Let’s understand how CNNs work.
Convolution layers are based on the convolution mathematical operation. Convolution layers consist of a set of filters that is just like a two-dimensional matrix of numbers. The filter is then convolved with the input image to produce the output. In each of the convolution layers, we take a filter and slide the filter across the image to perform the convolution operation. The main agenda of the convolution operation is matrix multiplication of the filter values and pixels of the image, and the resultant values are summed to get the output.
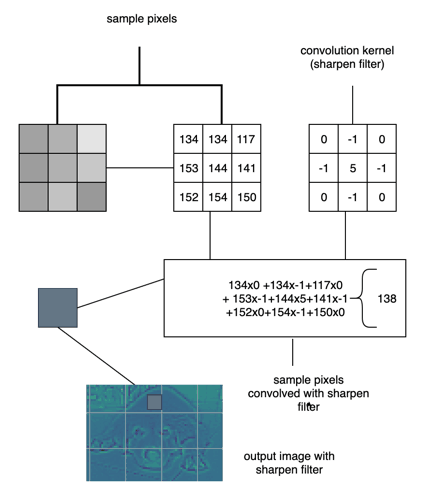
Fig1 : Convolution operation using a section of image and 3×3 filter
How are convolution layer operations useful?
CNN helps us look for specific localized image features like the edges in the image that we can use later in the network Initial layers to detect simple patterns, such as horizontal and vertical edges in an image; and deeper layers detect complex patterns.
Here’s an example of what the vertical edge detection looks like:

Now that we know how image convolution works, and why it’s useful, let’s see how it’s actually implemented.
Convolutional neural network architecture
The convolution layer is the building block of CNN. It is responsible for carrying the main portion of the CNN’s computational load.
The pooling layer helps in reducing the spatial size of the representation, which decreases the required amount of computation and weights. The most popular process is the max pooling, which reports the maximum output from the neighborhood. Pooling provides some translation invariance, which means that an object would be recognizable regardless of where it appears on the frame.
The fully connected layer (FC): Neurons in this layer have full connectivity with all neurons in the preceding and succeeding layer, as seen in regular feed-forward neural networks. This is why it can be computed as usual by a matrix multiplication followed by a bias effect. The FC layer helps map the representation between the input and the output.
Layers dealing with nonlinearity
Since convolution is a linear operation, and images are far from linear, nonlinearity layers are often placed directly after the convolution layer to introduce nonlinearity to the activation map.
There are several types of nonlinear operations, the popular ones being:
Sigmoid: The sigmoid nonlinearity has the mathematical form f(x) = 1 / 1 + exp(-x). It takes a real-valued number and squeezes it into a range between 0 and 1. Sigmoid suffers a vanishing gradient problem, which is a phenomenon when a local gradient becomes very small and backpropagation leads to killing of the gradient.
Tanh: Tanh squashes a real-valued number to the range [-1, 1]. Like sigmoid, the activation saturates, but unlike the sigmoid neurons, its output is zero-centered.
ReLU: The Rectified Linear Unit (ReLU) computes the function ƒ(κ)=max (0,κ). In other words, the activation is simply threshold at zero. In comparison to sigmoid and tanh, ReLU is more reliable and accelerates the convergence by six times.
Designing a convolutional neural network
Now that we understand the various components, we can build a convolutional neural network. We will be using CIFAR10, which is a dataset consisting of a training set of 50,000 examples and a test set of 10,000 examples. Each example is a 32×32 colored image, associated with a label from 10 classes.
Cloudera Data Science Workbench (CDSW) is a secure enterprise data science platform that enables data scientists to accelerate their workflow from exploration to production by providing them with their very own analytics pipelines. CDSW allows data scientists to utilize already existing skills and tools, such as Python, R, and Scala, to run computations in Hadoop clusters. If you are new to CDSW, feel free to check out Tour of Data Science Work Bench to start using it and setting up your environment. You will need to install TensorFlow, because you are going to run Keras on a TensorFlow backend.
Our convolutional neural network has the architecture as follows:

Fig 3: Architecture of the CNN model used in implementation
We have used data augmentation in fitting the training data to the model. We have also used batch normalization in our network, which saves us from improper initialization of weight matrices by explicitly forcing the network to take on unit Gaussian distribution.
Conclusion
Excited to build the model from scratch? Learn how to build CNN model by completing the tutorial Building a Convolutional Neural Network Model. You will be able to improve accuracy by modifying the architecture and parameters.
Editor's Choice


This post is very simple to read and appreciate without leaving any details out. Great work!
data science training in malaysia