



We are excited to announce the general availability of Apache Iceberg in Cloudera Data Platform (CDP). Iceberg is a 100% open table format, developed through the Apache Software Foundation, and helps users avoid vendor lock-in. Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP)—including Cloudera Data Warehousing (CDW), Cloudera Data Engineering (CDE), and Cloudera Machine Learning (CML). These tools empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and analytic engines. There’s zero effort required by companies to get the benefits of Iceberg as part of CDP. No more lock-in, unnecessary data transformations, or data movement across tools and clouds just to extract insights out of the data.
As the first hybrid data platform to offer an open data lakehouse, CDP enables multi-function analytics at petabyte scale on both streaming and stored data in a cloud-native object store across multiple clouds and on premises. This allows our customers the freedom to choose their preferred analytic tool. With Cloudera’s vision of hybrid data, enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. With Shared Data Experience (SDX) which is built in to CDP right from the beginning, customers benefit from a common metadata, security, and governance model across all their data.
Why integrate Apache Iceberg with Cloudera Data Platform?
At Cloudera, we are unambiguous about our commitment to openness and interoperability. This has driven our many significant contributions to innovation in communities like Apache Hive, Apache Spark, Apache Nifi, Apache Impala, Apache YuniKorn, and many more. In February 2022, we introduced Apache Iceberg as a technical preview within CDP.
Over the past decade, Cloudera has enabled multi-function analytics on data lakes through the introduction of the Hive table format and Hive ACID. The lakehouse pattern has evolved to the cloud, however, it still remains driven by table formats that are tied to primary engines, and oftentimes single vendors. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the data lake, without vendor lock-in. Organizations want modern data architectures that evolve at the speed of their business and we are happy to support them with the first open data lakehouse.
Apache Iceberg, now included as part of CDP, brings significant benefits to a modern data architecture, including:
- In-place table evolution, covering schema and partition changes, as a single command and not a laborious week-long process
- Time travel with point-in-time queries for forensic visibility and regulatory compliance capabilities
- Concurrent multi-function analytics to deliver end-to-end data lifecycle needs, from edge to AI
- Performance: Improved performance with aggressive partitioning to handle very large-scale data sets
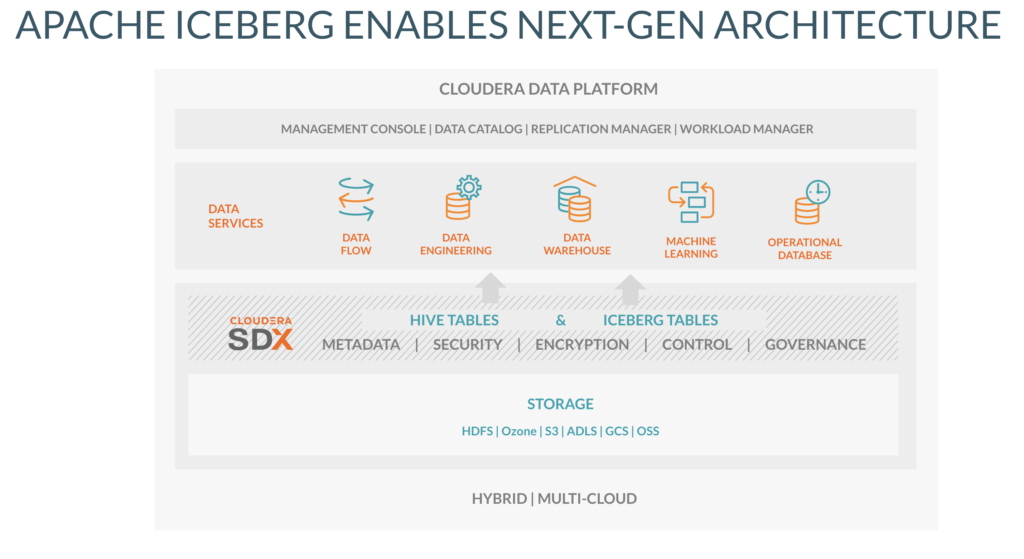
CDP provides the fastest and easiest path to Iceberg
We integrate Iceberg right into CDP’s SDX layer, so customers can easily use Iceberg and get all the productivity and performance benefits of the open table format right out of the box. Customers use a metadata-only migration in a single command, without touching any of the underlying large data sets. This is a huge accelerator to adoption.
Supercharge your data lakehouse, make it open
The data lakehouse is not new to Cloudera or our customers. For example IQVIA uses Cloudera to bring together more than two petabytes of data from 250 data warehouses worldwide – spanning Oracle, IBM Netezza, and Teradata systems – into a global, multi-tenant data lake on which they run their analytics. IQVIA has been leveraging the Hive open table format and Cloudera’s pre-integrated, multi-function analytics platform for more than five years. But the current data lakehouse architectural pattern is not enough. We see that companies need a platform across the full data lifecycle that can deliver multiple advanced analytics use cases with complete data in motion and operational database offerings. This is the open data lakehouse, which only Cloudera can offer in a hybrid data platform.
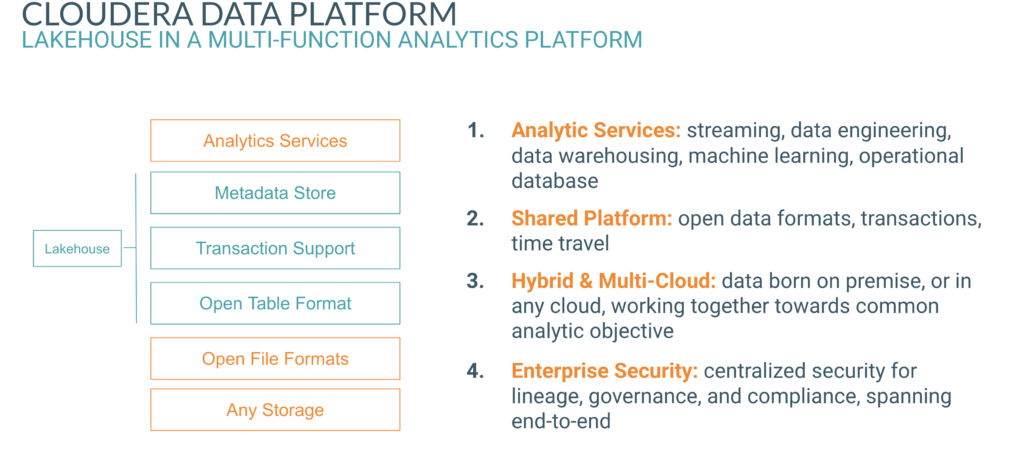
With Apache Iceberg in CDP, Cloudera leads beyond the data lakehouse with an open ecosystem of data and community, combined with enterprise hardening and performance. Our technical preview customers have shared the following feedback:
- Teranet: “After evaluating all the major open-source storage frameworks to build our lakehouse, we chose Apache Iceberg because it’s 100% open, feature rich, and has strong community engagement. Now with Iceberg, CDP supports an open data lakehouse architecture that future-proofs our data platform for all our analytical workloads. We selected change data capture as our first use case on Iceberg. With frequent updates to our data lake, we aim to accelerate reporting and business intelligence, giving our business teams access to current insights. Partition evolution is also a critical capability for us, guaranteeing superior query performance for large-scale data engineering and BI workloads,” says Steve Brackenbury, systems architect at Teranet.
- Modak Nabu: “Modak’s partnership with Cloudera enables us to assist our customers in deploying a lakehouse architecture that unifies all their data while providing common security and governance for any analytic use case—AI, machine learning, SQL, business intelligence reports, dashboards, and more. By certifying Modak Nabu with Cloudera’s CDP Iceberg table format, enterprise customers can accelerate data ingestion, curation, and consumption at a petabyte-scale for any data, resulting in simplified data management and faster data access,” says Daniel Mantovani, head of innovation at Modak Analytics.
Customers have leveraged partition evolution capabilities through CDP and realized over 10x query performance benefits by using finer-grained partitions on their data. They can do this without needing to regenerate or modify any of the underlying data.
Our integration of Apache Iceberg supercharges CDP’s capabilities beyond the data lakehouse. We can handle any data anywhere, in hybrid and multi-cloud. We work where your data is born, where it lands, and where it’s used.
To learn more:
- Watch our conversation about Emerging Data Architectures: An Apache Iceberg perspective by Ram Venkatesh, CTO of Cloudera; Ryan Blue, co-founder and CEO of Tabular; and Anjali Norwood, engineering manager at Netflix, as we discuss the benefits of Iceberg and open data lakehouses.
- Read why the future of data lakehouses is open
Try Cloudera Data Warehouse (CDW), Cloudera Data Engineering (CDE), and Cloudera Machine Learning (CML) by signing up for a 60 day trial, or test drive CDP. If you are interested in chatting about Apache Iceberg in CDP, let your account team know. As always, please provide your feedback in the comments section below.
Thank you to all Cloudera contributors for this article: Navita Sood, Peter Vary, Zoltan Borok-Nagy, Imran Rashid, Justin Hayes, Priyank Patel
Editor's Choice

