

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
What Customers Are Telling Us
We recently unveiled our Open Hybrid Architecture Initiative where Arun articulated the vision in his blog. We are excited by the huge interest from our customers and analyst community and we want to provide a closer view. We are starting to hit an equilibrium in the market. The cloud model is great for agility and time to deployment and works well for ephemeral workloads. The on-prem model provides a more predictable cost structure and suited for long-running workloads. Our customers are now asking us to bring “cloud” to the data, whether the data sits on-premises or in the cloud.
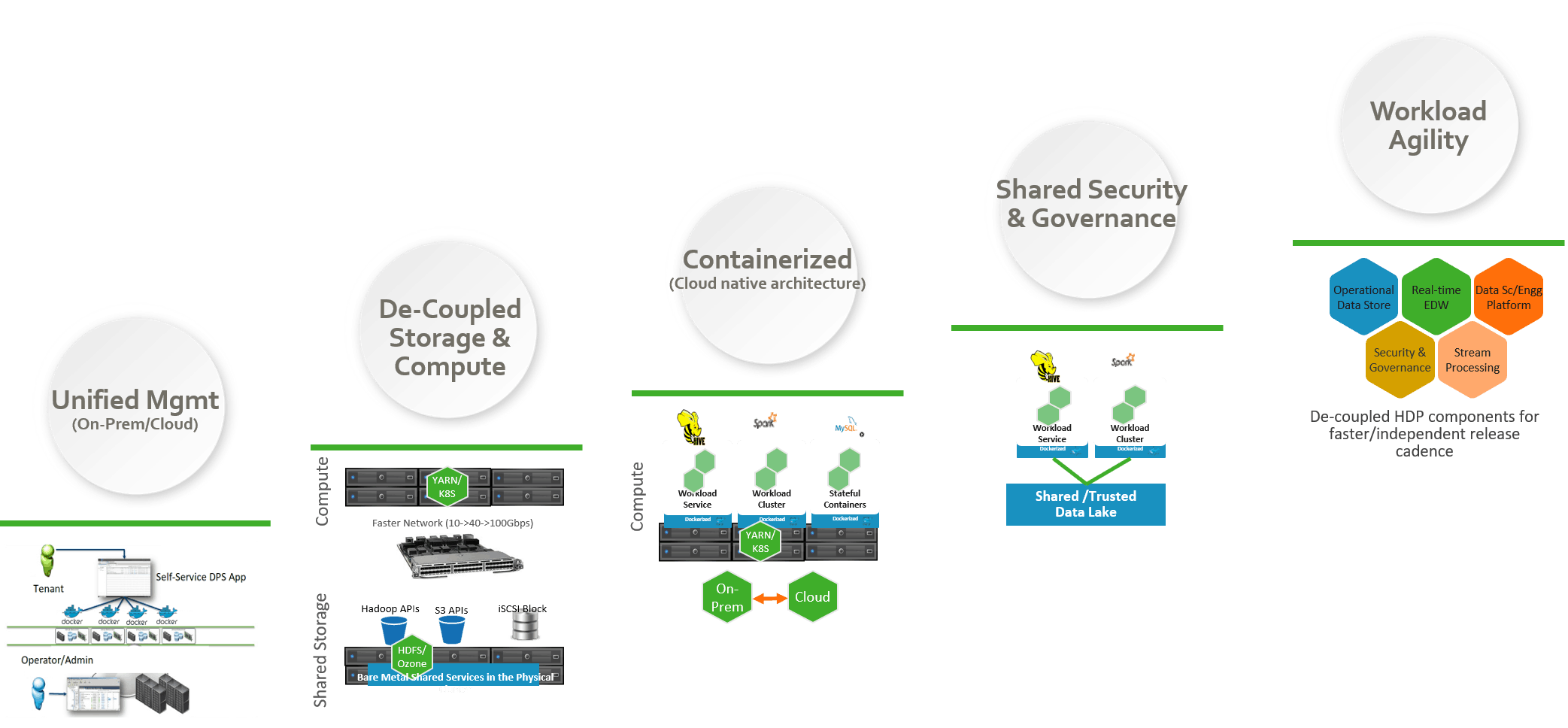
First, we want to capture the key tenets driving our Open Hybrid Architecture.
- Unified Management (across On-Premise and Cloud) Our customers are on a data journey and the choice of the deployment model is driven by the use case. We have customers who want the best of both worlds-on-premises and multiple cloud providers. Today, they are doing analytics on-premises. Tomorrow, they want to explore a cloud provider for running deep learning workloads. The day after tomorrow, they want to bring some of those workloads back to on-premises to get a more predictable cost pattern. Our customers are looking at us to help them with the hybrid cloud journey with a single unified interface. They are also looking for persona focused experiences now that the big data environment is used by thousands of data analysts, data engineers, data scientists. We want to provide a self-service user interface so that we can hide the infrastructure complexities and let the tenants focus on the business problem.
- Choice of De-coupled Storage and Compute We are seeing a consolidation of various silos of data such as big data, archive data, backup into a single unified storage with multi protocol access (S3 API, Hadoop API, NFS, iSCSI). S3 interfaces provide portability of applications between on-premises and in the cloud. We are also seeing wide range of use cases -each with a different compute to storage ratio. Networking switches have 10Gbps, 40Gbps, 100Gbps interfaces with better flow control for data intensive workloads unlike a decade ago. All these are leading to separation of compute and storage where each layer can scale independently. We will caveat with the statement that we still see a lot of customers who prefer access to local storage for a certain category of applications and in that case, it makes sense to keep storage and compute coupled in the same server. Considering our legacy, we are in the best position to provide a storage architecture that can scale to trillions of files/objects, provide strong consistency (unlike Amazon Simple Storage Services (S3) and many other object storage solutions out there, which requires the applications to build a consistency layer) and most importantly provide options to do both coupled and de-coupled compute and storage.
- Containerized A large majority of our customers want packaging isolation and multi-tenancy with an easy to use interface. We launched HDP 3.0.0 back in July, 2018 to run third party containerized workloads such as TensorFlow or to lift and shift custom dockerized apps to our HDP clusters. Now, we want to go to the next level- containerize our own components such Enterprise Data Warehouse (EDW), Data Science & Engineering Platform etc. There are plenty of benefits. We can now create a workload on-demand in minutes. In the past, this process required months of coordination with server admins and then, setting up a new cluster. This gives us the cloud like agility on-premises and allows us to streamline to a common architecture so that our EDW solution can run on-premises and in the cloud without any architectural overhaul.
- Shared Security and Governance Now that, we can deploy containerized workloads with cloud like agility, we want a shared and persistent security and governance layer to enforce access control and data governance centrally. As the data is distributed across Hadoop file-system and cloud object storage, we want to have a common security and governance control. As we scale our data environment to tens of billions of files and share across the organization, there is a need to have departmental level security domain- think about a “logical” data lake for that department with its own security and governance control.
- Workload Agility This is the ultimate holy grail of Open Hybrid Architecture. Our data environment exists so that various processing workloads can run to get the insights or signal from the noise and our customers can get drive real business transformation at their organizations. Many of the workloads such as EDW, Data Science & Engineering Platform have different release cadence. Our architecture enables us to easily change the software revision of the component independent of the underlying infrastructure, avoiding a monolithic giant upgrade. We can provide on-demand workload creation with a self-service persona focused user interface for the thousands of tenants in the big data environment.
All these lead to us to a consistent hybrid architecture design across both cloud and on-premises as outlined in the blog.
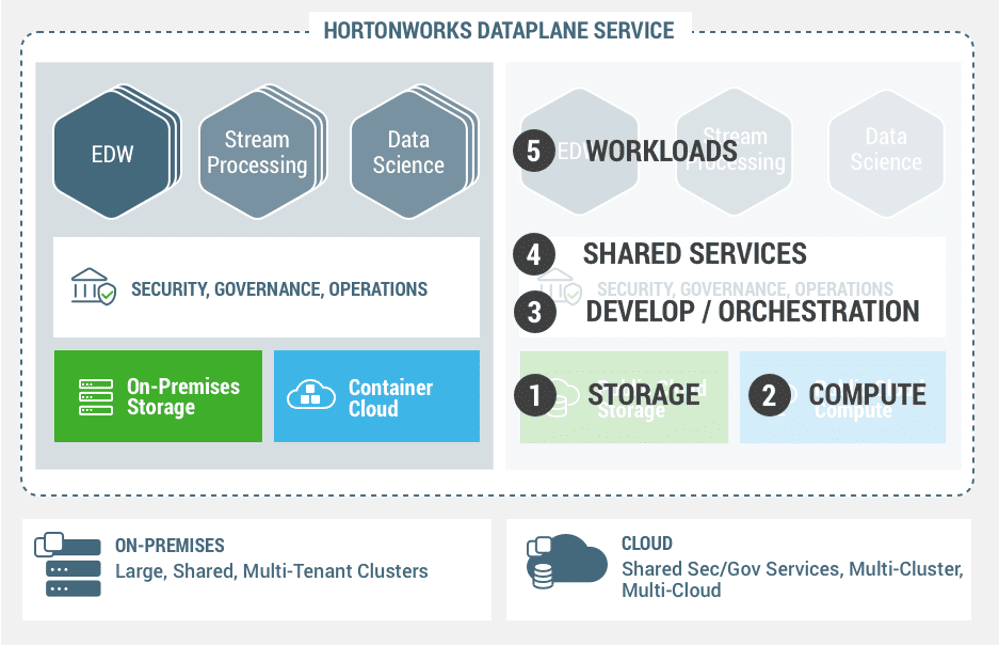
High Level Concepts
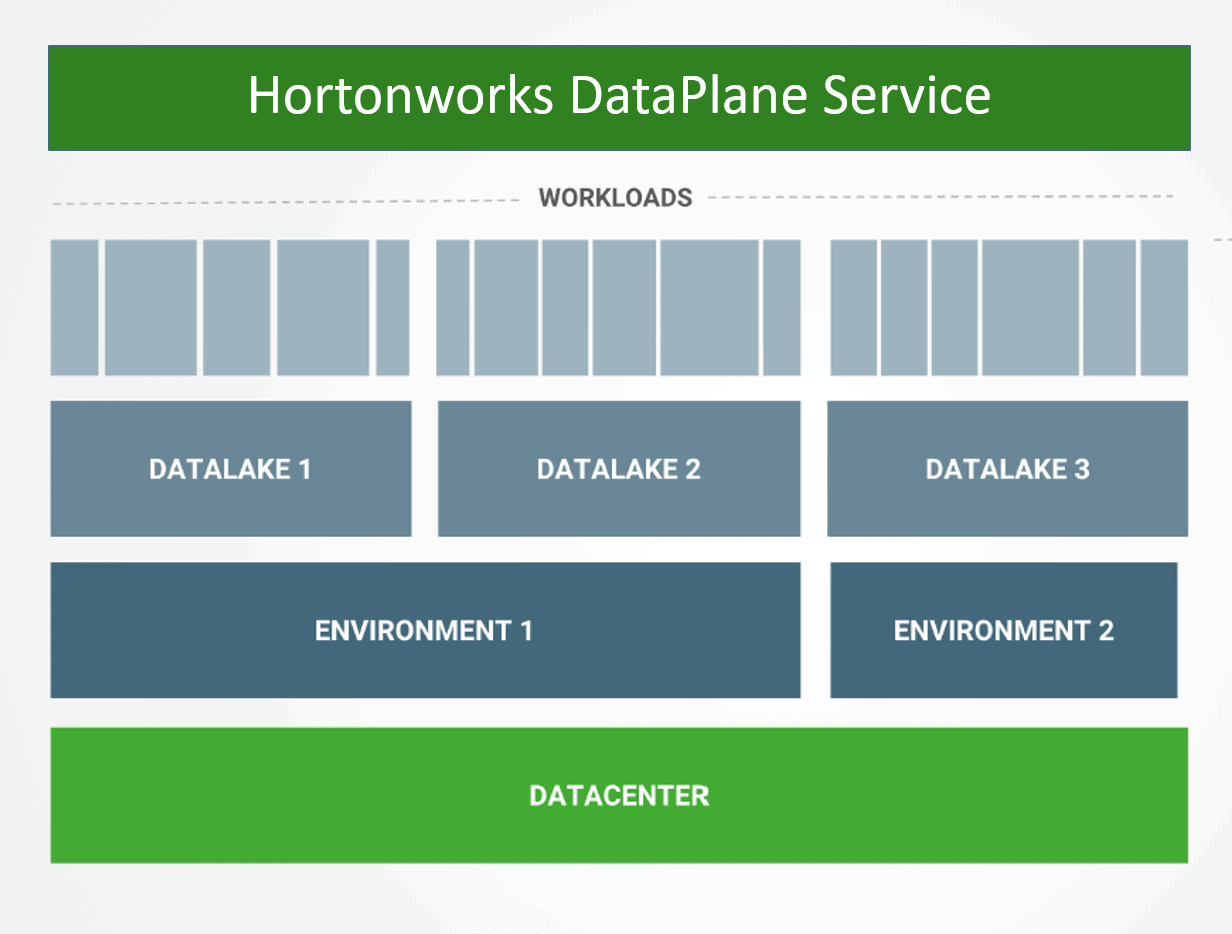
There can be multiple environments or a single environment in a data center. An environment comprises of storage, compute, security and governance services and operational services (logs, metrics). We allow choices to our customers. A customer can have a 100 node environment where storage and compute are coupled together in the same server to benefit from data localization. Alternatively, we can allow the customer to dedicate 50 nodes to a storage environment and 50 nodes to a compute environment so that storage environment and compute environment can scale independently. The storage environment scale to tens of billions of files, while the compute environment provides the containerized architecture to run the workloads on.
Now, our customer can have multiple departments who want to share the environments while having their own security and governance controls and not letting their data sets visible to each other (e.g. Healthcare vertical). There can be customers who want to join data sets across departments and in that case, they can have just one data lake mapped to a single environment.
There can be hundreds of tenants in a department who need to solve a business problem and need a workload (such as EDW, Data Science). The admin or department level architect can provide access control to the data sets and create a workload for the tenant within the compute environment using containers. Now, the tenant can access the persona focused user interface to access the data sets and solve his/her business problem. All the user interface and workload creation happens with the magic of our DataPlane Services.
Please stay tuned for our blogs in this blog series. We will give you a deeper dive into a demo flow to demonstrate an Open Hybrid Architecture implementation, using a real world business problem. We will also be doing deep dive into our storage, compute and other building blocks in this Open Hybrid Architecture series.
Editor's Choice

