

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Building on the vision and concepts outlined previously in Arun and Saumitra’s blogs, we wanted to show the Open Hybrid Architecture Initiative (OHAI) concepts in action, and see how they could be used to solve a data-driven business problem.
In this example, we’ll use look at how our Open Hybrid Architecture Initiative (OHAI) applies to an enterprise. Hortonworks Air Freight has a business problem to solve. They are a global logistics provider with hubs in San Francisco and Dallas, but they need to plan out their next hub on the east coast and want to use the data they have to support that decision.
Business Challenge- Hortonworks Air Freight

To better understand how our Open Hybrid Architecture Initiative (OHAI) can help tackle this problem, let’s first introduce the two primary personas: Linda from the Big Data Operations Team, and Tom from the Data Analytics Team. The image below outlines their current pain points, and we’ll look at how these can be solved with our new architecture.
Personas and Pain Points

Linda would like a way to see all of her data infrastructure, be it on-prem or cloud in one place and be able to move data and workloads between them easily. Being able to react quickly to business needs means having fine-grained control over scaling of storage and compute, and sometimes need dictates scaling one more than the other. Security, Governance, and Compliance are critical, and Linda needs a way to efficiently manage metadata and attach security policies to new datasets, services, and workloads. Finally, the most significant pain point is being able to give teams the right versions of services they need when they need them – without having to upgrade everything and impact every tenant.
Tom, on the other hand, needs new versions of tools as soon as they come out and needs them without heavy wait times and ticketing processes. His team is familiar with developing solutions that use containers for running workloads and managing dependencies and wants a system that allows them to use this experience and existing assets.
Now let’s look at Hortonworks Air Freight’s data infrastructure. They have an on-prem cluster with their operations data including billing, customer, flight operations, and cybersecurity data. They also have data in Azure for aircraft sensors, as well as a presence in AWS for their freight operations and logistics.
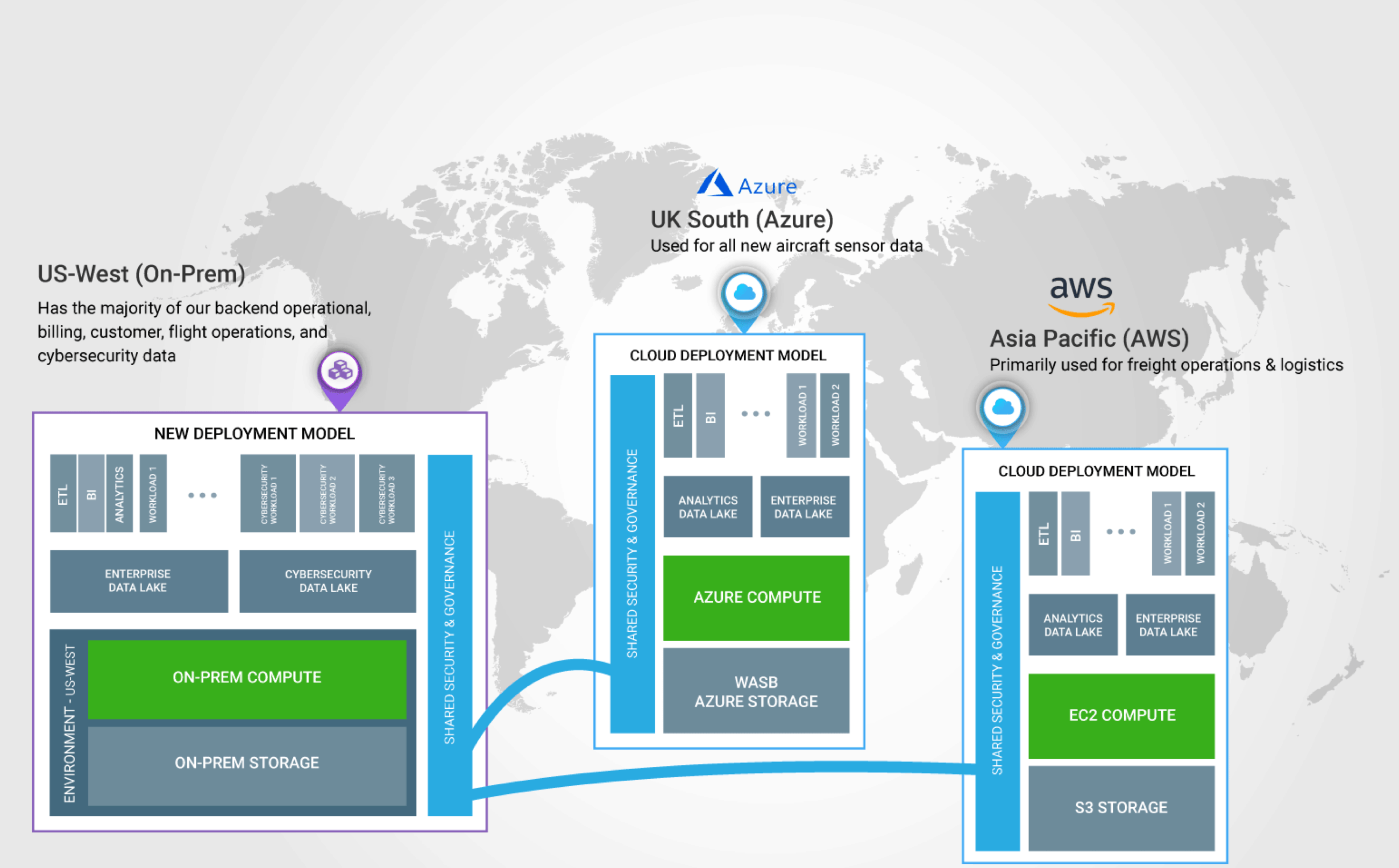
Given this architecture that takes advantage of multiple public cloud providers and on-prem resources, we’ll see how DataPlane and our Hybrid Architecture help Linda and Tom achieve their business objectives.

Linda, the Big Data Operations Admin, can log into DataPlane and see all of her Environments in one place, allowing her to quickly access specific environment details and monitor workloads running in that Environment.
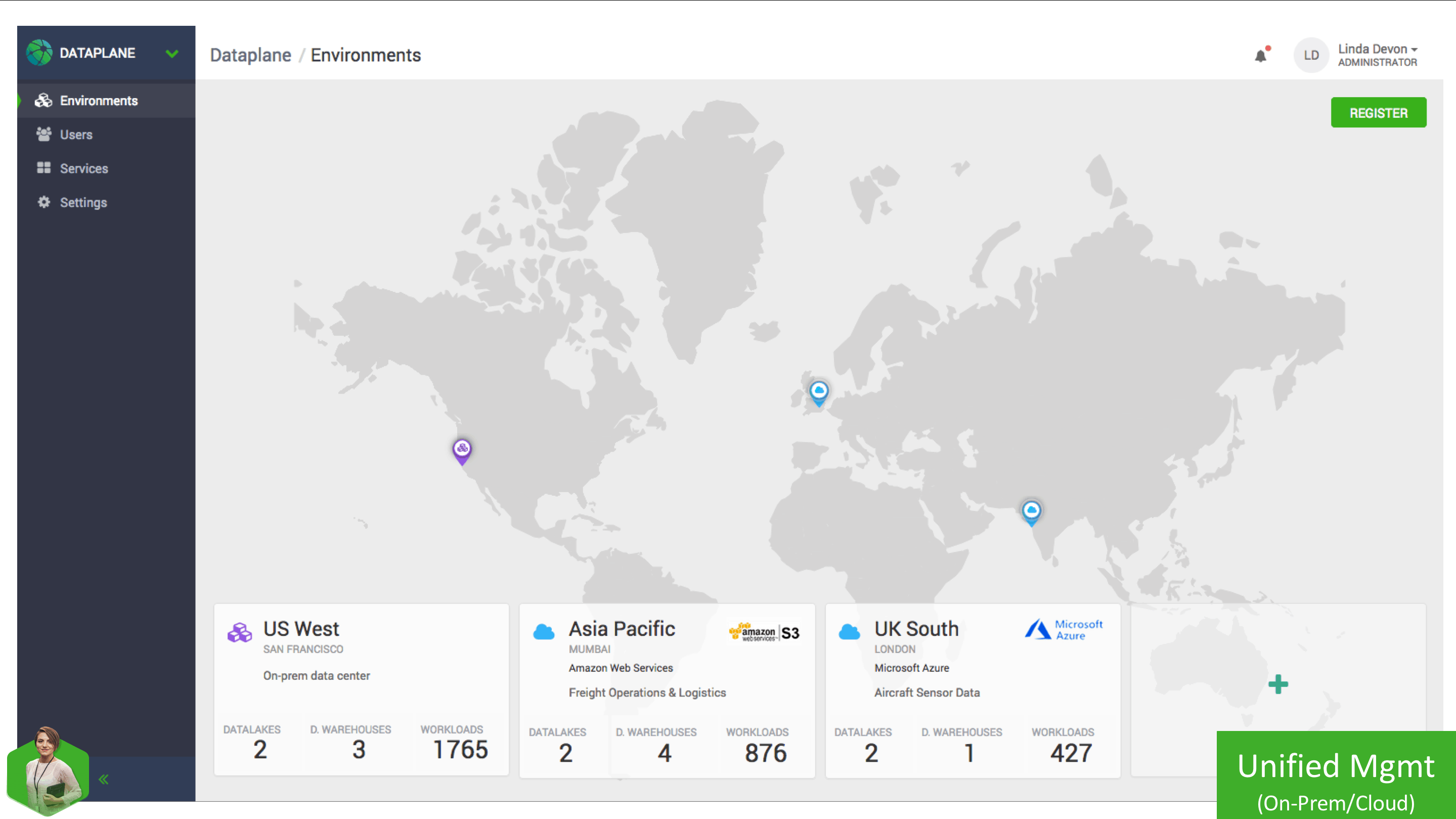
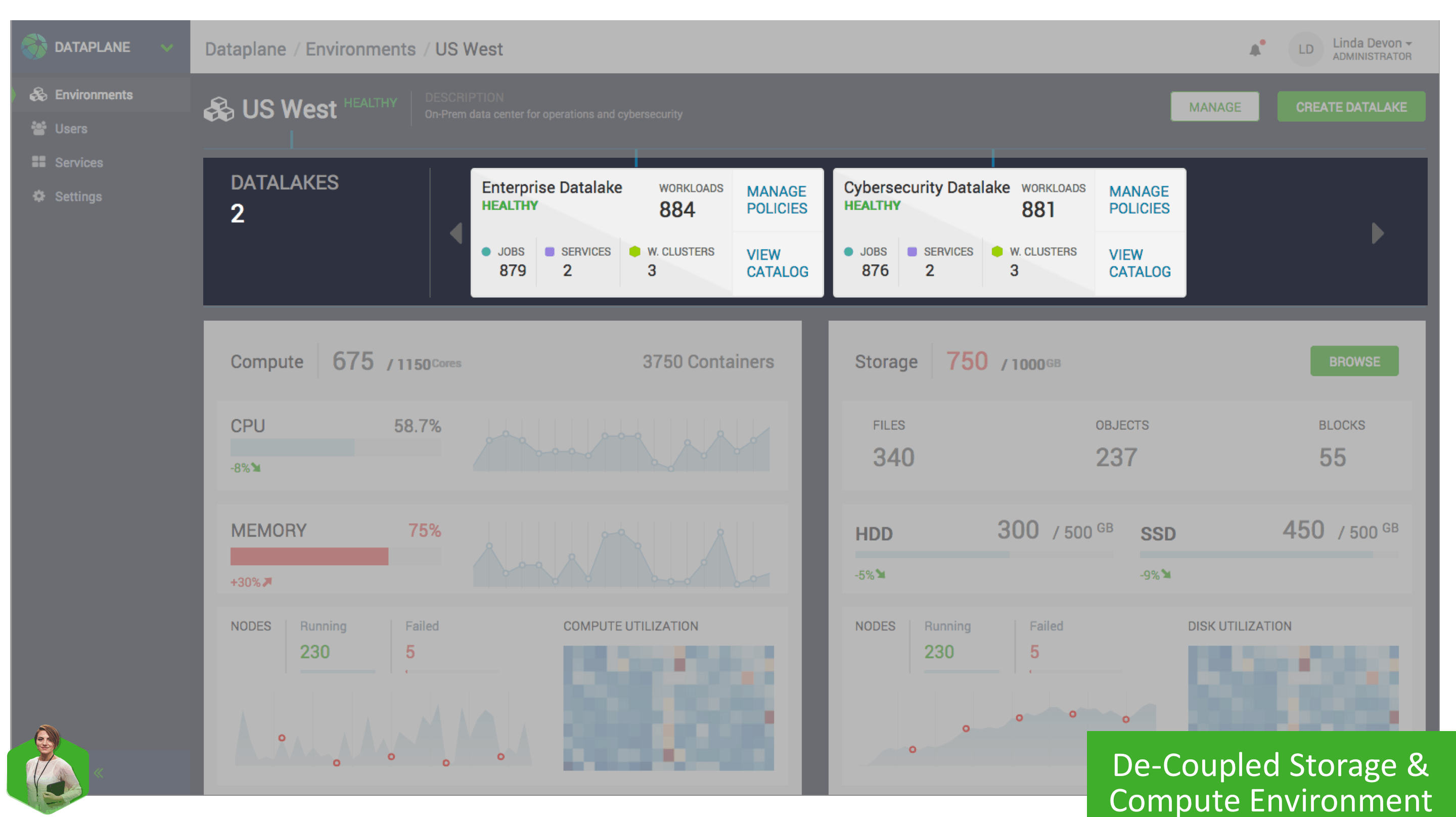
To get a better understanding of what is going on in each of these Environments, we’ll take a closer look at the US West on-premise Environment. By clicking on the environment, we can see a detail screen that shows vital information about the workloads, and Datalakes associated with this Environment.
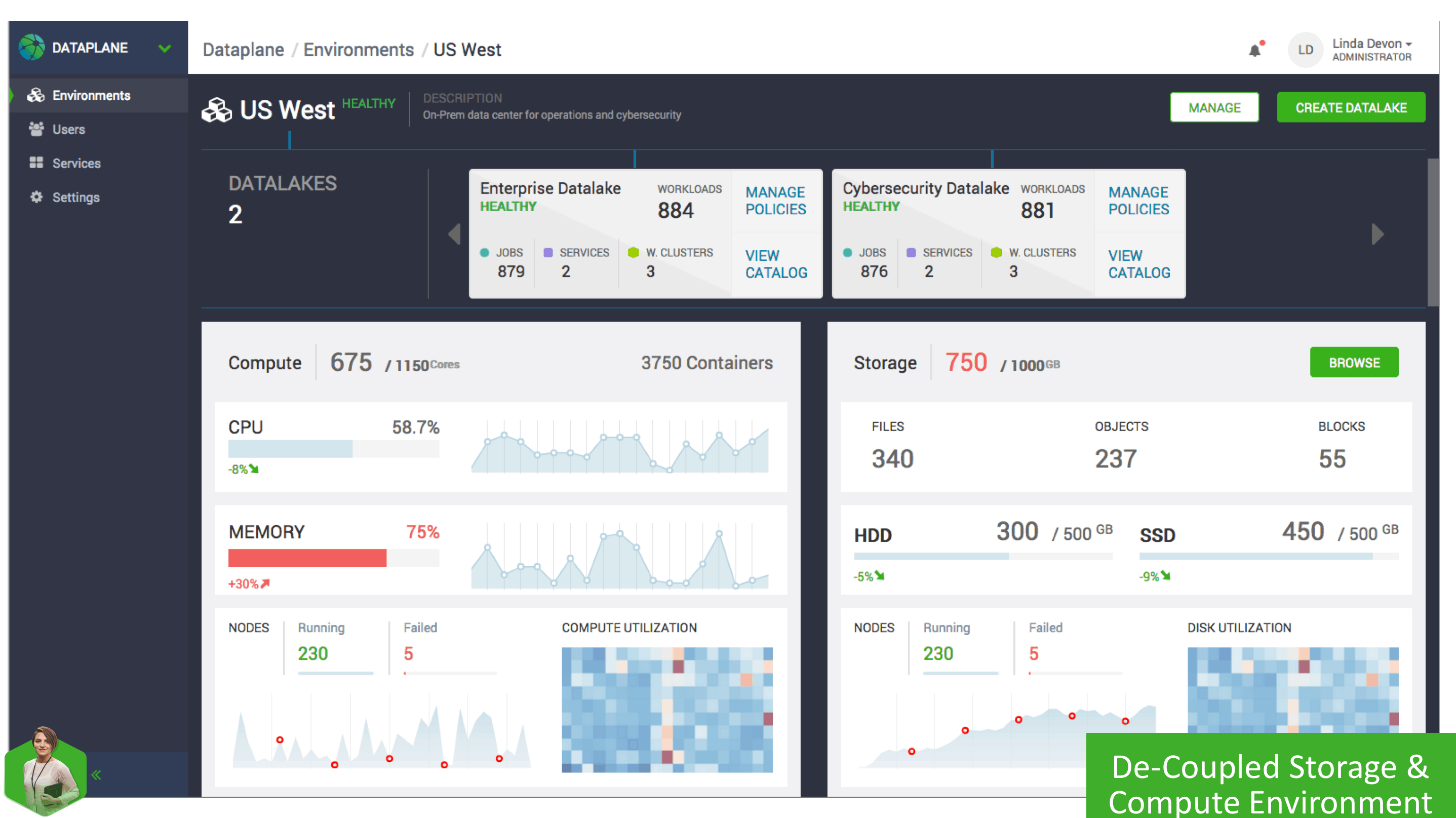
This Environment detail page shows relevant statistics, and metrics to get a high-level view of how the environment is functioning, how many containers are running, how data is being used, with trends across both compute and storage. One of the significant benefits of this new architecture is the ability to scale compute and storage independently, so if additional storage is required but not compute or v.v. you have the granularity and control to achieve it.
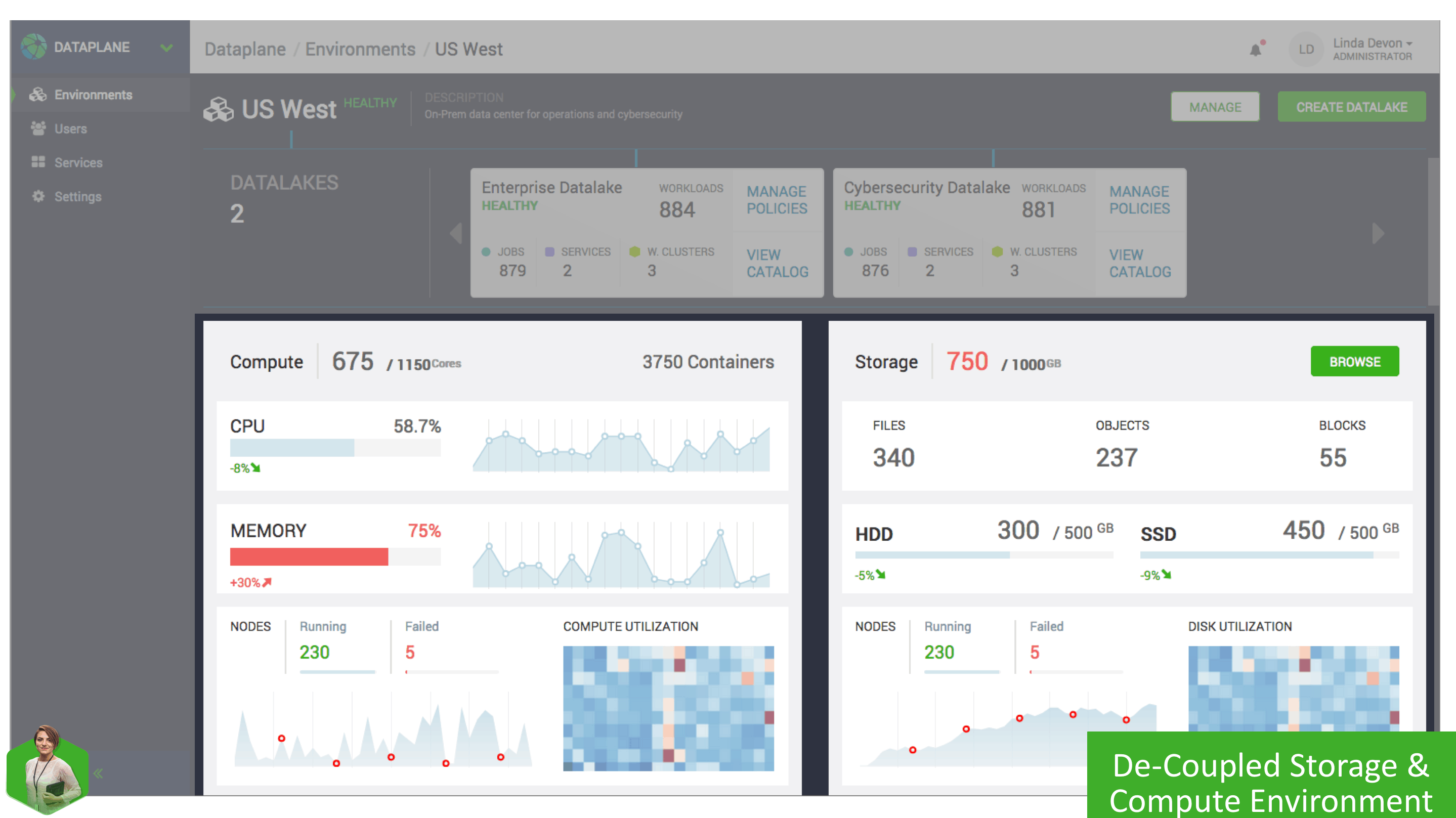
Each Environment can be associated with one or more Datalakes. A Datalake gives you a shared and persistent security and governance layer to enforce access control and data governance centrally. As data is distributed across Hadoop filesystems and cloud object storage, we want to have a common security and governance control and as you scale your data sets to tens of billions of files shared across multiple business units within your organization, there is a need to have departmental-level security domains – like a “logical” data lake for that department with its own security and governance controls.
Let’s take a closer look at one of our Datalakes. Each Datalake has security policies, metadata, and Warehouses attached to provide a central place to author security policies, browse and define metadata, and curate data sets.
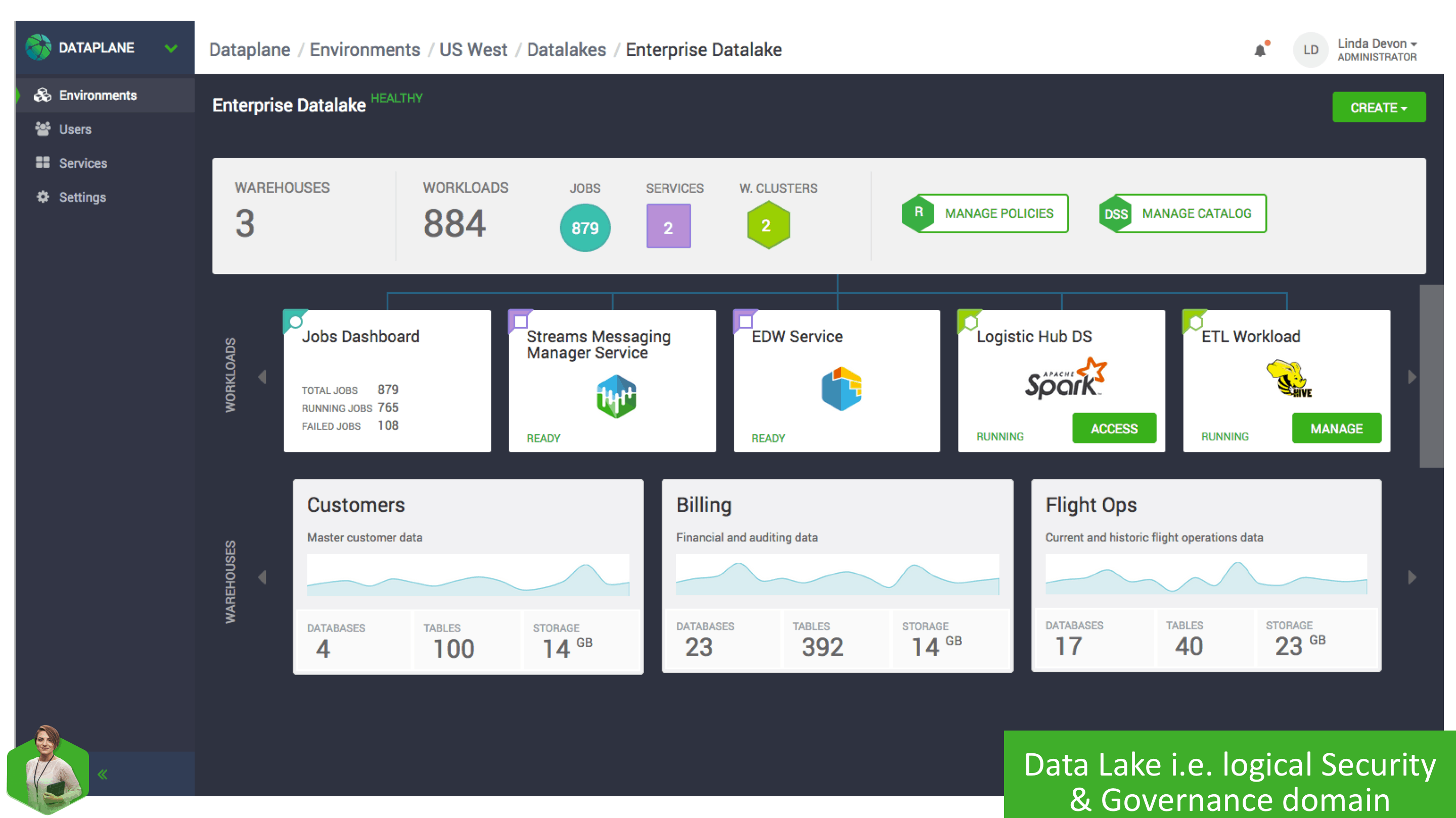
Each Datalake can be associated with multiple workloads. By associating a Datalake with a Workload, that workload automatically is attached to the security policies and metadata within it. This association makes it very easy to quickly spin up new Workloads without having to duplicate or redefine security policies and key schemas and metadata.

With all of these concepts in place, Linda can quickly provision a Workload (Data Science, EDW) in a few minutes.
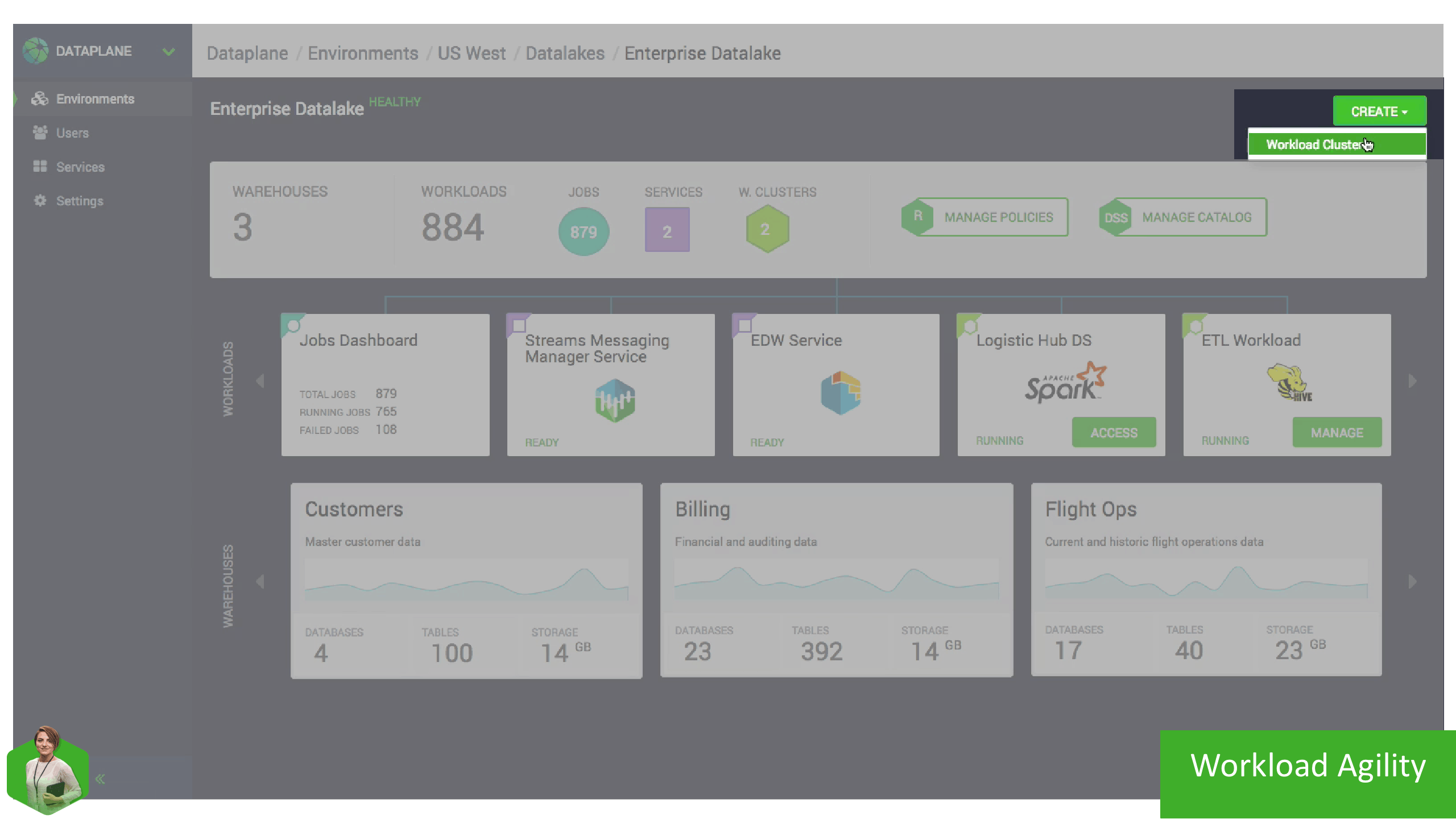
Linda can choose from multiple available versions for each Workload as soon as a new version becomes available, all integrated with Security & Governance services and able to access data in the Storage Environment (HDFS), reducing the time to deployment from months to minutes.
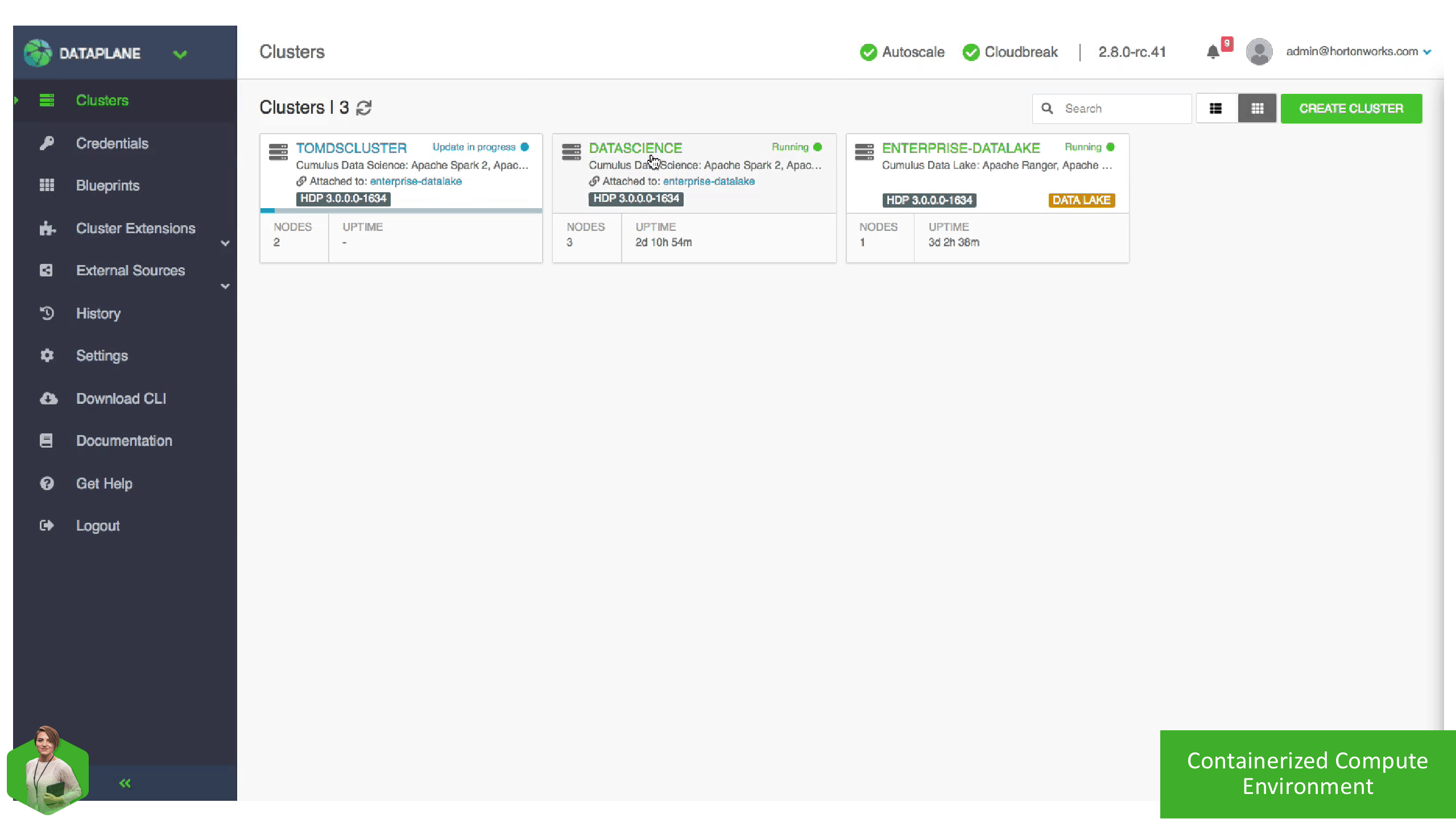
Given these capabilities, Linda can create what Tom needs in minutes, a working Spark and Zeppelin installation, now let’s see what he can do with it.

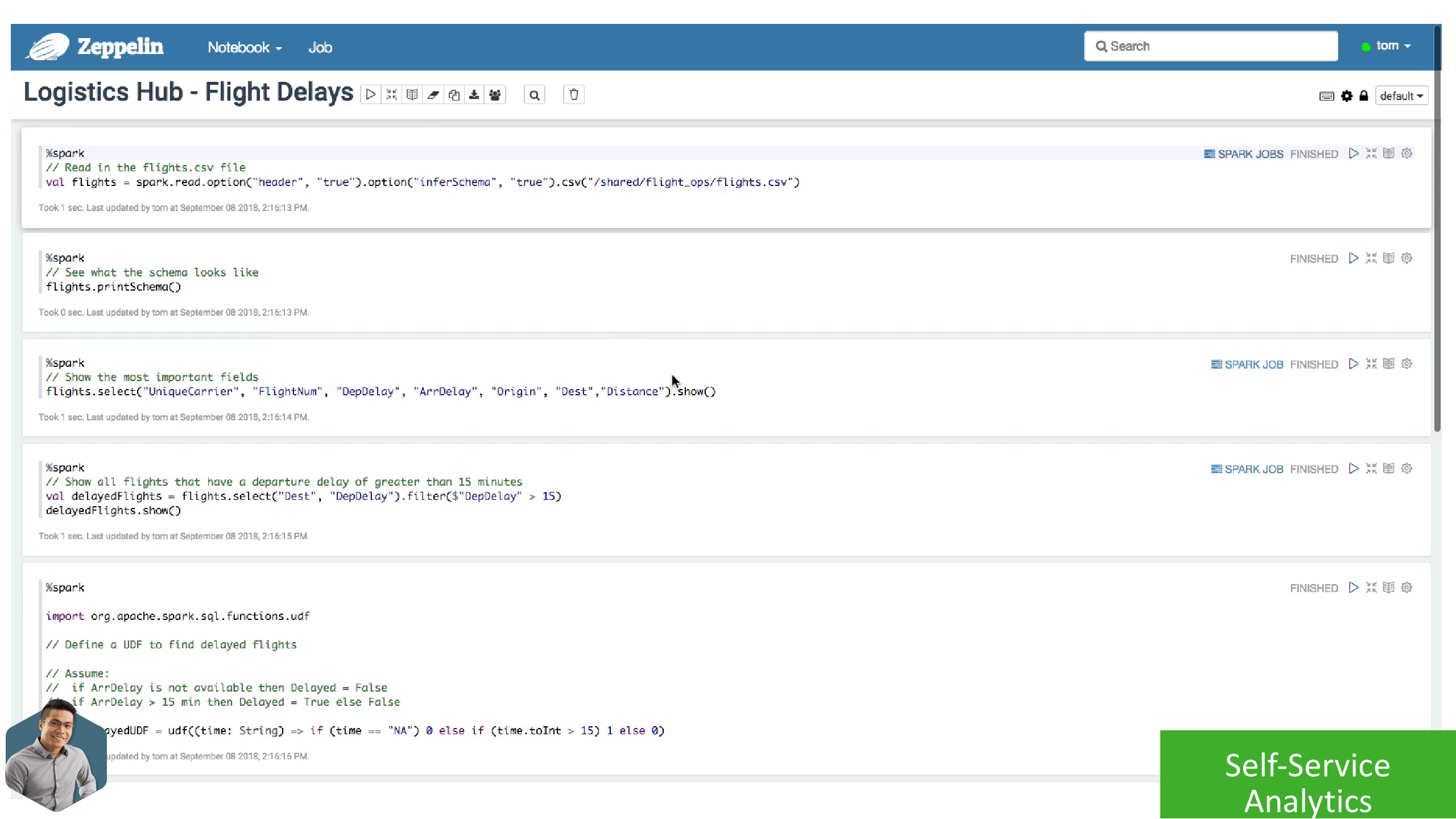
Tom now has access to a Workload Cluster with Spark, Hive, and Zeppelin. This Workload Cluster is attached to an existing Datalake, so it is automatically integrated with the shared Security & Governance services and has access to the data he needs to complete his analysis to identify the next best location for the logistics hub.
Tom can log in to Zeppelin with his corporate LDAP credentials, and complete his analysis using a secured and fully integrated cluster with the right versions of services he needed within minutes.
We hope this deeper dive into the concepts behind our Open Hybrid Architecture helped illustrate how business problems in today’s hybrid world can be solved. Please stay tuned for more deep dives into our storage, compute and other building blocks in this OHAI series.
Special thanks to our September spike team who worked so tirelessly to turn concepts and vision into reality: Akhil Puthenveettil Balan, Aravindan Vijayan, Attila Kanto, Babu Rao, Bikas Saha, Billie Rinaldi, Dipayan Bhowmick, Gabor Boros, Gopal Vijaraghavan, Gour Saha, Hemanth Yamijala, Jaimin Jetly, Jason Dere, Jayush Luniya, Jitendra Pandey, Krisztian Horvath, Prasanth Jayachandran, Priyanka Nagwekar, Richard Doktorics, Rupam Datta, Shane Kumpf, Siddharth Seth, Sunil Govindan, Sunitha Velpula, Wangda Tan, Arun Murthy, Gunther Hagleitner, Houshang Livian, Josh Elser, Madhan Neethiraj, Mahadev Konar, Manju Rao, Ram Venkatesh, Sanjay Radia, Shakil Malhotra.
Editor's Choice

