

Apache Hadoop Ozone is a distributed key-value store that can manage both small and large files alike. Ozone was designed to address the scale limitations of HDFS with respect to small files. HDFS is designed to store large files and the recommended number of files on HDFS is 300 million for a Namenode, and doesn’t scale well beyond this limit.
Principal features of Ozone which help it achieve scalability are:
- The namespace in Ozone is written to a local RocksDB instance, with this design a balance between performance (keeping everything in memory) and scalability (persisting the less used metadata to the disk) can be easily adjusted.
- Namespace and block space management are separated into two different daemons OzoneManager(OM) and StorageContainerManager(SCM) respectively. Each of these daemons can be scaled independently of each other.
- Unlike HDFS, Ozone block reports are reported via container reports which aggregate reports for multiple blocks in the container.
One of the primary goals of the Ozone project is to provide namespace scalability, at the same time retaining the fault-tolerance, security, performance, and scalability of the client.
Journey to 1 Billion keys, going beyond HDFS scalability limits
Reaching a billion objects in Ozone has been one of the significant milestones for the project. The data was populated using a custom job running on 5 nodes with 50 threads each. Ozone ran on an 11 node cluster (1 OM, 1 SCM & 9 Datanodes) and it took 56 hours to reach a billion objects, each of the objects is of 10KB in size. The reason to pick 10KB was to measure Ozone performance with small files.
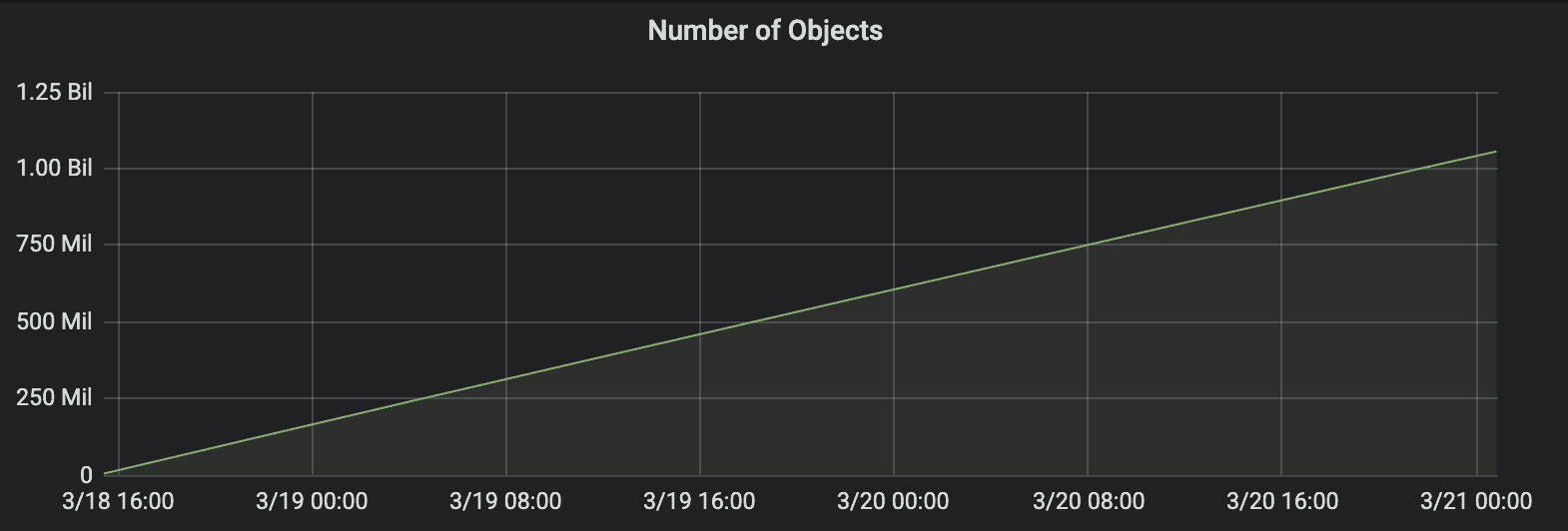
Ozone was able to write the objects at a sustained rate of ~5000 objects/sec, this further highlights the small file handling of Ozone, where it is able to provide the same throughput during the entire test.
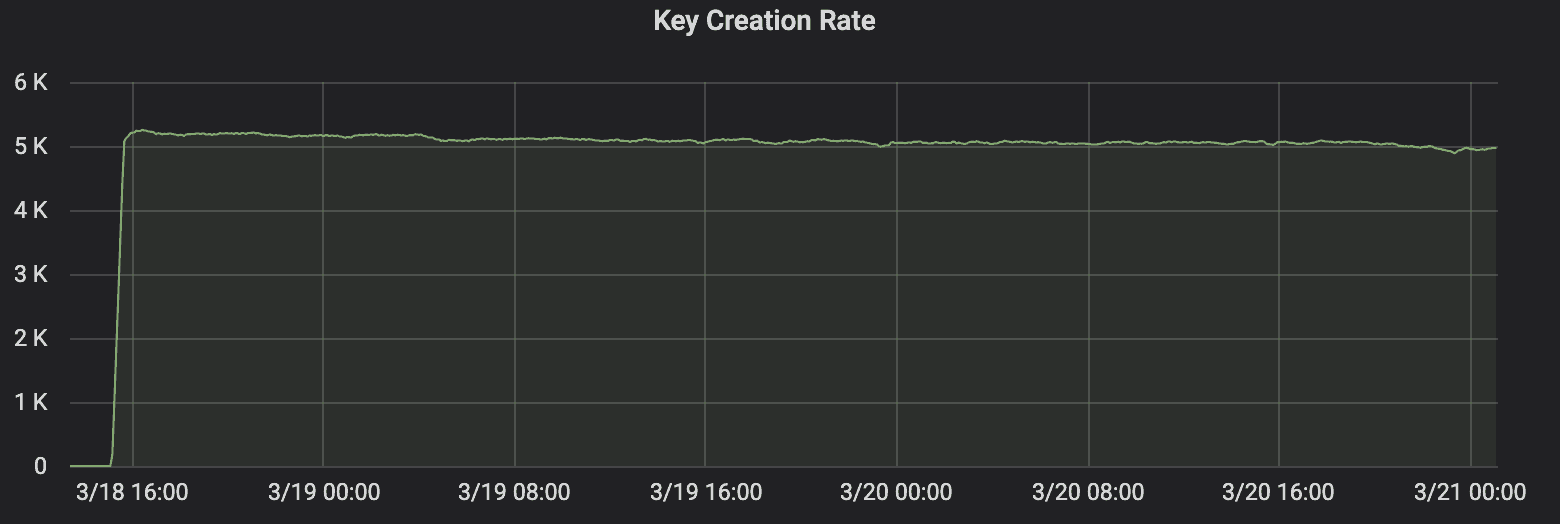
Some salient details
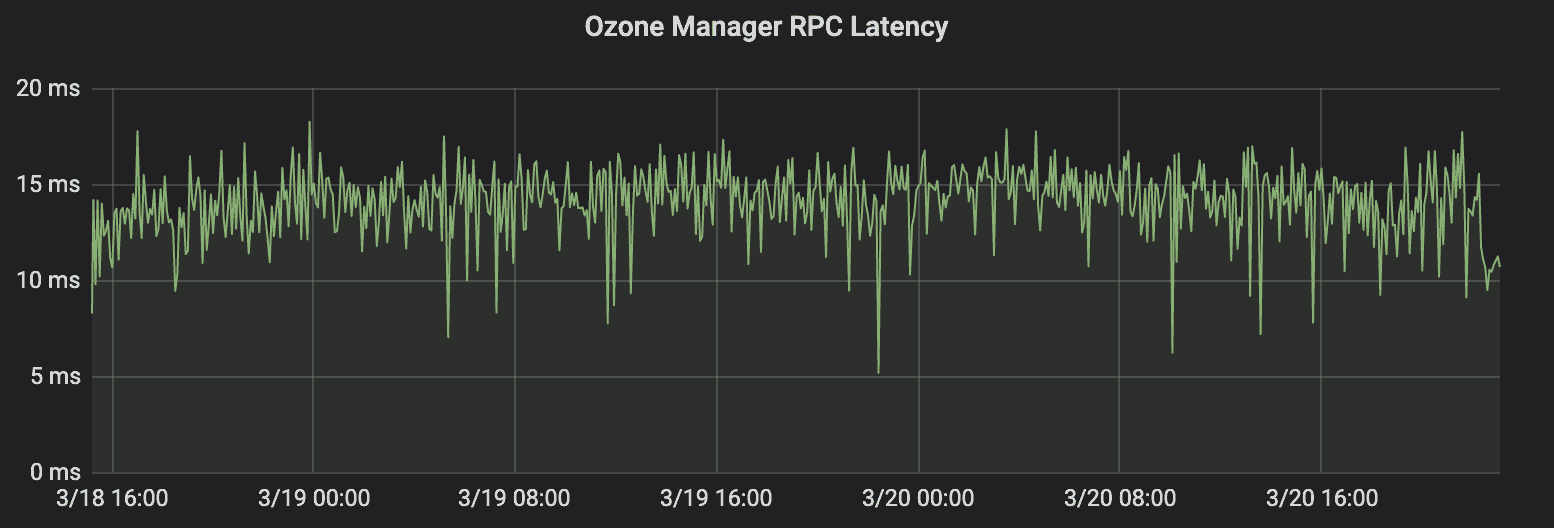
Sustained transactions from OzoneManger
Ozone Manager processed a total of 2 Billion transactions, with two transactions for each object (one for opening the file and another to commit the file). Ozone Manager(OM) processed these ops at ~12 ms latency throughout 1 billion objects. The constant latency also highlights the absence of any long GC pauses on the OzoneManager.
Small Metadata Overhead
A billion keys each of 10KB size were stored on 2121 5GB containers, this significantly reduces the block metadata for SCM from 1 billion blocks to be reported in HDFS versus the 2121 containers to be reported in Ozone. On the other hand, a billion keys on OM took a total of 127 GB space on the SSDs.
Test Environment
The test was run on Apache Hadoop Ozone 0.5.0 (Beta) release.
Hardware
The test was performed on AWS EC2 instance type m5a.4xlarge with SSD’s for OzoneManager and Storage Container Manager’s databases.
| Service | #Nodes | EC2 Instance Type | CPU | Memory | Storage | Network |
| Ozone Manager | 1 | m5a.4xlarge | 16 | 64 GB | 1 x 1 TB SSD | 10 Gbps |
| Storage Container Manager | 1 | m5a.4xlarge | 16 | 64 GB | 1 x 1 TB SSD | 10 Gbps |
| Datanode | 9 | m5a.4xlarge | 16 | 64 GB | 1 x 500 GB SSD 3 x 2 TB HDD |
10 Gbps |
Conclusion
HDFS’s known limitations around small files and namespace scale limits lead to underutilization of storage nodes, GC issues and instability of Namenode, and fragmentation of namespace for large data lake deployments. Ozone overcomes these limitations by handling billions of files of all sizes and thus enables large data lake deployments in a single namespace. Ozone architecture with higher scale, and with the support for object storage use cases, addresses the big data storage requirements in private cloud environments where disaggregated compute and storage is a rapidly emerging trend.
Further reading
- Introducing Apache Hadoop Ozone: An Object Store for Apache Hadoop
- Apache Hadoop Ozone – Object Store Overview
- Open Hybrid Architecture: O3, the New Rocket Ship
- Apache Hadoop Ozone – Object Store Architecture
Editor's Choice


Just to confirm, was this done with a replication factor of 3?
Yes, this was done with a replication factor of three.
Hadoop 3 Erasure Coding new feature does not provide an optimezed mechanism instead of replication factor 3? What is the point of asking about features that are already obsolete?