

Apache Impala is used today by over 1,000 customers to power their analytics in on premise as well as cloud-based deployments. Large user communities of analysts and developers benefit from Impala’s fast query execution, helping them get their work done more effectively. For these users performance and concurrency are always top of mind.
An important technique to ensure good performance and concurrency is through efficient usage of memory. If we can make better use of memory, less time is spent with queries queueing up waiting for free memory, so results come back faster. Similarly, with better usage of available memory more users can query the data at any given time, so more people can use the warehouse at the same time. The end result – happier users, and more of them.
This post explains the novel technique for how Impala, offered within the Cloudera Data Platform (CDP), is now able to get much more mileage out of the memory at its disposal.
Impala has always focused on efficiency and speed, being written in C++ and effectively using techniques such as runtime code generation and multithreading. You can read previous blog posts on Impala’s performance and querying techniques here – “New Multithreading Model for Apache Impala”, “Keeping Small Queries Fast – Short query optimizations in Apache Impala” and “Faster Performance for Selective Queries”.
Analytical SQL workloads use aggregates and joins heavily. Hence, optimizing such operators for both performance and efficiency in analytical engines like Impala can be very beneficial. We will now look into one of the techniques used to reduce peak memory usage of Aggregates and Joins by up to 50%, and peak node memory usage by 18% at the per-node level on a TPC-DS 10000 workload.
Hash Table
Both Aggregates and Joins in Impala use a Hash Table, and we will show how we reduced its size for the operation. The HashTable class implementation in Impala comprises a contiguous array of Bucket, and each Bucket contains either a pointer to data or a pointer to a linked list of duplicate entries named DuplicateNode.
These are the structures of Bucket and DuplicateNode (with a few details changed for simplicity):
struct DuplicateNode {
bool matched; // 1-byte
// padding of 7-bytes
DuplicateNode* next; // 8-byte pointer to next DuplicateNode
Data* data; // 8-byte pointer to data being hashed
};
struct Bucket {
bool filled; // 1-byte
bool matched; // 1-byte
bool hasDuplicates; // 1-byte
// padding of 1-byte
uint32_t hash; // 4-byte
// bucketData is a pointer to DuplicateNode or
// pointer to Data.
union {
Data* data; // pointer to data being hashed
DuplicateNode* duplicates;
} bucketData; // 8-byte
};
When evaluating the size for a struct, these are some of the rules for memory alignment, assuming 64-bit system:
- Memory address for individual members starts at memory address divisible by its size. So a pointer will start at memory divisible by 8, a bool by 1 and uint32_t by 4. Members will be preceded by padding if needed to make sure the starting address is divisible by their size.
- Size of struct will be aligned to it’s largest member. For instance, in both the structs above the largest member is a pointer of size 8 bytes. Hence, the size of struct will be a multiple of 8 too.
Based on the above rules, Bucket in the above snippet is commented with size occupied by every member and padding wherever required. Total size of the Bucket is 16 bytes. Similarly, the total size of DuplicateNode is 24 bytes.
We decided to reduce the size of the Bucket and DuplicateNode by removing bool fields from both, reducing the sizes to 12 bytes and 16 bytes respectively. However 12 bytes is not a valid size of Bucket, as it needs to be a multiple of 8 bytes (the size of the largest member of the struct). In such cases, we can use __attribute__ ((packed)) to ensure struct packing so that the size is 12 bytes.
How do we achieve removing these booleans, as they need to be present for every Bucket and DuplicateNode?
tl;dr: We decided to remove all bool members by folding them into a pointer that is already part of the struct.
Folding data into pointers
Intel Level 5 proposal 64-bit memory address

On 64-bit architectures, pointers store memory addresses using 8 bytes. But on architectures like x86 and ARM the linear address is limited to 48 bits long, with bits 49 to 64 reserved for future usage. In the future with Intel’s level 5 paging proposal (whitepaper), it is planning to relax the limit to 57-bit on x86, which means we can use the most significant 7 bits – i.e. bits 58 to 64 – to store extra data. One caveat is that even if just 48 bits out of 64 bits are needed to read a memory, the processor checks if significant bits (48…64) are identical – i.e. sign extended. If not, such an address will cause a fault. It means folded pointers may not always be storing a valid addressable memory. Hence folded pointers need to be sign extended before dereferencing.
We use the above technique to fold filled, matched and hasDuplicates into pointer bucketData. After folding and struct packing we will get a Bucket size of 12 bytes. Similarly DuplicateNode can be reduced to 16 bytes instead of 24 bytes. In total, we reduce the memory requirements for these two structs from 40 bytes to 28 bytes, a reduction of 30%.
Other requirements
In our implementation, there is a requirement regarding the size of Bucket and number of buckets in hash table to be a power of 2. These requirements are for the following reasons:
- Internal memory allocator allocates memory in power of 2 to avoid internal fragmentation. Hence, number of buckets * sizeof(Bucket) should be a power of 2.
- Number of buckets (‘N’) being the power of 2 enables faster modulo operations.
Instead of using a slow modulo operation (hash % N), faster bitwise operation (hash & (N-1)) can be used when N is power of 2.
Due to this, a 4 bytes hash field from Bucket is removed and stored separately in a new array hash_array_ in HashTable class. This ensures sizeof(Bucket) is 8 which is power of 2. Another advantage of separating hash is that Bucket is not required to be packed now.
Experimental evaluation:
We did extensive evaluation of the technique to see how it affects performance and memory utilization. We used 3 benchmarks:
- Microbenchmark: We ran the build and probe methods 60 times on a smaller number of rows to evaluate the performance and memory consumed.
- Billion-Row benchmark: On a single daemon, we ran the build and probe benchmark for a billion rows to measure the performance and memory consumed.
- TPC-DS-10000: Entire TPC-DS benchmark of scale 10000 was run on a 17-node cluster to measure the performance. It also measured peak memory consumed at the node and the operator level.
Microbenchmark
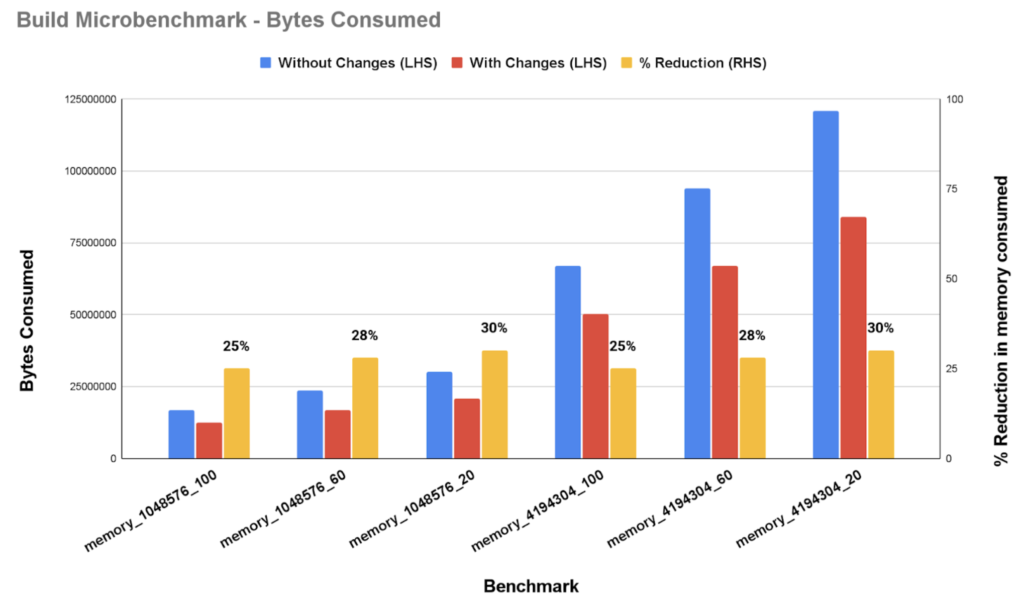
Figure 2a. Memory benchmark
Figure 2a shows the results of the memory benchmark. Benchmark names are in the format memory_XX_YY, where XX is the number of values being inserted into the hash table and YY represents the percentage of unique values. We see a reduction in memory consumed by up to 30% on building the hash table.
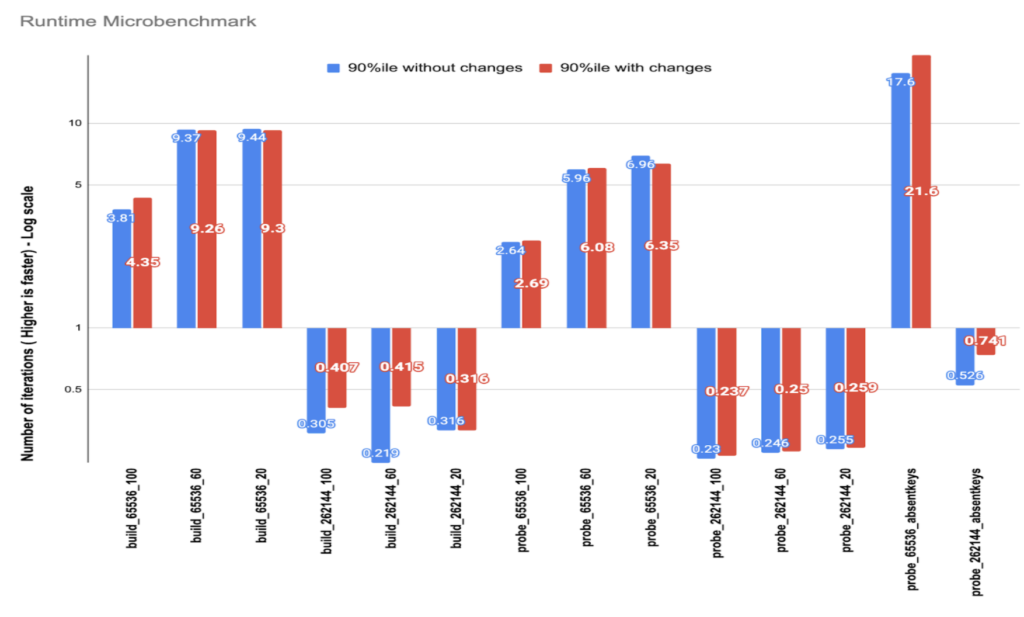
Figure 2b. Runtime benchmark
Figure 2b shows the results of the performance benchmark. build_XX_YY represents the build benchmark, where XX values were inserted and YY is the percentage of unique values. Similarly probe_XX_YY would probe against a hash table built with XX rows and YY unique values. These benchmarks were run 60 times, and they were repeated 10 times to find out iterations per millisecond. Figure 2b shows the 90th percentile of the number of iterations measured for those 60 runs. We observe no significant difference in the runtime of these hash table operations due to this change.
Billion-Row benchmark
We used the TPC-DS sales and items table for this benchmark. sales had columns s_item_id (int), s_quantity(int) ,s_date(date), whereas items had columns i_item_id (int)and i_price (double). sales had 1 billion rows and items had 30 million rows.
Build Benchmark
We ran a Group By query on sales to measure the performance and memory of building a hash table.
Query: select count(*) from sales group by s_item_id having count(*) > 9999999999;
| Grouping Aggregate Memory Usage | |||
| With Changes | Without Changes | ||
| Peak Allocation | Cumulative Allocation | Peak Allocation | Cumulative Allocation |
| 1.14G | 1.85G | 1.38G | 2.36GB |
Figure 3a
As shown in Figure 3a, we saw peak allocation reduced by 17% and cumulative allocation reduced by
21%. When running this 20 times, we didn’t see any performance degradation. Geomean with changes and without changes were around 68 seconds in both cases.
Probe Benchmark
For measuring the probe we ran a join query between items and sales, where sales is on the probe side and items is on the build side. Since we are building a hash table only on a smaller table in the join proposed, the goal of this benchmark was not to measure the reduction in memory, but to measure any performance difference in probing 1 billion rows via the sales table.
However, we created 3 kinds of sales tables for this purpose:
- sales_base: It has randomly generated 1 billion rows, the same that was used in the Build benchmarks.
- sales_30: It has 1 billion rows, with 30% of the rows unique.
- sales_60: It has 1 billion rows, with 60% of the rows unique.
We saw similar performance in both runs with our changes being slightly faster on sales_base, as shown in Figure 3b. Therefore, while reducing memory consumption we did not measure any degradation in aggregate query runtime.
| Table Type | GEOMEAN over 20 runs (seconds) | |
| With changes | Without changes | |
| sales | 110.8551081 | 114.6912898 |
| sales_30 | 103.2863058 | 102.4787489 |
| sales_60 | 84.12813181 | 84.8765098 |
Figure 3b
TPCDS-10000 scale
We evaluated the new hash implementation against a TPC-DS workload at scale 10000. We ran all the workload queries on a 17 node cluster with data stored in HDFS.
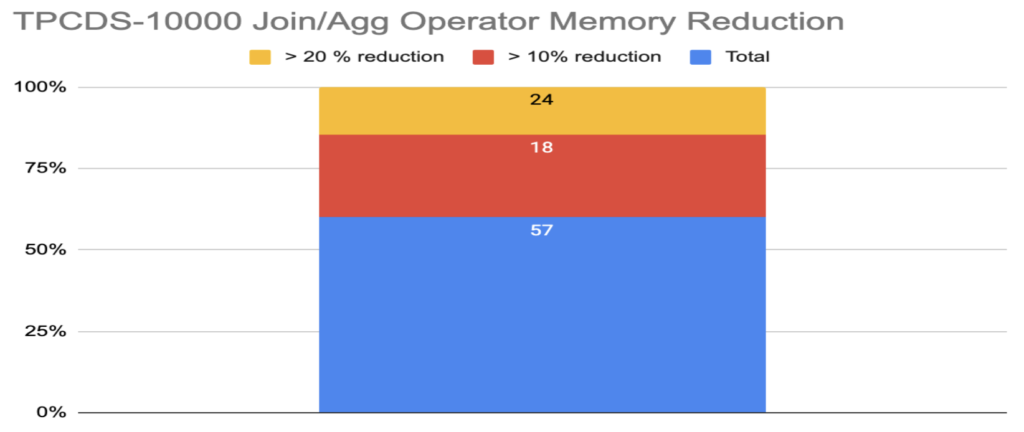
Figure 4a
Per-Operator Reduction:
For every query we computed the maximum percentage of reduction in memory for individual Join and Aggregation operators. We considered only the operators greater than 10 MB. As per Figure 4a, we found that for 42 out of 99 queries, memory consumption reduced by more than 10%. Furthermore, for 24 of those queries we saw memory consumption reduced by more than 20%.
Per-Node memory reduction:
On computing average peak memory consumption for the nodes involved, 28 queries showed greater than 5% reduction in memory and 11 queries showed more than 10% reduction, as seen in Figure 4b. Additionally, we saw around a maximum of 18% reduction, for q72.
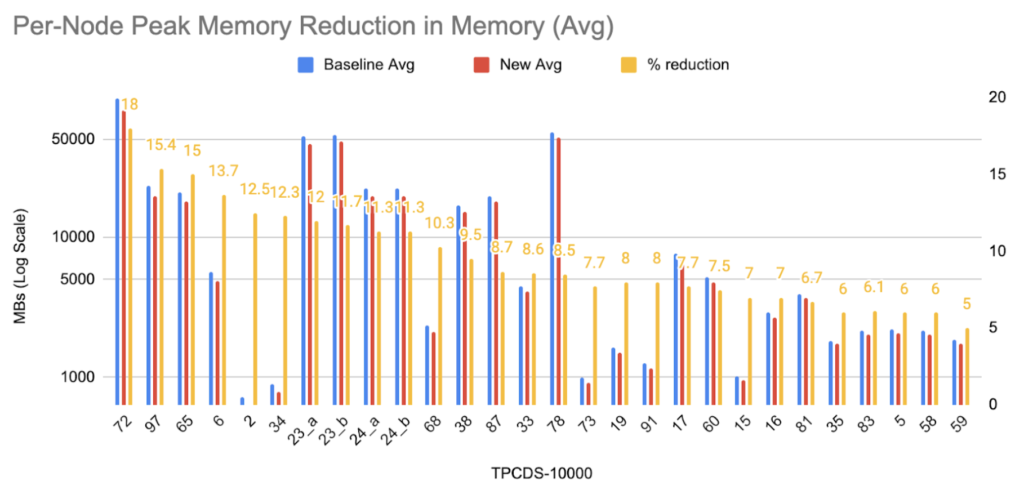
Figure 4b
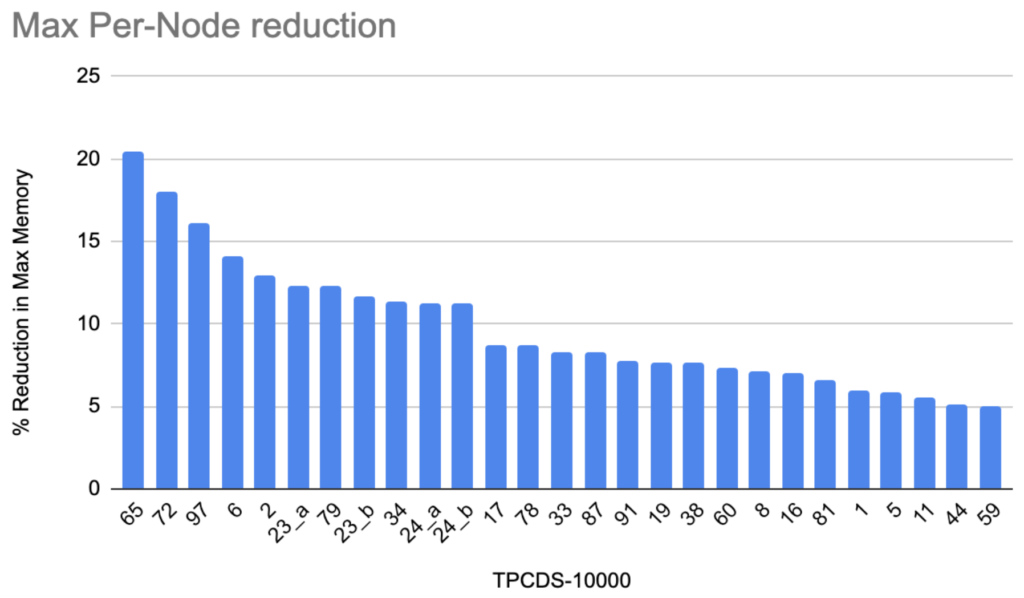
Figure 4c
On considering max-peak memory consumed in any node for a query, 27 queries show a reduction by 5%, and 11 show reduction more than 10%, as seen in Figure 4c. The maximum reduction observed was more than 20%, for q65.
Conclusion
As shown in the previous section we saw significant reduction in memory both at the node level and operator level, without any performance degradation.
This memory efficiency and performance optimization, as well as many others in Impala, is what makes it the preferred choice for business intelligence and analytics workloads, especially at scale. Now that more and more data warehousing is done in the cloud, much of that in the Cloudera Data Warehouse data service, performance improvement directly equates to cost savings. The faster the queries run, the sooner the resources can be released so the user no longer pays for them. A recent benchmark by a third party shows how Cloudera has the best price-performance on the cloud data warehouse market.
We encourage everyone to take a tour or test drive Apache Impala within the Cloudera Data Warehouse data service to see how it performs for your workloads. You can also contact your sales representative to book a demo. Additionally, to engage with the broader community please connect at user@impala.apache.org or dev@impala.apache.org.
Editor's Choice

