


HDFS erasure coding (EC), a major feature delivered in Apache Hadoop 3.0, is also available in CDH 6.1 for use in certain applications like Spark, Hive, and MapReduce. The development of EC has been a long collaborative effort across the wider Hadoop community. Including EC with CDH 6.1 helps customers adopt this new feature by adding Cloudera’s first-class enterprise support.
While previous versions of HDFS achieved fault tolerance by replicating multiple copies of data (similar to RAID1 on traditional storage arrays), EC in HDFS significantly reduces storage overhead while achieving similar or better fault tolerance through the use of parity cells (similar to RAID5). Prior to the introduction of EC, HDFS used 3x replication for fault tolerance exclusively, meaning that a 1GB file would use 3 GB of raw disk space. With EC, the same level of fault tolerance can be achieved using only 1.5 GB of raw disk space. As a result, we expect this feature to measurably change the TCO for using Hadoop.
This blog post is the follow-up post to the previous introductory blog post and progress report. It focuses on the latest performance results, the production readiness of EC, and deployment considerations. We assume readers have already gained a basic understanding of EC by reading the previous EC-related blog posts.
Terminology
The following terminology, from the two previous blog posts, will be helpful in reading this one:
- NameNode (NN): The HDFS master server managing the namespace and metadata for files and blocks.
- DataNode (DN): The server that stores the file blocks.
- Replication: The traditional replication storage scheme in HDFS which uses a replication factor of 3 (that is, 3 replicas) as the default.
- Striped / Striping: The new striped block layout form introduced by HDFS EC, complementing the default contiguous block layout that is used with traditional replication.
- Reed-Solomon (RS): The default erasure coding codec algorithm.
- Erasure coding policy: In this blog post, we use the following to describe an erasure coding policy:
- <codec>-<number of data blocks>-<number of parity blocks>-<cell size>, for example, RS-6-3-1024k
- <codec>(<number of data blocks>, <number of parity blocks>), for example, RS(6, 3)
For more information, see this documentation.
- Legacy coder: The legacy Java RS coder that originated from Facebook’s HDFS-RAID project.
- ISA-L: The Intel Storage Acceleration Library that implements RS algorithms, providing performance optimizations for Intel instruction sets like SSE, AVX, AVX2, and AVX-512.
- ISA-L coder: The native RS coder that leverages the Intel ISA-L library.
- New Java coder: The pure Java implementation of the Reed-Solomon algorithm (suitable for a system without the required CPU models). This coder is compatible with the ISA-L coder, and also takes advantage of the automatic vectorization feature of the JVM.
Performance Evaluation
The following diagram outlines the hardware and software setup used by Cloudera and Intel to test EC performance in all but two of the use cases. The failure recovery and the Spark tests were run on different cluster setups that are described in the corresponding sections that follow.
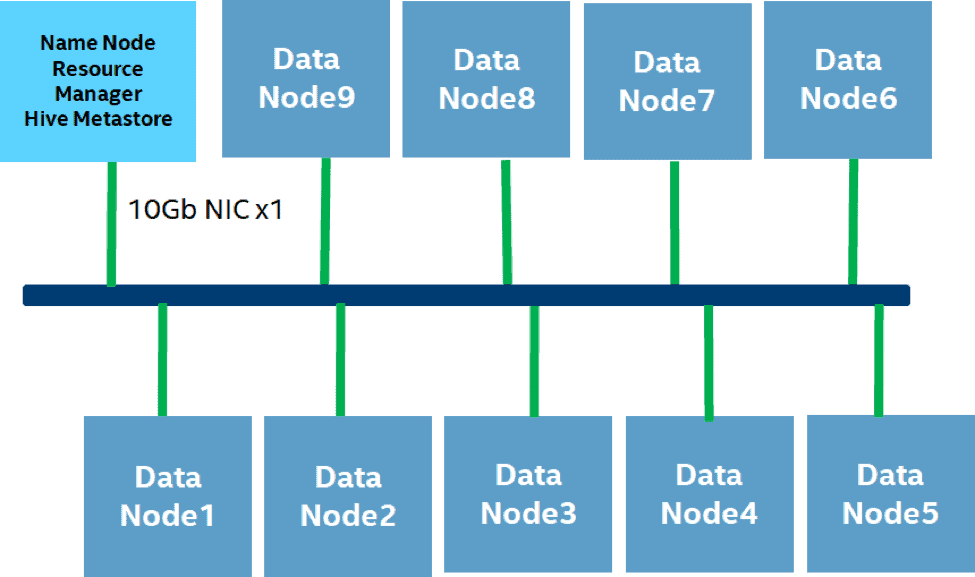
Figure 1. Cluster Hardware Configuration
The following table shows the detailed hardware setup. . All the nodes are in the same rack under the same ToR switch.
| Cluster Configuration | Management and Head Node | Worker Nodes |
| Node | 1x | 9x |
| Processor | 2 * Intel(R) Xeon(R) Gold 6140 CPU @2.30 GHz / 18 cores | |
| Memory | 256G DDR4 2666 MHz | |
| Storage Main | 4 * 1TB 7200r 512 byte/Sector SATA HDD | |
| Network | Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection | |
| Network Topology | All nodes in the same rack with 10Gbps connectivity | |
| Role | NameNode
Standby NameNode Resource Manager Hive Metastore Server |
DataNode
NodeManager |
| OS Version | CentOS 7.3 | |
| Hadoop | Apache Hadoop trunk on Jun 15, 2018
(commit hash 8762e9c) |
|
| Hive | Apache Hive 2.1.0 | |
| Spark | Apache Spark 2.2.0 | |
| JDK version | 1.8.0_141 | |
| ISA-L version | 2.22 | |
| HDFS EC Policy | RS-6-3-1024k | |
Table 1. Detailed Hardware and Software Setup
Test Results
In the following sections, we will walk through the results of the TeraSuite tests which compare the performance of EC and 3x replication, including failure recovery, the performance comparison for different EC codecs available, the result of IO performance tests comparing replication and EC with different codecs, the results of TPC-DS tests, and end-to-end Spark tests measuring the performance implications of EC for different file sizes.
The following tests were performed on a single-rack cluster. The EC performance may be impacted when used in a multi-rack environment, because reads, writes, and data reconstruction are all remote for erasure coded data.
TeraSuite
A set of tests were performed using TeraGen and TeraSort from the TeraSuite test suite included in MapReduce to gain insight into the end-to-end performance comparisons between replication and EC. Note that TeraGen is a write-only test and TeraSort is a write-heavy test using both read and write operations. TeraSort, by default, writes the output file with a replication factor of 1. For experimental purposes, we conducted two rounds of tests for replication: one round using the default replication factor of 1 for the output file and another using a replication factor of 3 for the output file. Five runs were conducted for each test, and the following results are the averages. The TeraSuite tests were set up to use 1TB data.
The following table lists the detailed configuration for the jobs:
| Configuration Name | Value |
| Number of Mappers | 630 |
| Number of Reducers | 630 |
| yarn.nodemanager.resource.cpu-vcores | 71 |
| yarn.nodemanager.resource.memory-mb | 212 GB |
| yarn.scheduler.maximum-allocation-mb | 212 GB |
| mapreduce.map.cpu.vcores | 1 |
| mapreduce.map.memory.mb | 3 GB |
| mapreduce.reduce.memory.mb | 3 GB |
| mapreduce.map.java.opts | -Xmx2560M |
| mapreduce.reduce.java.opts | -Xmx2560M |
Table 2. Configurations for TeraSort
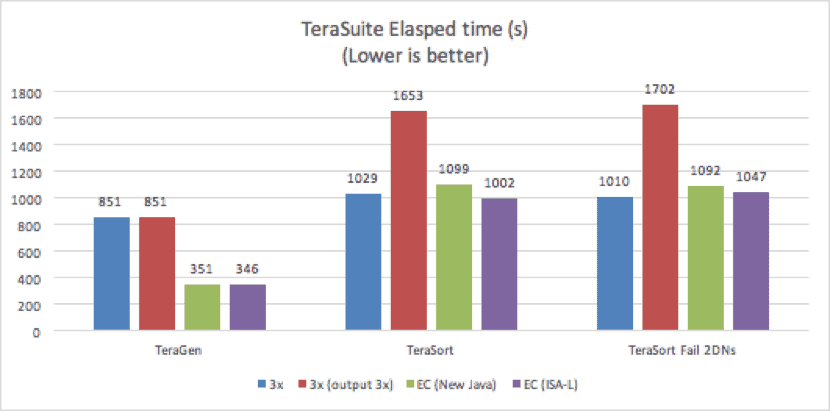
Figure 2. TeraGen/ TeraSort Performance
The above results indicate that EC performed more than 50% faster than replication for TeraGen. EC benefited from the parallel writes and the significantly smaller amount of data written. EC writes accounted for 150% of the original data size, compared to 300% for 3x replication, while still providing the same level of fault tolerance.
Two different executions were done for TeraSort tests, the first test with all DataNodes running and the second test where, before the TeraSort test execution, two randomly selected DataNodes were shut down manually. For TeraSort in the failed DataNodes tests, EC performed more than 50% faster when compared to 3x replication, achieving a similar performance to 3x replication with an output file of replication factor 1. Note that, as expected, the TeraSort test with 3x replicated output file performed 40% slower than the default TeraSort with 1x replicated output file, because the 3x replication test writes three times more data than the test with a 1x replicated output file.
The EC performance with two of nine DataNodes shut down was similar to the results with all nine DataNodes running. This similarity is mainly because the end-to-end time measured contains not only the storage time, but also the job execution time. Although two DataNodes were shut down, the NodeManagers were running and the computing power was the same. Therefore, the ‘on-the-fly’ reconstruction overhead is small enough to be insignificant when compared to the computing overhead.
Codec Micro-Benchmark Results
The codec that performs the erasure coding calculations can be an important accelerator of HDFS EC. Encoding and decoding are very CPU-intensive and can be a bottleneck for read/write paths. HDFS EC uses the Reed-Solomon (RS) algorithm, by default the RS (6,3) schema. The following figures show that Intel’s ISA-L coder significantly outperforms both the new Java coder and the legacy coder. These tests were done on the same hardware profile described above with 1 CPU core at 100% utilization.
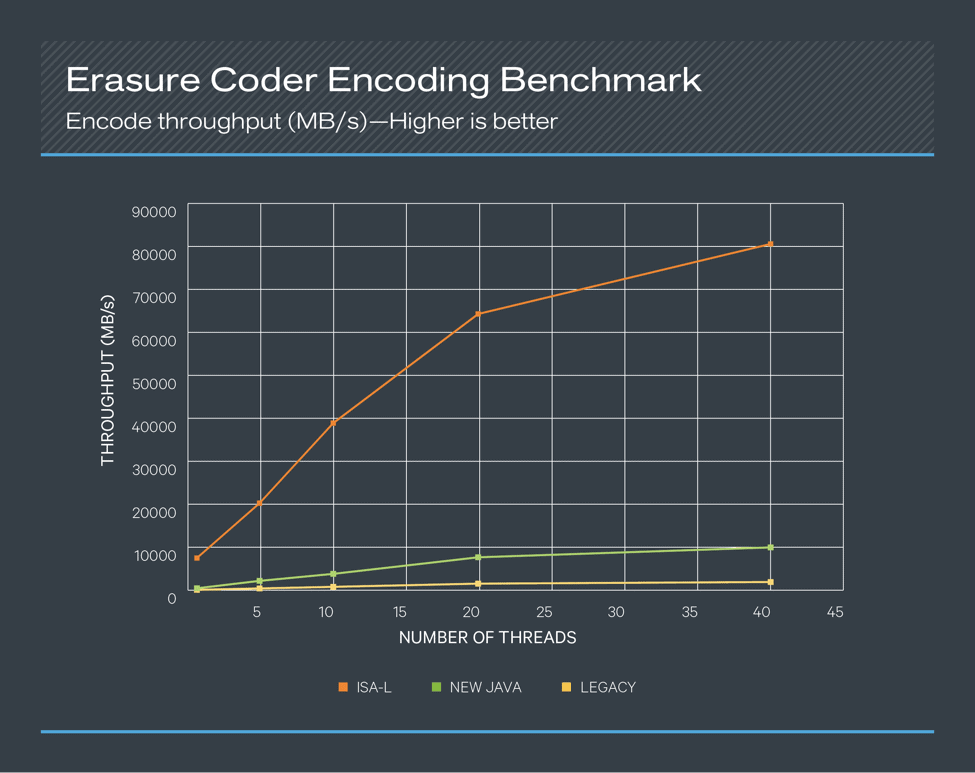
Figure 3. Erasure Coder Encoding Benchmark
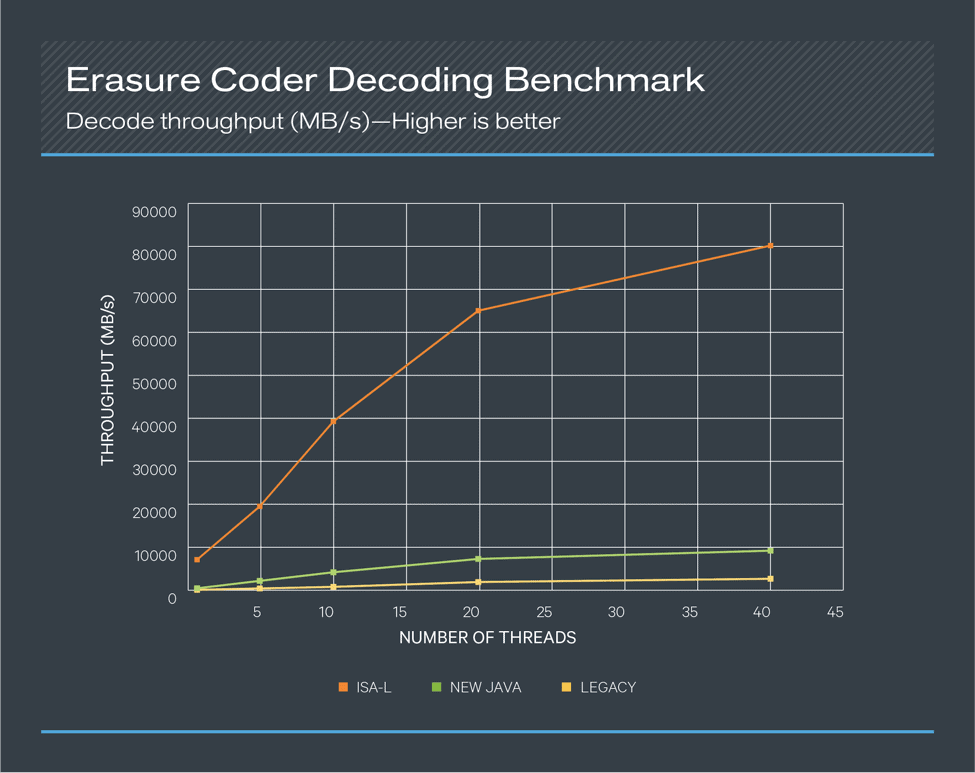
Figure 4. Erasure Coder Decoding Benchmark
In both the encoding and decoding benchmarks, the ISA-L coder performed about sixteen times better than the new Java coder when single-threaded and performed about eight times better even with 40 concurrent threads. Compared to the legacy coder, the numbers became about 70 times better when single-threaded and about 35 times better with 40 concurrent threads. Based on these results, leveraging the ISA-L coder for HDFS EC offers a great deal of value to any use case. ISA-L is packaged and shipped with CDH 6.1 and enabled by default.
In addition to the benchmarks with different concurrency, some additional tests were done with different buffer sizes. When single threaded, we saw that a buffer size of 64 KB or 128 KB performed about 8% better than a buffer size of 1024 KB. This is likely because the single-threaded test benefitted the most from CPU cache. For five or more concurrent threads, a 1024KB buffer size yielded the best performance. For this reason, the default EC policies of HDFS are all configured to have a cell size of 1024 KB.
DFSIO
A set of DFSIO (Hadoop’s distributed I/O benchmark) tests were run to compare the throughput of 3x replication and EC. In our tests, different numbers of mappers were tested, with each mapper processing a 25GB file. The operating system cache was cleaned before running each test. The result was captured as the overall execution time. Note that the DFSIO tests do not use data locality, so the results can differ slightly from production use cases, where replication can benefit from data locality while EC does not.
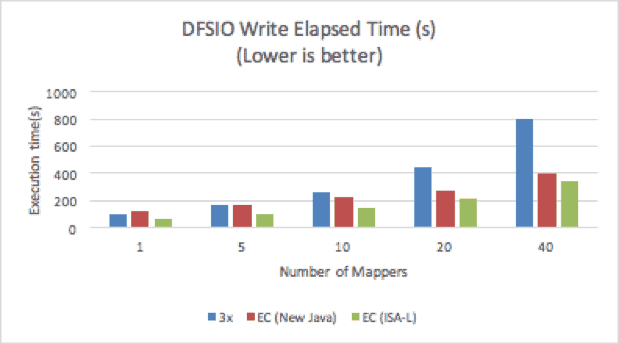
Figure 4. DFSIO Write Performance
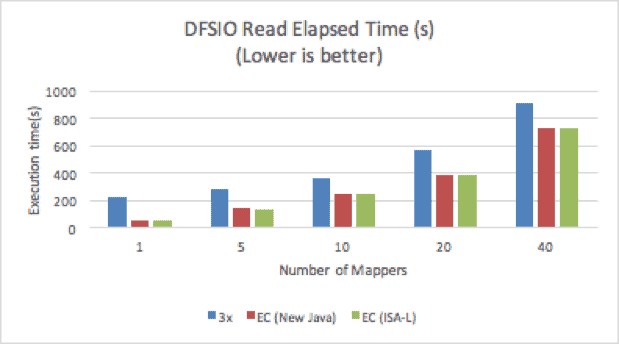
Figure 5. DFSIO Read Performance
EC with ISA-L consistently outperformed 3x replication in both read and write tests.
With only one mapper, EC outperformed 3x replication by 300% on the read test. With an increased number of mappers, EC was only about 30% faster than 3x replication, because a higher concurrency of mappers creates higher disk I/O contention, which reduces the overall throughput. We also observed that with a single mapper, cross-cluster disk utilization was more than five times higher with EC than with replication; with 40 mappers, disk utilization was at the same level, with EC performing only slightly better.
For the write test, when the number of mappers was low, 3x replication performed better than EC with the new Java codec, but was 30% to 50% slower than EC with ISA-L. With 40 mappers, 3x replication was the slowest, and took more than twice the execution time of EC, because of having to write twice the amount of data (300% vs 150%).
TPC-DS
We conducted comprehensive TPC-DS tests using Hive on Spark to gain insight into the performance for various queries. Tests were run for both ORC and text formats. We ran all the tests three times, and the result below is the average. The complete results are in this spreadsheet for curious readers.
The results of the TPC-DS runs show that EC performed slightly worse than replication in most cases. An important contributing factor in the overall performance drop was the remoteness of reading and writing erasure-coded data. There were a few CPU intensive queries where EC performed more than 20% slower. The CPU was almost fully used in running these queries. Given that writes are more CPU intensive for erasure-coded data due to parity block computations, the execution time increased. These queries are numbers 28, 31, and 88 for text formats. For a similar reason, the test results were a little worse for erasure coding when ORC file format was used, because data compression used for ORC files increased the overall CPU usage.
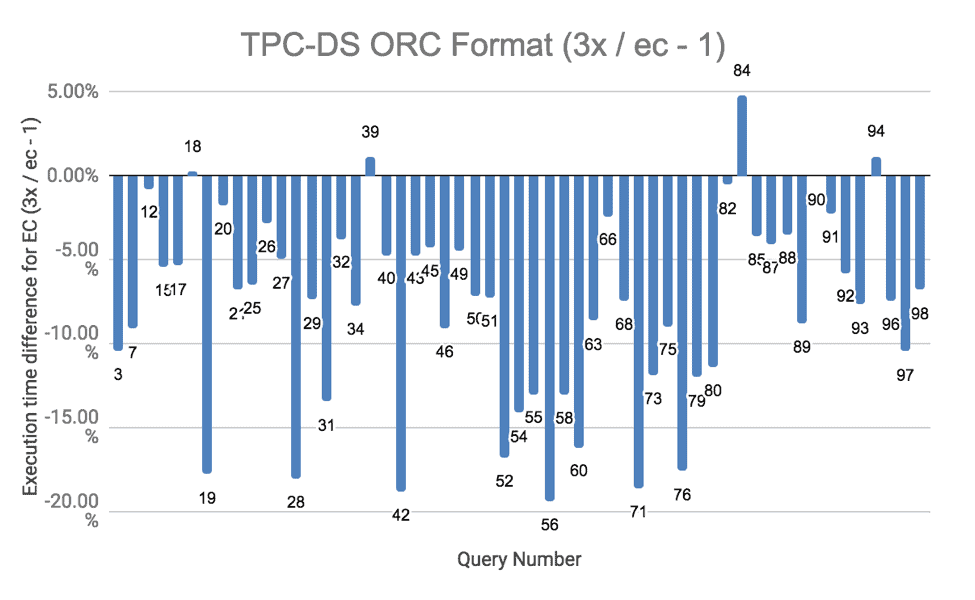
Figure 6. TPC-DS Performance with ORC format
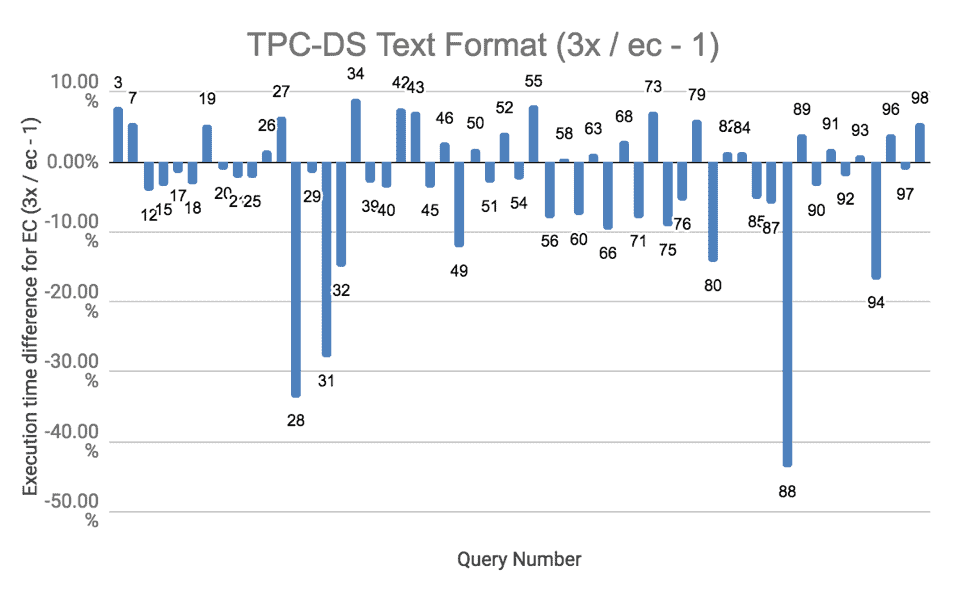
Figure 7. TPC-DS Performance with Text format
Spark
To better understand the performance of EC in end-to-end Spark jobs with different file sizes, several tests were conducted using TeraSort and Word Count on Spark on a different 20-node cluster using the RS(10,4) erasure coding policy. For each test, the overall amount of data was fixed, but different file sizes and numbers of files were configured for testing. We chose to use 600 GB of data for TeraSort and 1.6 TB of data for Word Count. Three series of tests were performed, simulating file sizes that were much smaller than, or similar to, or multiple times larger than the block size (128MB). For the rest of this blog post, we call these three series of tests as small, medium, and large files tests, respectively.
The following table lists the different file sizes used in the tests:
| TeraSort | WordCount | ||||
| Number of files | Size of each input file | Number of files | Size of each input file | Size of each output file | |
| Small files | 40,000 | 15 MB | 40,000 | 40 MB | 80-120 bytes |
| Medium files | 4,000 | 150 MB | 4,000 | 400 MB | 80-120 bytes |
| Big files | 1,000 | 600 MB | 1,000 | 1.6 GB | 80-120 bytes |
Table 3. Different file sizes used in Spark tests
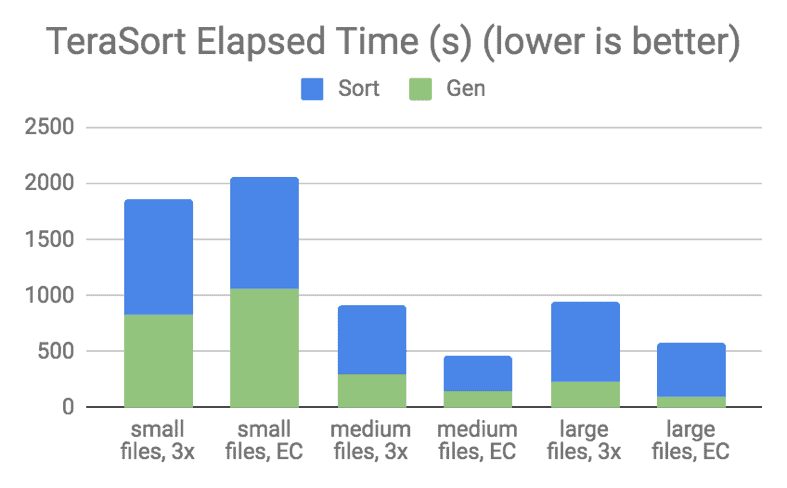
Figure 8. Spark TeraSort Performance for RD(10,4)
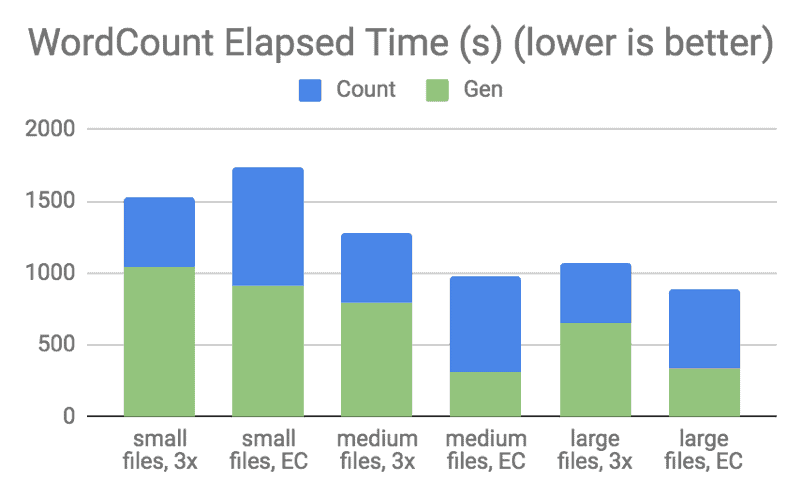
Figure 9. Spark Word Count Performance for RS(10,4)
In both the graphs, “Gen” means to create the files for the respective job run, which is a write-heavy workload. “Sort” and “Count” mean the execution of the job, including reading the input files from HDFS, executing the tasks, and writing the output files. As stated earlier, the output file size for a Word Count job is typically very small, in the range of several hundred bytes.
From the TeraSort graph above, you can see that EC performed better than 3x replication for medium and large files tests. However, for small file tests, EC performed worse than replication because reading many small blocks concurrently from multiple DataNodes caused a lot of overhead. Note that TeraSort performed slightly worse with large files than with medium files, for both erasure-coded and replicated data, probably because of the increased amount of spilled records in case of large files.
Similar results were seen in the Word Count run. Note that because the Word Count job output files were extremely small, EC consistently performed worse than 3x replication, which is unsurprising considering the increased memory pressure on the NameNode described in the File Size and Block Size section. In addition to that, when the file size is smaller than the EC cell size (1 MB by default), the EC file is forced to fall back to replicating the data into all its parity blocks, yielding effectively four identical replicas with RS(6, 3) and five identical replicas with RS(10, 4). For more information, see the File Size and Block Size section.
Failure Recovery
When one of the EC blocks is corrupted, the HDFS NameNode initiates a process called reconstruction for the DataNodes to reconstruct the problematic EC block. This process is similar to the replication process that the NameNode initiates for files using replication that are under-replicated.
The EC block reconstruction process consists of the following steps:
- The failed EC blocks are detected by the NameNode, which then delegates the recovery work to one of the DataNodes.
- Based on the policy, the minimum required number of the remaining data and parity blocks are read in parallel, and from those blocks, the new data or parity block is computed. Note that for erasure-coded data, each data block and parity block is on a different DataNode, ideally a different rack as well, making reconstruction a network-heavy operation.
- Once the decoding is finished, the recovered blocks are written out to the DataNodes.
One common concern for EC is that reconstruction might consume more resources (CPU, network) in the cluster overall, which can burden performance or cause recovery to be slower when a DataNode is down. Reconstructing erasure-coded data is much more network-intensive than replication, because the data and parity blocks used for the reconstruction are distributed to different DataNodes and usually to different racks. In an ideal setup with sufficient number of racks, each storage block of an erasure-coded logical block is distributed to a different rack; therefore, the reconstruction requires reading the storage blocks from a number of different racks. For example, if RS(6, 3) is used, data needs to be pulled from six different racks in order to reconstruct a block. Reconstruction of erasure-coded data is also much more CPU-intensive than replication because it needs to calculate the new blocks rather than just copying them from another location.
We performed a test in order to observe the impact of reconstruction. We shut down one DataNode on a 20-node cluster and measured the speed of the recovery using the RS(3, 2) erasure coding policy against regular 3x replication. For erasure-coded data, the recovery took six times longer than for 3x replication.
Recovery is usually slower for erasure-coded data than for 3x replication, but if a more fault-tolerant policy is used, it can be less critical. For example when RS(6, 3) is used and if one block is lost, two more missing blocks can still be tolerated. The higher failure tolerance can therefore reduce the priority of reconstruction, allowing it to be done at a slower pace without increasing the risk of data loss. The same is true for losing a rack if there are enough racks so that each data block and parity block is distributed to a different rack. For more information on how erasure-coded data is distributed across racks, see the Locality section of this blog post.
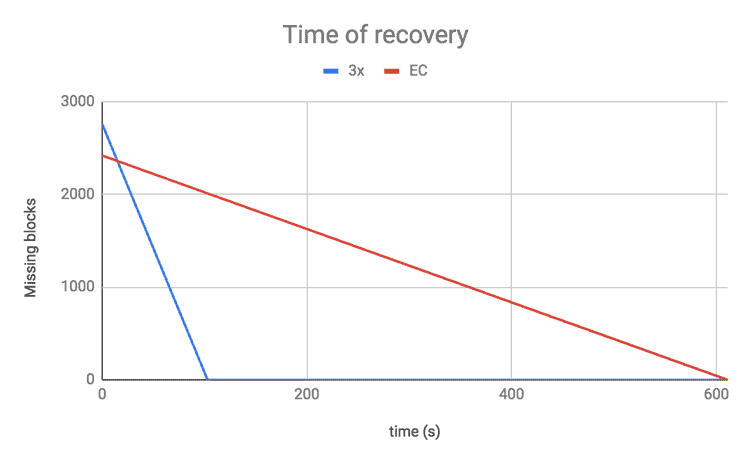
Figure 10. Time of recovery for RS(3,2)
The parameters listed in the Apache HDFS documentation can be tuned to provide fine-grained control of the reconstruction process.
Production Considerations
Besides storage efficiency and single job performance, there are many other considerations when deciding if you want to implement erasure coding for production usage. For information about how to migrate existing data to EC, see the Cloudera documentation.
Locality
From the beginning, data locality has been a very important concept for Hadoop. In traditional HDFS, where data is replicated, the block placement policy of HDFS puts one of the replicas on the node performing the write operation, and the NameNode tries to satisfy a read request from a replica that is closest to the reader. This approach enables the client application to take advantage of data locality and reduces network traffic when possible. DataNodes also have features like short-circuit reads to further optimize for local reads.
For erasure-coded files, all reads and writes are guaranteed to have remote network traffic. In fact, the blocks are usually not only read from remote hosts but also from multiple different racks.
By default, EC uses a different block placement policy from replication. It uses a rack-fault-tolerant block placement policy, meaning that the data is distributed evenly across the racks. An erasure-coded block is distributed to a number of different DataNodes equal to the data-stripe width. The data-stripe width is the sum of the number of data blocks and parity blocks defined by the erasure coding policy. If there are more racks than the data-stripe width, then an erasure-coded block is stored on a number of randomly chosen racks equal to the data-stripe width, that is, each of the DataNodes is selected from a different rack. If the number of racks is less than the data-stripe width, then each rack is assigned a number of storage blocks that is a little more than the value of data-stripe width/number of racks. The rest of the storage blocks are distributed to other DataNodes that hold no other storage blocks for the logical block. For more information, checkout Cloudera’s documentation about Best Practices for Rack and Node Setup for EC.
For this reason, EC performs best in an environment where rack-to-rack bandwidth is not oversubscribed or has very low oversubscription. Network throughput should be carefully monitored when increasing the overall mix of EC files. This effect is also one of the biggest reasons why Cloudera recommends to start using EC with cold data. For more information, see Cloudera’s documentation.
File Size and Block Size
Other important considerations for EC are file size and block size. By default, the HDFS block size in CDH is 128 MB. With replication, files are partitioned into 128MB chunks (blocks) and replicated to different DataNodes. Each 128MB block, though, is complete within itself and can be read and used directly. With EC, each of the underlying data blocks and parity blocks is located in a different 128MB regular block. Reading data from a block means reading data from all blocks in the block group. A block group is (128 MB * (Number of data blocks)) in size. For example, RS(6, 3) will have a block group of 768 MB (128 MB * 6).
It is important to consider the implications of that model on the memory usage of the NameNode, specifically the number of blocks in the NameNode block map. For EC, the bytes/blocks ratio is worse for small files which increases the memory usage of the NameNode. For RS(6,3) the NameNode stores the same amount of block objects, nine block objects, for a 10MB file as for a 768 MB file. Comparing it with 3x replication, a 10MB file with 3x replication means three block objects in the NameNode; a 10MB file with EC (RS(6, 3)) means nine block objects in the NameNode!
For very small files of sizes smaller than the value of data blocks * cell size (in case of RS(6, 3) it is 6 * 1MB), the bytes/blocks ratio is also bad. This is because the number of actual data blocks is less than the data blocks defined by the erasure coding policy, though the number of parity blocks is always the same. For example, in the case of RS(6,3) with a cell size of 1 MB, a 1MB file consists of one data block, rather than six, but it still has three parity blocks. A 1MB file would therefore require four block objects in total. If 3x replication were used, the same file would require only three block objects. You can see the number of blocks for different file sizes in Figure 11 and Figure 12.
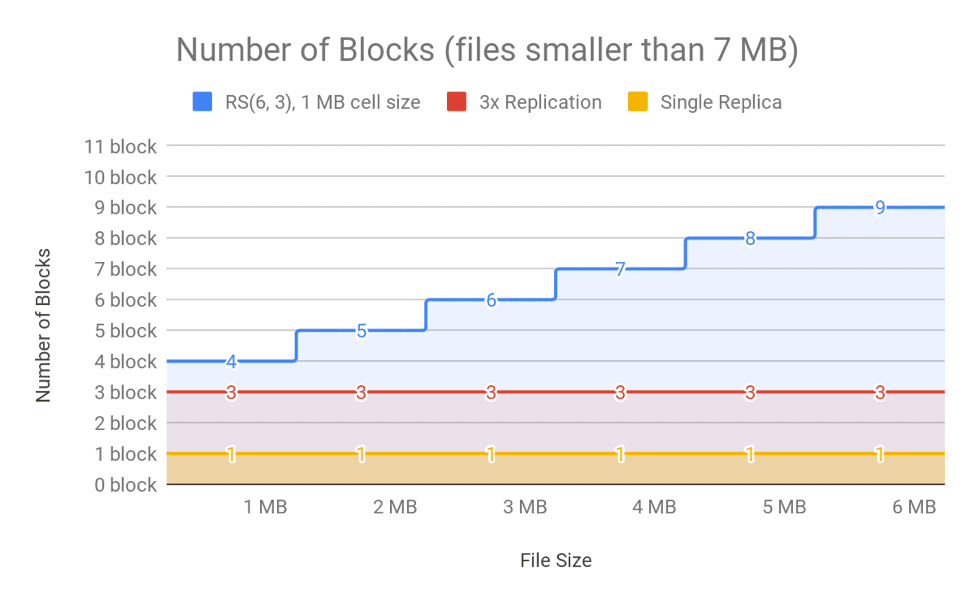
Figure 11. Number of Blocks in NameNode for Different File Sizes (files larger than 7MB)
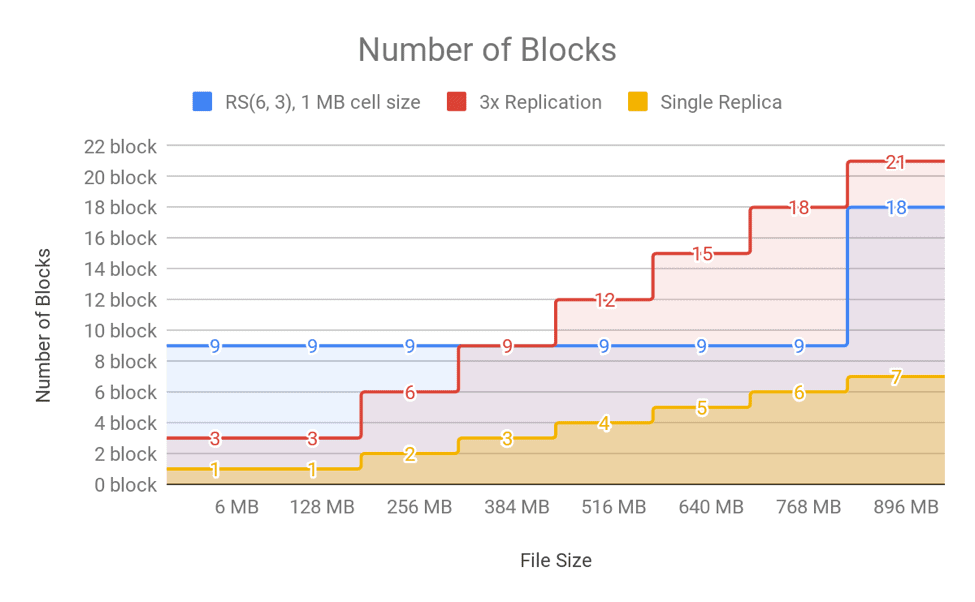
Figure 12. Number of Blocks in NameNode for Different Files Sizes
As shown in the above figures, the number of blocks is linear to file size for replication, but is a step function for EC because of the nature of the striping layout. For this reason, EC may aggravate memory pressure on the NameNode in clusters with a high number of small files. (For more information on the small files problem, see this blog post). Large files are better suited to EC, because the block count for the final partial block group is amortized over the whole size of the file. An ideal workflow would include a process to merge and compact the small files into a large file and apply EC to that compacted large file. For more information, see this documentation about compacting small files using Hive.
Decoding and Recovery
When reading an erasure-coded file in HDFS, reading from the data blocks and constructing the logical block (file content) does not have to pay any EC encoding or decoding cost. However, if any of the data blocks cannot be read—for example because the DataNode holding it is down, or the block is corrupt and being reconstructed—HDFS will read from the parity blocks and decode into a logical block. Although the problematic data block is reconstructed later in an asynchronous fashion, the decoding consumes some CPU. From Figure 4, this decoding adds very minor overhead to the overall performance.
Conclusion
Erasure coding can greatly reduce the storage space overhead of HDFS, and, when used correctly for files of appropriate sizes, can better utilize high-speed networks for a higher throughput. In the best case scenario, on a network with completely sufficient bandwidth, with the Intel ISA-L library and Hadoop ISA-L coder, read and write performances are expected to be better than the traditional 3x replication for large files. Cloudera has integrated erasure coding into CDH with first-class enterprise support. However, it is strongly recommended that customers evaluate their current HDFS usage and plan to on-board files to EC accordingly. When doing so, keep in mind that the small files problem is exacerbated when EC is used for small files.
For a step-by-step guide on how to set up HDFS erasure coding in CDH, see Cloudera’s documentation. For best practices for using erasure coding with Hive, see this documentation.
Xiao Chen is a member of the Apache Hadoop PMC.
Sammi Chen is a member of the Apache Hadoop PMC.
Kitti Nanasi is a Software Engineer at Cloudera.
Jian Zhang is a Software Engineer at Intel.
Editor's Choice


Interesting read,
Have you considered a much higher N and K and potential much smaller chunk/block size and ? That should provide much better flexibility in distributing the data and help with the granularity problem that is evident on fig. 12