

Once the data science is done (and you know where your data comes from, what it looks like, and what it can predict) comes the next big step: you now have to put your model into production and make it useful for the rest of the business. This is the start of the model operations life cycle. The key focus areas (detailed in the diagram below) are usually managed by machine learning engineers after the data scientists have done their work. ML Engineering includes (but isn’t necessarily limited to): the data pipeline (the data used to make the features used for model training), model training, model deployment, and model monitoring. 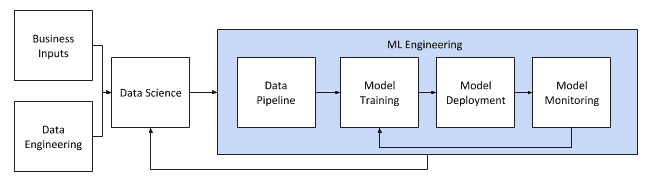
This post discusses model training (briefly) but focuses on deploying models in production, and how to keep your models current and useful. To make this more concrete, I will use an example of telco customer churn (the “Hello World” of enterprise machine learning). For a business that has consumer customers, knowing when a customer is likely to churn to a competitor is useful, as they can then take action to try to retain that customer. The data science and machine learning engineering teams create the process that can predict when a customer is likely to churn, which will trigger a retention mechanism.
I have created a GitHub repo with code examples that cover most of the implementation options discussed in this post. The repo is focused on credit card fraud, rather than telco churn.
What do we mean by “Model”?
The term “model” is quite loosely defined, and is also used outside of pure machine learning where it has similar but different meanings. For the purpose of this blog post, I will define a model as: a combination of an algorithm and configuration details that can be used to make a new prediction based on a new set of input data. The algorithm can be something like (for example) a Random Forest, and the configuration details would be the coefficients calculated during model training. It’s like a black box that can take in new raw input data and make a prediction. For the churn example we need to be able to take in new data for a customer and predict whether they are likely to churn or not. 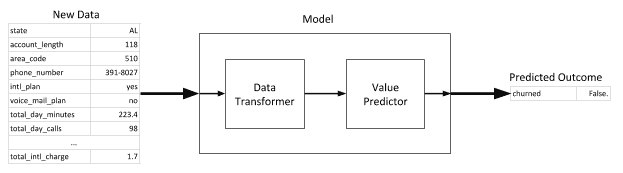
There are many tools and software programs that are able to create models. Just simply writing out an equation on paper and assigning values to the variables is a type of model. For this code example, I will focus on building models using both Apache Spark and scikit-learn.
Model Formats
One of the key requirements for a model is that it needs to be portable. You are likely to want to use the model in different places in the business, and there is a need for a mechanism that contains all the details necessary to make a new prediction in a different environment. This needs to include the type of algorithm used and the coefficients and other parameters calculated during training. For Spark and scikit-learn the formats supported are:
- Spark MLWritable: the standard model storage format included with Spark, but limited to use only within Spark
- Pickle: a standard python serialisation library used to save models from scikit-learn
- PMML: (Predictive Model Markup Language) a standardised language used to represent predictive analytic models in a portable text format
- ONNX: (Open Neural Network Exchange) provides a portable model format for deep learning, usingGoogle Protocol Buffers for the schema definition
Model Training Options
Model training is the science part of data science and not something that needs to be covered in much detail here (see our blog for more details on model training). The two main approaches to model training are batch and real-time.
Batch Training
Batch training is the most commonly used model training process, where a machine learning algorithm is trained in a batch or batches on the available data. Once this data is updated or modified, the model can be trained again if needed.
Real-time Training
Real-time training involves a continuous process of taking in new data and updating the model’s parameters (e.g., the coefficients) to improve its predictive power. This can be achieved with Spark Structured Streaming using StreamingLinearRegressionWithSGD.
Model Deployment Options
Once the model has been trained, it must then be deployed into production. Just as a point of clarification, the term “model deployment” is often used interchangeably with “model serving,” “model scoring,” or “predicting.” While there is nuance as to when to use which term, it’s context dependent;it all just refers to the process of creating predicted values from new data.
Batch Model Scoring
To review, In our telco churn example, what is useful for business is to know which clients are likely to churn, and to trigger a retention process. If the retention process is to send targeted email campaigns with special offers to customers at risk of churning, then this can be done as a batch process.
Operational Databases
This option is sometimes considered to be real-time as the information is provided “as its needed,” but it is still a batch method. Using our telco example, a batch process can be run at night that will make a prediction for each customer, and an operational database is updated with the most recent prediction. The call center agent software can then fetch this prediction for the customer when they call in, and the agent can take action accordingly.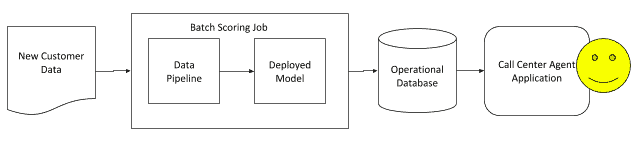
One potential problem with this approach is that a customer’s data may have changed since the last batch job was run, and their prediction at the point they call in would be different; they may have made several calls to support, or they may have had technical issues. Another issue is that you are computing predictions for all customers, but not all of them will call in. Batch scoring will incur a compute cost, and for a large customer base this could be seen as waste.
Note: Something that I often see with customers working with data science and machine learning problems is the separation of PySpark from other useful python functions, specifically scikit-learn. Apache Spark is exceptionally good at taking a generalised computing problem executing it in parallel across many nodes and splitting up the data to suit the job. PySpark runs python code and has a wrapper around the Spark API that will interact with cluster and distributed data directly. It has been possible to run a pure python function on data in a Spark DataFrame since version 0.7, but it was quite slow. Since Spark 2.3, PySpark now uses Pandas based UDF with Apache Arrow, which significantly speeds this up. If you have created a model using scikit-learn and not Spark MLlib, it’s still possible to use the parallel processing power of Spark in a batch scoring implementation rather than having to run scoring on a single node running plain old python.
Real-time Model Serving
In our telco churn example, having a call center agent know that this customer calling is a high churn risk would require the ability to get a prediction in real-time. There are several deployment patterns that can be used to make this work.
Online Scoring with Kafka and Spark Streaming
One way to improve the operational database process talked about in the previous section is to implement something that will continuously update the database as new data is generated. You can use a scalable messaging platform like Kafka to send newly acquired data to a long running Spark Streaming process. The Spark process can then make a new prediction based on the new data and update the operational database.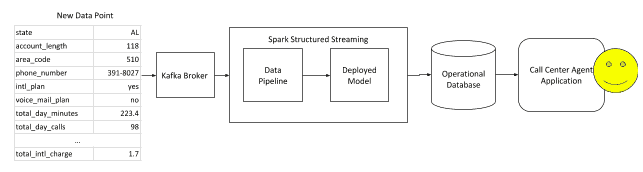
This removes the problem of a potential incorrect prediction for a customer based on outdated data.
Web Service API
For a genuine real time prediction using current data, a common implementation pattern is using a web service wrapper around the model. CDSW implements real-time model serving by deploying a container that includes the model and necessary libraries to build a REST API. This API will accept a request with JSON data, pass the data to the function that contains the model, and return a predicted response.
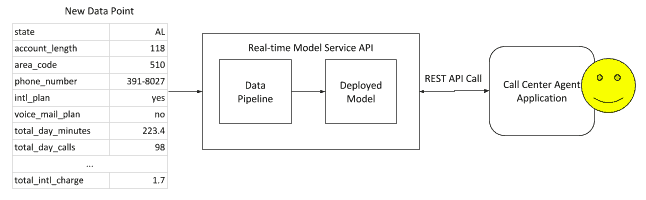
For our telco churn example, the current data representing the customer is passed to the model serving end-point; it will return a 1 if they are likely to churn, or a 0 if they are not.
This deployment model is common outside of CDSW, with deployments managed through a model lifecycle, and put into production with containers using Kubernetes into OpenShift or public cloud container environments.
The one thing to look out for with this deployment pattern is managing infrastructure to deal with the load associated with concurrency. If there are several calls that happen at the same time, there will be multiple API calls placed to the end point. If there is not sufficient capacity, calls may take a long time to respond or even fail, which will be an issue for the call center agent.
Device Scoring
A newer, emerging model serving option is to move the ML models right to the edge and make a prediction on an edge device. This allows models to still be usable in situations with limited network capacity and push the compute requirements away from a central cluster to the devices themselves. In our telco example, if the customer is using the telco company’s app, a model on the app can make a churn prediction using the customer’s data in the application and initiate a retention action – like a special offer or discount, etc.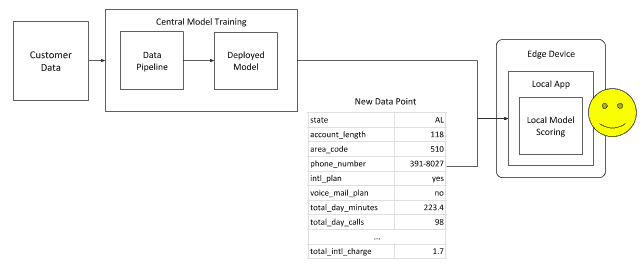
In this instance, the model might be trained on the central cluster and is shipped to the device using one of the portable model formats as mentioned above. For mobile devices, this can extend beyond Pickel, PMML, and ONNX and include device-specific implementation like CoreML and MLKit.
This is not limited to mobile phones, though; the same mechanism can be used for IoT devices running MiniFi. There is also the ability to do scoring directly in a browser, using Tensorflow.js and ONNX.js.
The key ability is being able to make a new prediction based on the model information contained in the portable model format, without needing to connect back to the central model training cluster.
Monitoring Model Performance
Once a model is deployed into production and providing utility to the business, it is necessary to monitor how well the model is performing. There are several aspects of performance to consider, and each will have its own metrics and measurements that will have an impact on the life cycle of the model.
Model Drift
Model Drift is the term used to describe the change in the predictive power of a model, i.e., how accurate is this model still? In a dynamic data system where new data is being acquired very regularly, the data can change significantly over a short period of time. Therefore the features that are used to train the model will also change. Using our telco example, a change in pricing or a network outage may have a big impact in the churn number and therefore – unless the model takes this new data into account – the predictions will not be accurate.
In a model operations life cycle, there needs to be a process that measures the model’s performance against new data to test the model’s accuracy (or whichever performance metric is deemed important to the business). Some commonly used measures for model accuracy are Area Under the Receiver Operating Characteristic Curve (AUROC) and Average Precision (AP).
If the model falls below an acceptable performance threshold, then a new process to retrain the model is initiated, and that newly trained model is deployed. 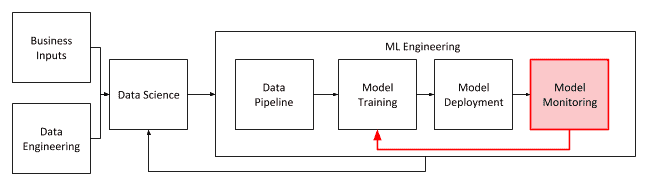
Managing deployed models and keeping track of which model file and configuration parameter set is currently deployed in production is a central feature of the CDSW models component. The same principles apply to other model deployment methodologies, too. There is a process that measures the performance of the model in the production on new data; when the model is no longer performing to the required level for the business, it will be retrained on new data.
For supervised learning models( such as the Random Forest used in our telco example), it may take some time to acquire new labeled data before the model can be tested, and this will need to be factored into the process.
There will also be times where the input data has changed so that the features which were originally selected during the data science process will no longer be as relevant to the outcome being predicted, and simply retraining the model will not yield better performance results. At this point, it becomes necessary to go back to the data scientist, and to re-look at the whole process. This may require adding new data sources or completely re-engineering the model, but this is an equally critical part of the model lifecycle. The model monitoring process must take this into account as well. 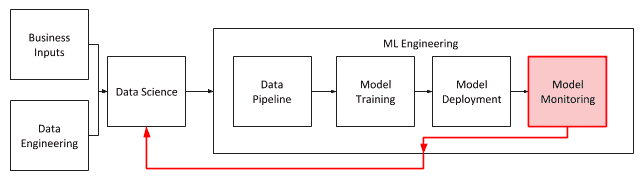
There are other measurements that are applicable as a model performance metric but aren’t necessarily related to accuracy. This may include algorithmic bias or a skew in the input data that leads to unfair predictions. These will be harder to measure, but can be even more critical in certain business contexts.
Conclusion
The machine learning model operations life cycle process is still a relatively new practice, and there is not as yet a defined industry standard as to how things should be implemented. This means there are many ideas and opinions on the right way to do things, but no single consensus view. It’s also unlikely that one consensus view will emerge that will meet all model operations teams’ requirements. What we do know is that there are certain design patterns that are being repeated more often and these are what I have presented in this post.
The key takeaway is to understand that models change and – over time – their performance will decline. Any model that makes a prediction of a possible future event and acts to change the cause leading to that event will change the whole system on which it is making predictions. This changes the data (the features the models use to make that prediction); therefore, the model will lose accuracy in its predictive power.
What is important is knowing what model performance measurements matter to the business, how quickly the model performance is changing, and where to set the threshold to trigger the model retraining process.
See the new capabilities in action and learn more about how Cloudera Data Science Workbench accelerates enterprise data science from research to production in the CDSW resource center.
Editor's Choice


Great overview of ML production methods, tools and pitfalls! Thanks for a great article Jeff!
Really educative. Great job Jeff.
Nice explanation, you covers the end2end pipeline… Thanks
Thank you for sharing.
This article should be read by every data engineer and data scientist as well. Thanx!
You’ve mentioned that is possible export Spark models to Pickle, PMML and others. But it is not that easy, I couldn’t find a documentation to export Spark model as Pickle. I only found a PMML (https://openscoring.io/blog/2020/02/16/deploying_sparkml_pipeline_openscoring_rest/) option that doesn’t work properly.
I am really disappointed with SparkML
Hi Mauricio, thank you for your comment. I did not mean to imply Spark can export models to Pickle, but re-reading it now, I can see how it could interpreted that way. SparkML works really well for large, distributed datasets but does not have all the features that scikit learn does. Have you looked into sk-dist (https://github.com/Ibotta/sk-dist) at all? It bridges the gap between Spark and scikit learn and my help you with some of the SparkML issues you are experiencing.
Thank you so much, the article is very informative.
Hi Jeff, Detailed explanation on ML engg and want to know deploying pipeline using predictive model – kafka-spark streaming -hbase/hdfs -web/visualization by using API or code
This Blog is very useful and informative.
data science course aurangabad