

Get an update on the progress of the effort to bring erasure coding to HDFS, including a report about fresh performance benchmark testing results.
About a year ago, the Apache Hadoop community began the HDFS-EC project to build native erasure coding support inside HDFS (currently targeted for the 2.9/3.0 release). Since then, we have designed and implemented basic functionalities in the first phase of the project under HDFS-7285, and have merged the changes to the Hadoop trunk.
To briefly summarize our introductory blog post on the subject, this work introduces a new data layout form that stripes a logical file block into much smaller cells, and supports client writing and reading in this striped form. Erasure coding (EC) is performed on demand with each stripe of cells. HDFS-EC supports codec computation through a generic erasure codec framework, based on multiple codec library implementations we also developed.
This follow-up post serves as a summary of the analysis that led to 7x to 30x performance gains. It includes
a comprehensive performance study that will give potential users some guidelines about what improvements to expect. We’ll also describe technical details about the code changes and new optimizations done so far.
But first, some terminology:
- NameNode (NN): HDFS master server managing the namespace and metadata for files and blocks
- DataNode (DN): servers that actually store file blocks
- Replication: the traditional 3-way replication storage scheme in HDFS
- Striped/striping: the new striping form introduced by HDFS-EC
- Reed-Solomon (RS): the default erasure-coding codec algorithm
- HDFS-RAID coder: the Java RS coder originating from Facebook’s HDFS-RAID project
- ISA-L: the Intel Storage Acceleration library that implements RS algorithms. It provides special optimizations for Intel instruction sets like SSE, AVX, and AVX2.
- ISA-L coder: the native RS coder that leverages Intel ISA-L library
- New Java coder: a new Java RS coder we developed that is compatible with the ISA-L coder, and also takes advantage of the JVM’s automatic vectorization feature. In cases where the native Hadoop library isn’t deployed, this new Java coder is helpful.
Now, let’s dive into the details about the testing.
Test Setup
Hardware Environment
We have 11 nodes in total. One node serves as an external client node, and the other 10 nodes are used to build the cluster: one NN and nine DN. Table 1 lists the hardware of the external client node:

Table 2 lists the hardware of the DN in the cluster. Each DN has one HDD and one SSD. We could choose either the HDD or SSD to store the data.

Please note:
- A codec-level benchmark was done on the external client node.
- The HDFS clients reside on the external node; there’s no data locality for either replica or EC. The external node’s network can be either 10Gbps or 20Gbps, and the DN’s disk can be either HDD or SSD, yielding four different combinations of test configurations.
- For all queries, the job was executed inside the cluster, where each job task and HDFS client collocate with a DN and data locality has an impact on performance. SSD was used on the DNs.
- In all the tests, the HDFS client did the codec calculations instead of the DN, and the background data recovering worker in the DN was disabled to avoid unnecessary impact.
- Only the external node has AVX2 support, thus HDFS clients running on DNs could make the most of the ISA-L coder. We believe this setup reflects a real-world cluster environment in which servers are not always up to date.
Software Environment
Table 3 lists the software components we used to build the cluster.

Methodology
We performed a spectrum of benchmarks, from the lowest codec level to end-to-end Apache Hive queries. Here are the main things to know about our methodology.
- Codec benchmark. The purpose of the codec benchmark is to compare the throughput of different coders and obtain insights about how to choose one. To measure the efficiency of pure erasure coding computation, we prepared a large buffer of random data in memory in advance, and launched one or multiple threads to encode/decode the data. To exclude I/O overheads, the computed data was discarded/not saved. Furthermore, all the threads used the same encoder/decoder instance so that the initialized matrix and buffers used by the coder were reused. The throughput was calculated by dividing the total amount of encoded/decoded data over the elapsed time.
- HDFS client read/write. Under the striped block layout, erasure coding was performed on demand by the HDFS client. We launched multiple clients to read/write different HDFS files in threads, and measured the total throughput. Each client reads/writes 12GB of data from/to a single HDFS file. The clients reside on a single-client node outside the cluster (no local DN), and different combinations of client network and DN disk were used. To exclude the impact of the client node’s local disk, we generated random input data in memory in writing tests, and discarded fetched data in reading tests. Stateful and positional reads were both tested and generated very similar results with our consolidated optimization; therefore, only stateful read results are included in this report. To test whether EC can efficiently recover from data loss, we also tested reading with two DNs killed.
- Use of DFSIO. We used DFSIO, the HDFS throughput benchmark in Intel’s HiBench test suite, to test the case where the HDFS clients are within the cluster. DFSIO launches a MapReduce job to write/read different files and calculate the total throughput. It can effectively measure the efficiency of MR IO-bounded workloads.
- Hive queries. We ran Hive queries on a 500GB TPC-H dataset and measured the time spent for each query. HDFS clients are distributed across the cluster. The focus of this test is reading, and therefore we only changed the storage mode for the table data between EC and replication. So far, we have tested two relatively simple queries: Query3 and Query6 from TPC-H, as well as
count(*). (We plan to add more CPU-intensive query workloads as future work.) MapReduce and Apache Spark were both tested as Hive’s execution engine.
All these tests are based on the default EC schema RS-6-3 with a 64KB cell size. To make the tests more consistent, we cleared page cache on all DNs before running tests that involve bulk reading from HDFS. The focus was on measuring I/O throughput, with each test repeated three times and the average throughput reported.
Codec Benchmark Results
Figures 1 and 2 show the encoding and decoding throughputs of different coders, with varying number of coding threads. The ISA-L coder consistently outperforms other coders by large margins. For example, as shown in Figure 1, even with 40 concurrent threads, it’s over 30x in throughput to the HDFS-RAID coder and 6x to the New Java coder. This result is because the underlying ISA-L library is implemented in native code and takes advantage of many advanced CPU instructions such as SSE, AVX, and AVX2. New Java coder outperforms the HDFS-RAID coder by leveraging Java’s auto-vectorization support. The throughput of the ISA-L coder is also much higher than common I/O devices. Therefore, it’s unlikely to become a bottleneck in I/O workloads.
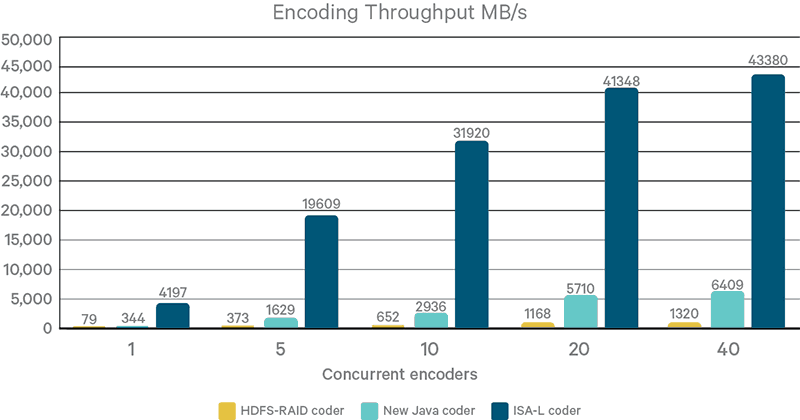
Figure 1. Concurrent encoders throughput compared
{kind=link}
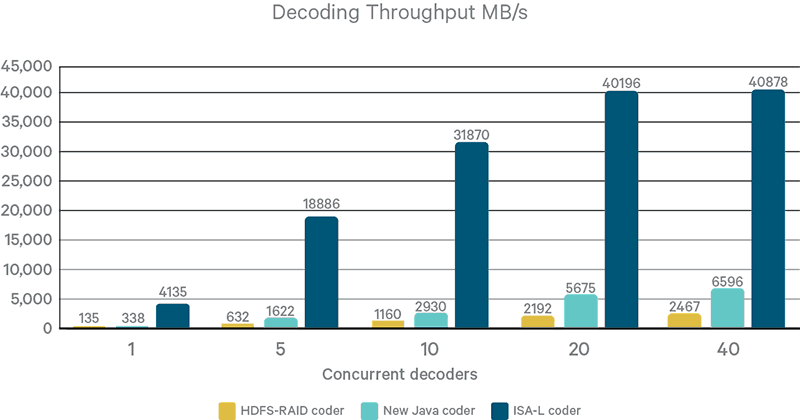
Figure 2. Concurrent decoders throughput compared
Another observation is that HDFS-RAID coder has a much lower encoding throughput than decoding, while both other coders have about the same performance in encoding and decoding. (The HDFS-RAID coder implements encoding in a different and less efficient way than decoding.) Interested readers should refer to HDFS-RAID code for more implementation details.
HDFS Client I/O Results
As discussed in our previous blog post, a key difference between the striping data layout and the existing contiguous/replication form is how they use network and storage devices. The striping layout tends to utilize multiple DN storage devices in parallel through the network, and therefore causes much more network traffic. Intuitively, it should achieve the most significant performance gain over replication in an environment with relatively fast networking and slow DN storage devices.
The rest of this section compares the I/O performance of EC with replication, and discusses how their performance is affected by hardware factors. We also varied the number of I/O threads to approach the saturation point of I/O devices. In total, we collected 160 data points resulting from different combinations on the following dimensions. For conciseness we have uploaded complete results in a separate file.
- Two network speeds: 10GB and 20GB
- Two storage devices: HDD and SSD
- Four policies to compare: 3x replication; EC with HDFS-RAID coder, new Java coder, and ISA-L coder
- Three scenarios: write, read without DN failure (only comparing replication and EC since no codec calculation is involved), read with two DN failures
- Four concurrency levels: 1, 5, 10, and 20 concurrent I/O threads
Single HDFS Client
First, we analyzed performance results with a single HDFS client (on the external node), ruling out the impact of network and disk contention.
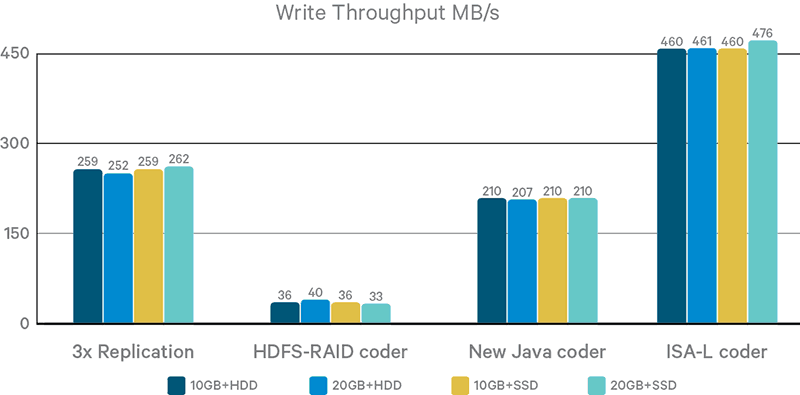
Figure 3. Single-thread write throughput
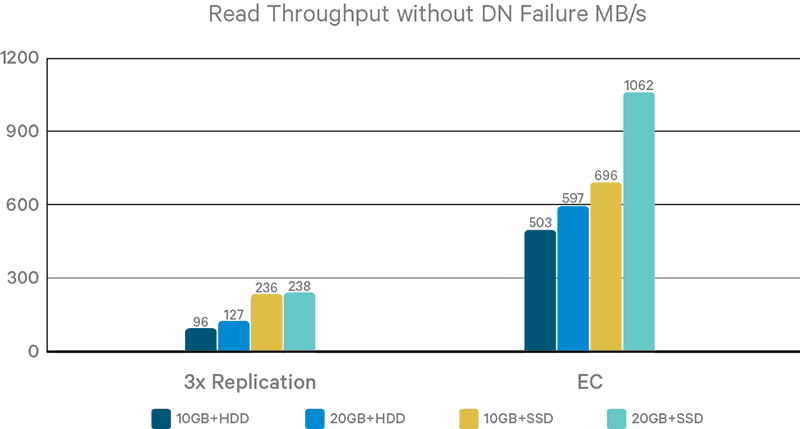
Figure 4. Single-thread read throughput without DN failures
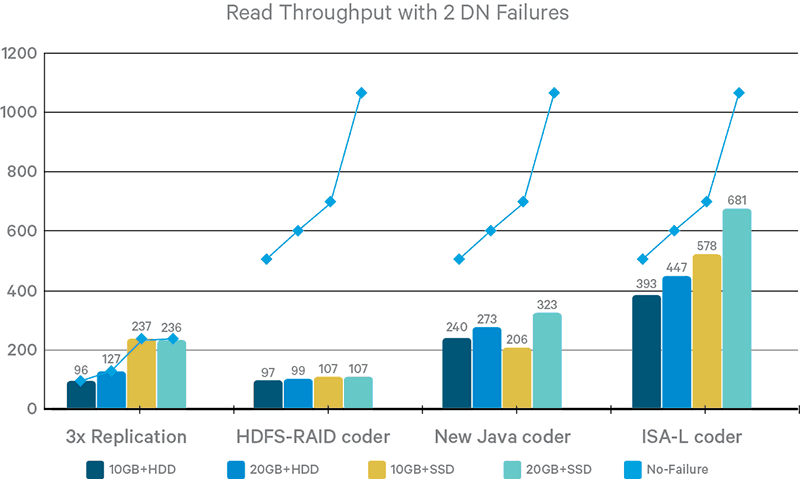
Figure 5. Single-thread read throughput with two DN failures
As explained in the “Codec Benchmark Results” above, the ISA-L coder is the fastest coder by a large margin (up to 50x). The above figures further illustrate how its superior codec performance translates to high I/O throughput. EC with the ISA-L coder outperforms the other two coders, as well as 3x replication mode, in all tested I/O scenarios and hardware configurations.
The figures also present interesting observations on the impact of networking and storage devices. These observations reveal potential improvements on EC implementation and shed insights on the deployment of EC in production environments.
Figure 3 shows write throughput results. On the write path, EC calculates parity blocks through encoding, and writes to all DNs hosting data or parity blocks concurrently. This parallelism makes its throughput over 75% higher than 3x replication. However, the write throughput under EC as well as replication remains the same with different hardware devices. This fact indicates a lot of room of improvement on the write path to fully utilize faster networking and storage.
In Figure 4, we compare the read throughput between replication and EC modes. No DN was killed during the test so EC coders are not relevant. By reading from multiple DNs in parallel, EC outperforms replication by 1.9x to 4.2x. Replication mode throughput is always constrained by storage device speed, and there is a large performance gap between HDD and SSD settings. In contrast, EC is impacted by both storage and networking. With the default 6+3 coding schema, EC reads from six DNs in parallel. Therefore, the theoretical throughput upper limit under the 10GB+HDD, 20GB+HDD, and 20GB+SSD settings is still bounded by aggregate storage device bandwidth (840MB/s for HDD and 1440MB/s for SSD).
The current EC implementation is capable of saturating 60% to 74% of this limit, hence there remains some room for improvement. With the 10GB+SSD setting, the client networking bandwidth is narrower than the aggregate storage bandwidth, and EC saturates 54% of it. Although EC has not saturated aggregate HDD bandwidth in 10GB+HDD and 20GB+HDD settings, upgrading to SSD still brings significant performance gains: 10GB+SSD is 38% faster than 10GB+HDD, and 20GB+SSD is 78% faster than 20GB+HDD. Based on our initial DN local I/O profiling, this is because the striping layout increases the interval for a DN to receive read requests, making it harder for DN local OS to merge small requests before sending to disk. A potential optimization is to configure DN page cache with more aggressive readahead.
Finally, Figure 5 presents results when two DNs are killed during the reading test. As you can see, replication mode supplies the requested data with almost no performance degradation; the client basically switched to a healthy replica. EC with HDFS-RAID or New Java coders suffer from a recovery overhead of 85% and 62% respectively. In contrast, EC with ISA-L coder only incurs a 25% performance degradation.
Multiple HDFS Clients
With multiple HDFS clients (all on the external node), it is easier to fully utilize networking and storage bandwidth. Meanwhile, it also creates multiple overheads, including I/O congestion and the cost to manage threads.
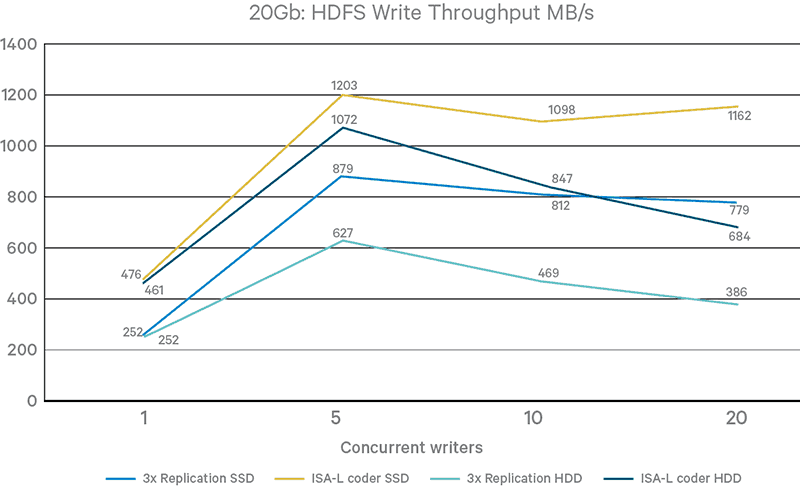
Figure 6. Multiple-thread write throughput
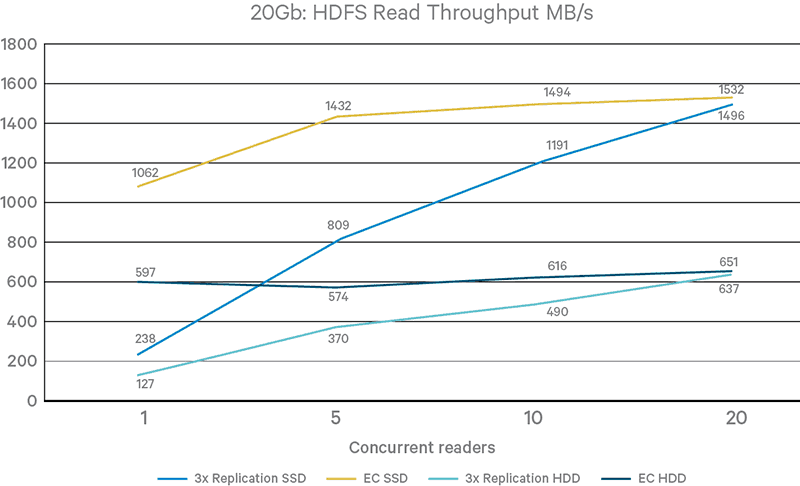
Figure 7. Multiple-thread read throughput without DN failure
Figures 6 and 7 provide throughput results with 1, 5, 10, and 20 client I/O threads on the external node. It is clear that EC with the ISA-L coder reaches a saturation point with five threads in all cases, while it takes up to 20 threads under the 3x replication mode to reach the same maximum throughput.
Another notable observation is that certain test cases suffer significant performance degradation with more than five threads. Potential improvements can be achieved through more efficient thread handling and memory buffering.
DFSIO Results
We ran the DFSIO benchmark with different numbers of mappers, where each mapper processes a 12GB file. The mappers run within the cluster, which means they work on locally stored data under the 3x replication mode. Each DN has 10GB network and 1 SSD. Cache is also dropped before test reading.
Please note that due to limits on our testing environment, DN servers don’t have AVX2 support, which means HDFS clients running on DNs are not able to take full advantage of the ISA-L coder.
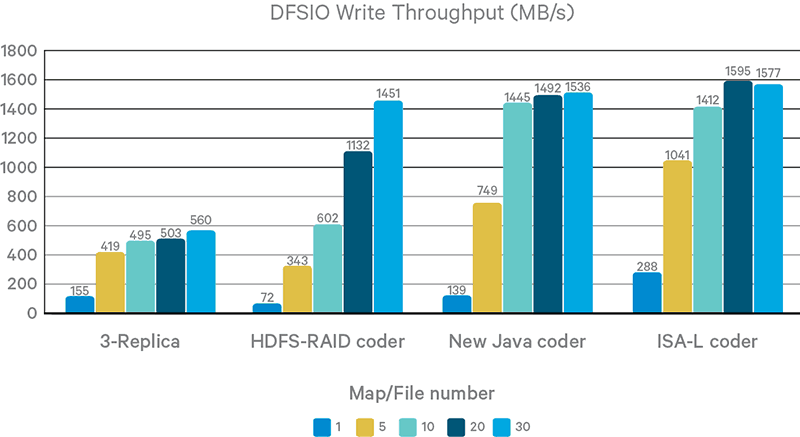
Figure 8. DFSIO write throughput
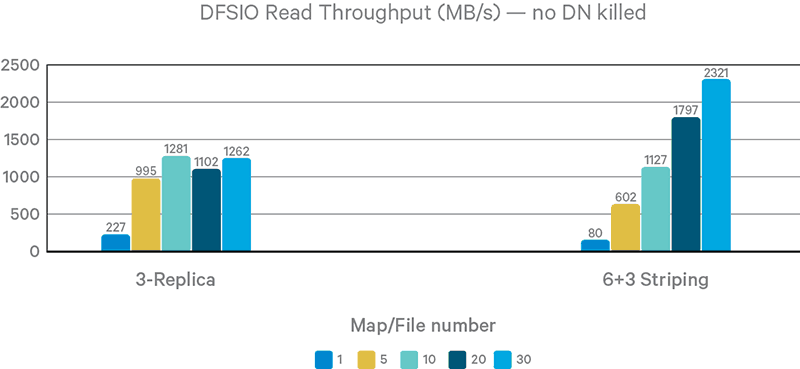
Figure 9. DFSIO read throughput without DN failure
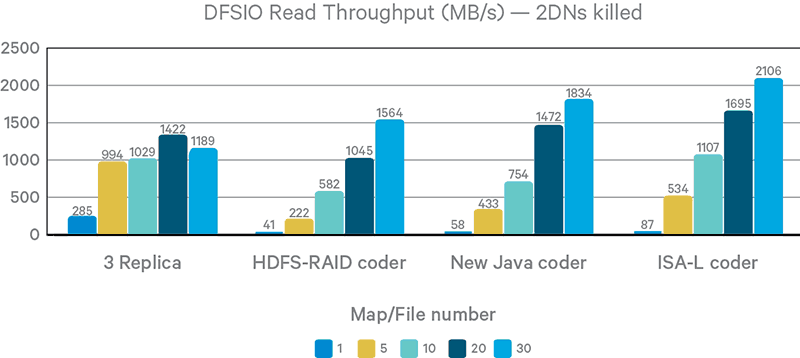
Figure 10. DFSIO read throughput with DN failure
Although EC breaks data locality, it still outperforms 3x replication in writing tests because the original HDFS write pipeline is not fully optimized. For example, there is no support for short-circuit writing to the local filesystem. However, in reading tests with fewer mappers, EC is slower than 3x replication. Thanks to short-circuit local reading, 3x replication almost saturates local SSD throughput.
Again, ISA-L performs best among the coders, despite the lack of AVX2 support on the DNs.
Hive Query Results
We ran the Hive queries against a 500GB TPC-H dataset. Since ISA-L is identified as the best coder in previous tests, we only used ISA-L for EC mode. Each DN has 10Gbps network and one SSD. Cache is dropped before each query.
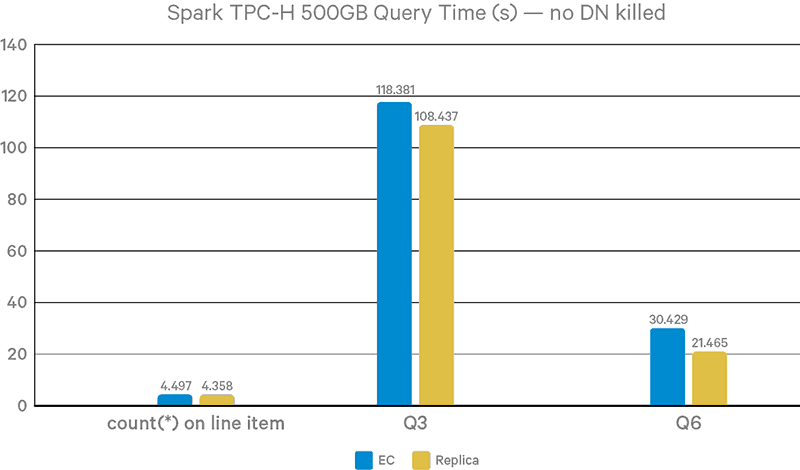
Figure 11. Query completion time without DN failures
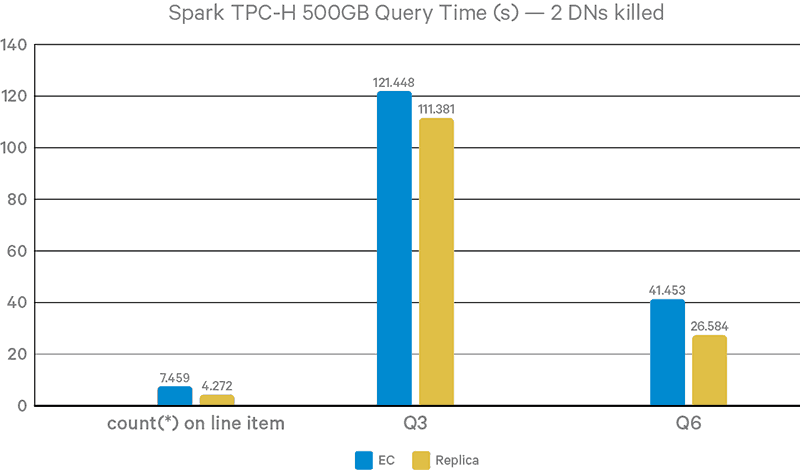
Figure 12. Query completion time with 2 DN failures in runtime
Figures 11-12 show query performance results with Hive-on-Spark. Due to the lack of data locality, EC is 9% slower than 3x replication in Query3 queries and 42% slower in Query6. This result is because data locality mostly affects map tasks, and Query6 has a much larger portion of map tasks than Query3. Query3 has multiple reduce stages, where data locality doesn’t have a large impact. With two DNs killed during queries, the overhead of EC remains the same for Query3 and grows to 58% for Query6. Besides the cost of reading parity data and decoding, another factor is the competition of CPU cycles with Spark, which is also CPU-intensive.
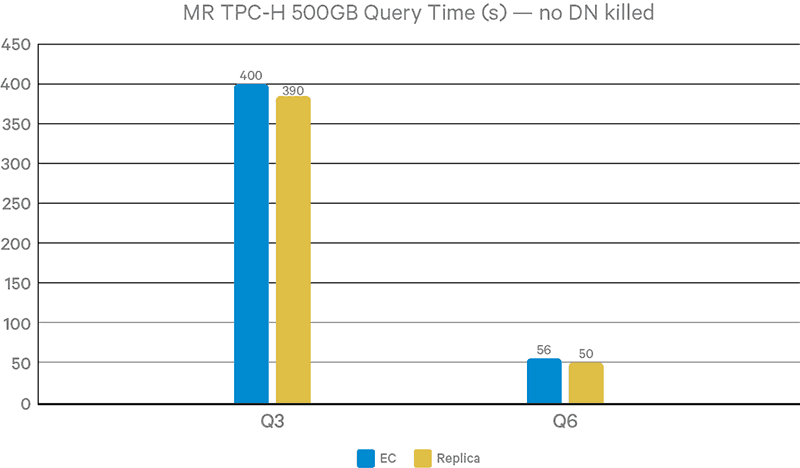
Figure 13. Query completion time without DN failure (Hive+MapReduce)
To verify the impact of CPU contention, we repeated the tests without DN failure on Hive-on-MapReduce, which is less CPU-intensive. It can be seen that EC causes much lower overhead compared with Hive-on-Spark results: 3% for Query3 and 12% for Query6. This is because MapReduce has more overhead than Spark. Therefore, a smaller portion of job execution time is spent on actual I/O operations.
Conclusion
This testing suggests that when using the Intel ISA-L library and Hadoop ISA-L coder, the performance bottleneck of EC shifts from CPU calculation to network and disk IO. Therefore, the ISA-L coder is recommended as long as the cluster has the required CPU models.
Another important observation is that the striped block layout often achieves much higher throughput than current HDFS chain replication by more efficiently utilizing high-speed networks. However, for workloads that are optimized for data locality, the contiguous block layout still has performance benefits.
Thanks to this testing, we have also identified a number of important bugs and performance issues. (They have been tracked under the umbrella JIRA HDFS-8031 among other follow-on tasks for HDFS-EC phase 1.) Among the most promising performance optimizations are reducing coordination overhead across client writing threads, and optimizing DN disk I/O through smarter page-cache settings. Interested readers are encouraged to repeated the tests by checking out the Hadoop trunk and applying related work-in-progress patches (including ISA-L coder, new Java coder, and various client striped I/O optimizations).
The community has also started design of HDFS-EC Phase 2 to support EC with contiguous block layout. This work will allow EC to perform more efficiently with locality-sensitive workloads, and enable files to be converted more transparently between hot and cold modes.
Acknowledgements
The authors would like to thank Weihua Jiang for leading this performance benchmark work and providing valuable guidance to the team, intern Minglei Zhang for performing concrete benchmark tests, and Lifeng Wang for the help in verifying the TPC-H test results.
Rui Li is a Software Engineer at Intel, and an Apache Hive committer.
Zhe Zhang is a Software Engineer at Cloudera, and an Apache Hadoop committer.
Kai Zheng is a Software Engineer at Intel.
Andrew Wang is a Software Engineer at Cloudera, and a member of the Apache Hadoop PMC.
Editor's Choice

