


Background
Apache Hive is a widely adopted data warehouse engine that runs on Apache Hadoop. Features that improve Hive performance can significantly improve the overall utilization of resources on the cluster. Hive processes data using a chain of operators within the Hive execution engine. These operators are scheduled in the various tasks (for example, MapTask, ReduceTask, or SparkTask) of the query execution plan. Traditionally, these operators are designed to process one row at a time. Operators that process one row at a time are not very efficient because many virtual function calls are needed to process each row scanned. In addition, modern CPU architectures that support SIMD instruction sets (such as SSE or AVX) cannot be leveraged when operators process one row at a time. This blog post gives a brief overview of how we can leverage SIMD based optimizations in Hive to give up to 26% improvement in query runtimes on Apache Parquet tables.
CPU Vectorization
Vectorization is the process of converting an algorithm from operating on a single value at a time to operating on a set of values at one time. Modern CPUs provide direct support for vector operations where a single instruction is applied to process multiple data points (SIMD).

The figure above shows a simple example of addition of two sets of values using scalar as well as vector instructions.
For example, a CPU which supports the AVX-512 instruction set provides 512-bit registers that can hold up to sixteen 32-bit values and do simple operations like addition in one instruction when compared to doing the same calculation in 16 scalar instructions. In this example, a vectorized execution will run 16 times faster than a scalar execution.
Vectorization in Hive
To take advantage of these optimization opportunities, Hive introduced vectorized query execution in HIVE-4160. Vectorized query execution introduces new operators and expressions that process a batch of rows together instead of processing one row at a time. Compared to row-based execution, vectorized execution avoids large numbers of virtual function calls, which improves the instruction and data cache hit rates. It takes better advantage of instruction pipeline of modern CPUs (such as Intel® Xeon® Scalable processors) and can also leverage the Intel SSE/AVX instruction set to parallelize data processing at the CPU level. This can lead to significant performance improvement during query execution. More details on the vectorization in Hive can be found in the original design document for vectorization here (PDF).
Parquet Vectorized Reader
Apache Parquet is a widely used columnar file format in big data ecosystems. However, the Parquet file format doesn’t provide a vectorized reader for Hive. This means that even when vectorization is turned on for your cluster, all the map tasks that read Parquet data process the data one row at a time. So queries using Parquet tables miss out on the performance gains of vectorized query execution. To improve this, Cloudera and Intel collaborated closely to introduce Hive Parquet Vectorization in HIVE-14826. The Parquet vectorized reader returns column batches of rows instead of one row at a time. The column batch can be passed to the operator tree without any intermediate conversion. Implementing the vectorized parquet reader on the Hive side instead of in the Parquet library further improves performance by avoiding an extra memory copy action to create the batches. This feature is available in Cloudera’s distribution of Apache Hive from CDH 6.0 onwards.
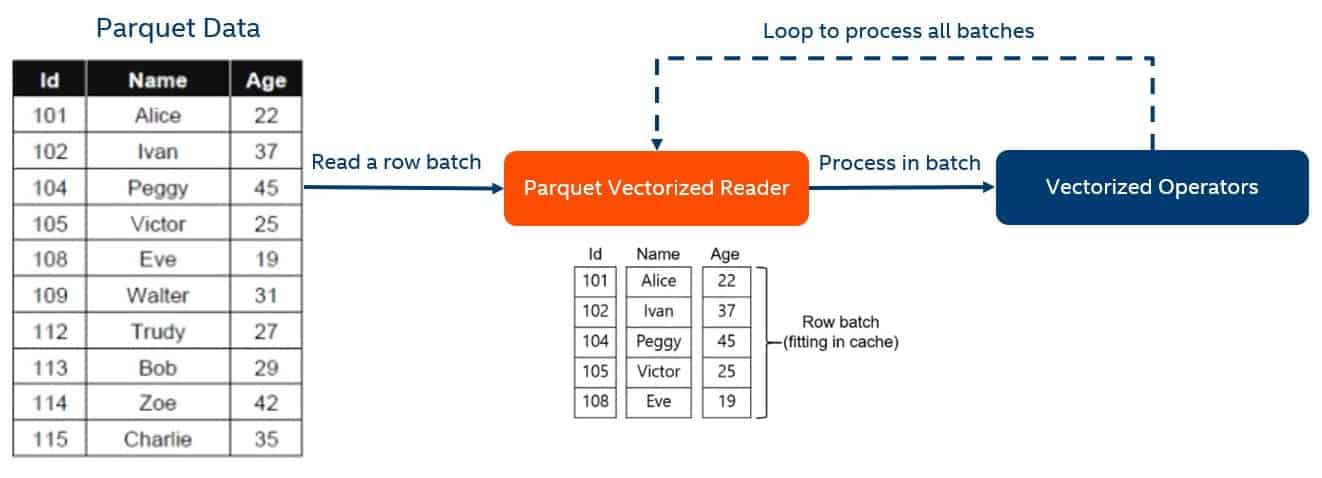
Known Limitations
Besides primitive types like string, integer, or double, Parquet also supports complex types like struct, list, or map. The current vectorized reader implementation can handle only primitive types and struct types which do not have nested complex types. Support for nested complex type handling is currently a work in progress. When queries process complex types like list or map or struct in the case of nested complex types, query execution falls back to non-vectorized execution. A full list of supported data types is available here.
Using Parquet Vectorization
Hive vectorization is enabled by default in CDH 6.0. If you want to enable it at a session level, you can use the set command to set hive.vectorized.execution.enabled configuration property to true using the following command. This property is set to true by default in CDH 6.0.
set hive.vectorized.execution.enabled=true;
Users can control whether vectorization is enabled for specific file formats by using the configuration property hive.vectorized.input.format.excludes. This configuration takes a comma separated list of fully qualified class names for various file formats. Any file format which is added to this configuration will not be vectorized. For example, to disable vectorization for Parquet tables only, set hive.vectorized.input.format.excludes to org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat. These configuration properties can be set in the Hive configuration section of Cloudera Manager (CM). More details about the different configurations related to vectorization can be found in the documentation.
Performance Results
We evaluated Parquet vectorization performance on a 4-node Skylake cluster (Xeon Gold 6140) with Hive on Spark. The workload run was TPC-DS on 3TB data scale. We used both CDH 5.15.1 and CDH 6.0 to get a comparison performance of different versions of CDH. Below are the hardware and software configurations we used:
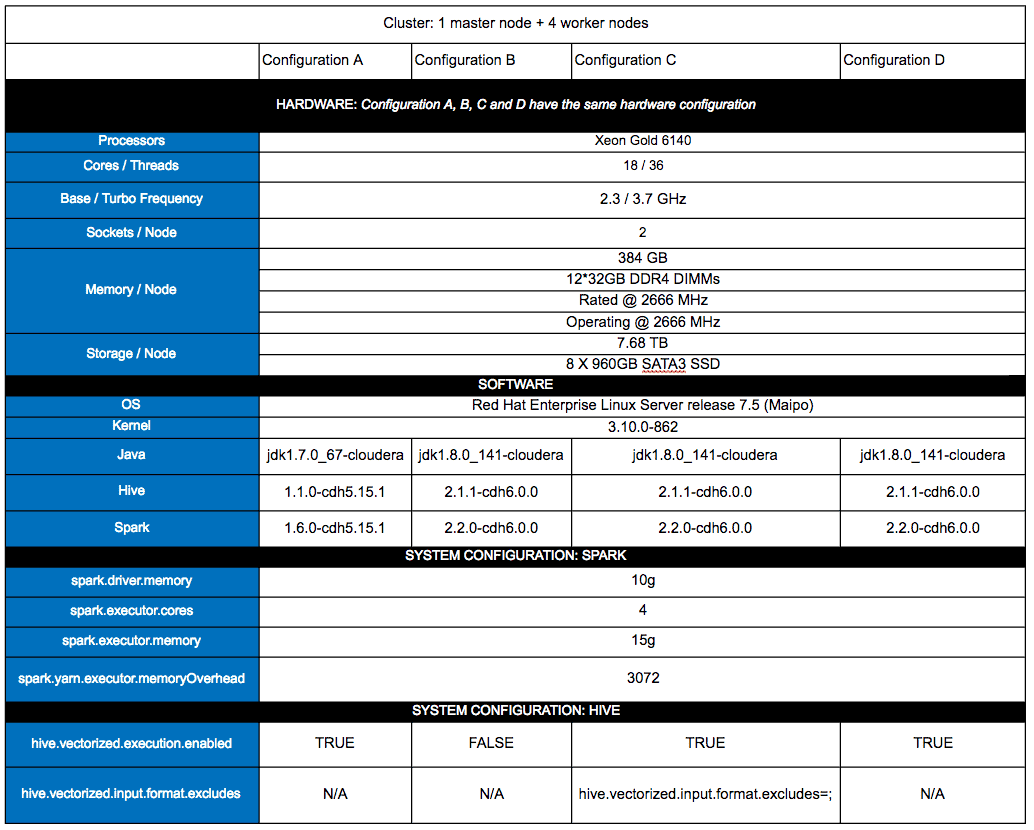
Configuration A is the cluster which runs the baseline using CDH 5.15.1 which does not include the Parquet vectorization feature. Configuration B is the cluster where CDH 6.0 is installed with default set of configurations which disables Parquet vectorization. Configuration C is the cluster where CDH 6.0 is installed and the Parquet vectorization feature is enabled. We ran 55 queries from the TPC-DS workload.
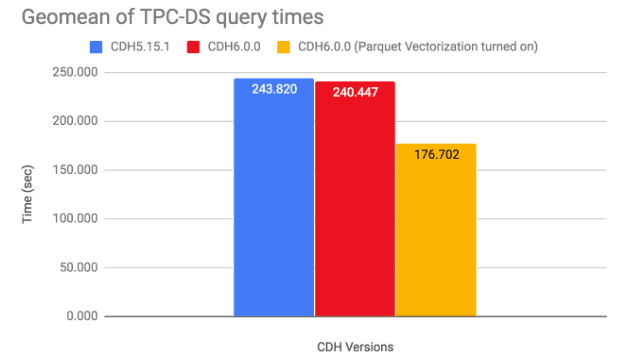
We saw significant performance improvements from this feature. The geomean query time of all the queries was improved from 243.82 seconds in CDH 5.15.1 seconds to 176.70 seconds using Parquet vectorization in CDH 6.0, which is a 1.36x performance gain over CDH 5.15.1.
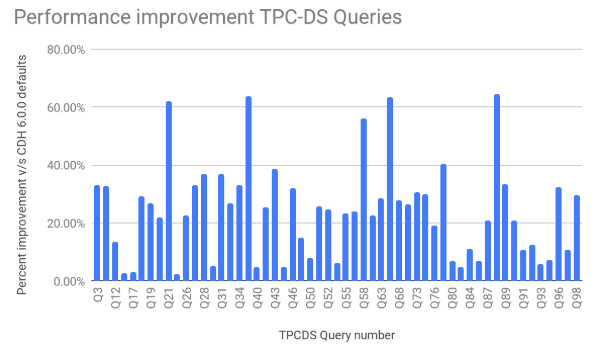
The following figure shows the percentage improvement in run times of various TPC-DS queries compared to CDH 6.0 defaults (which disables parquet vectorization). Five queries (q21, q39, q58, q66, q88) show over a 50% performance gain while many of the rest of the queries show between 20% to 40% performance gain in runtime.
Conclusion
The performance benchmarks on CDH 6.0 show that enabling Parquet vectorization significantly improves performance for a typical ETL workload. In the test workload (TPC-DS), enabling parquet vectorization gave 26.5% performance improvement on average (geomean value of runtime for all the queries). Vectorization achieves these performance improvements by reducing the number of virtual function calls and leveraging the SIMD instructions on modern processors. A query is vectorized in Hive when certain conditions like supported column data-types and expressions are satisfied. However, if the query cannot be vectorized its execution falls back to a non-vectorized execution. Overall, for workloads which use the Parquet file format on most modern processors, enabling Parquet vectorization can lead to better query performance in CDH 6.0 and beyond.
Vihang Karajgaonkar is a Software engineer at Cloudera.
Santosh Kumar is a Senior Product Manager at Cloudera.
Haifeng Chen is a Senior Engineering Manager at Intel.
Cheng Xu is an Engineering Manager at Intel.
Wang Lifeng is a Software Engineer at Intel.
Editor's Choice

