

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
(This Blogpost is coauthored by Xun Liu and Quan Zhou from Netease).
Introduction
Hadoop is the most popular open source framework for the distributed processing of large, enterprise data sets. It is heavily used in both on-prem and on-cloud environment.
Deep learning is useful for enterprises tasks in the field of speech recognition, image classification, AI chatbots, machine translation, just to name a few. In order to train deep learning/machine learning models, frameworks such as TensorFlow / MXNet / Pytorch / Caffe / XGBoost can be leveraged. And sometimes these frameworks are used together to solve different problems.
To make distributed deep learning/machine learning applications easily launched, managed and monitored, Hadoop community initiated the Submarine project along with other improvements such as first-class GPU support, Docker container support, container-DNS support, scheduling improvements, etc.
These improvements make distributed deep learning/machine learning applications run on Apache Hadoop YARN as simple as running it locally, which can let machine-learning engineers focus on algorithms instead of worrying about underlying infrastructure. By upgrading to latest Hadoop, users can now run deep learning workloads with other ETL/streaming jobs running on the same cluster. This can achieve easy access to data on the same cluster and achieve better resource utilization.

A typical deep learning workflow: data comes from the edge or other sources, and lands in the data lake. Data-scientists can use notebooks to do explorations, create pipelines to do feature extraction/split train/test data set. And run deep learning training jobs. These processes could be done repeatedly. So, running deep learning jobs on the same cluster can bring efficiency for data/computation-resource sharing.
Let’s take a closer look at Submarine project (which is part of the larger Apache Hadoop project) and see how one can run these deep learning workloads on Hadoop.
Why this name?
Because Submarine is the only vehicle that can take humans to deeper grounds. B-)

Image courtesy of the NOAA Office of
Ocean Exploration and Research, Gulf of Mexico 2018.
Overview of Submarine
Submarine project has two parts: Submarine computation engine and a set of submarine ecosystem integration plugins/tools.
Submarine computation engine submits customized deep learning applications (like Tensorflow, Pytorch, etc.) to YARN from command line. These applications run side by side with other applications on YARN, such as Apache Spark, Hadoop Map/Reduce, etc.
On top of that, we have a set of Submarine ecosystem integrations, currently including:
- Submarine-Zeppelin integration: Allow data scientists coding inside Zeppelin notebook, and submit/manage training jobs directly from the notebook.
- Submarine-Azkaban integration: Allow data scientist to submit a set of tasks with dependencies directly to Azkaban from notebooks.
- Submarine-installer: Install submarine and YARN on your environment for you to easier try the powerful toolset.
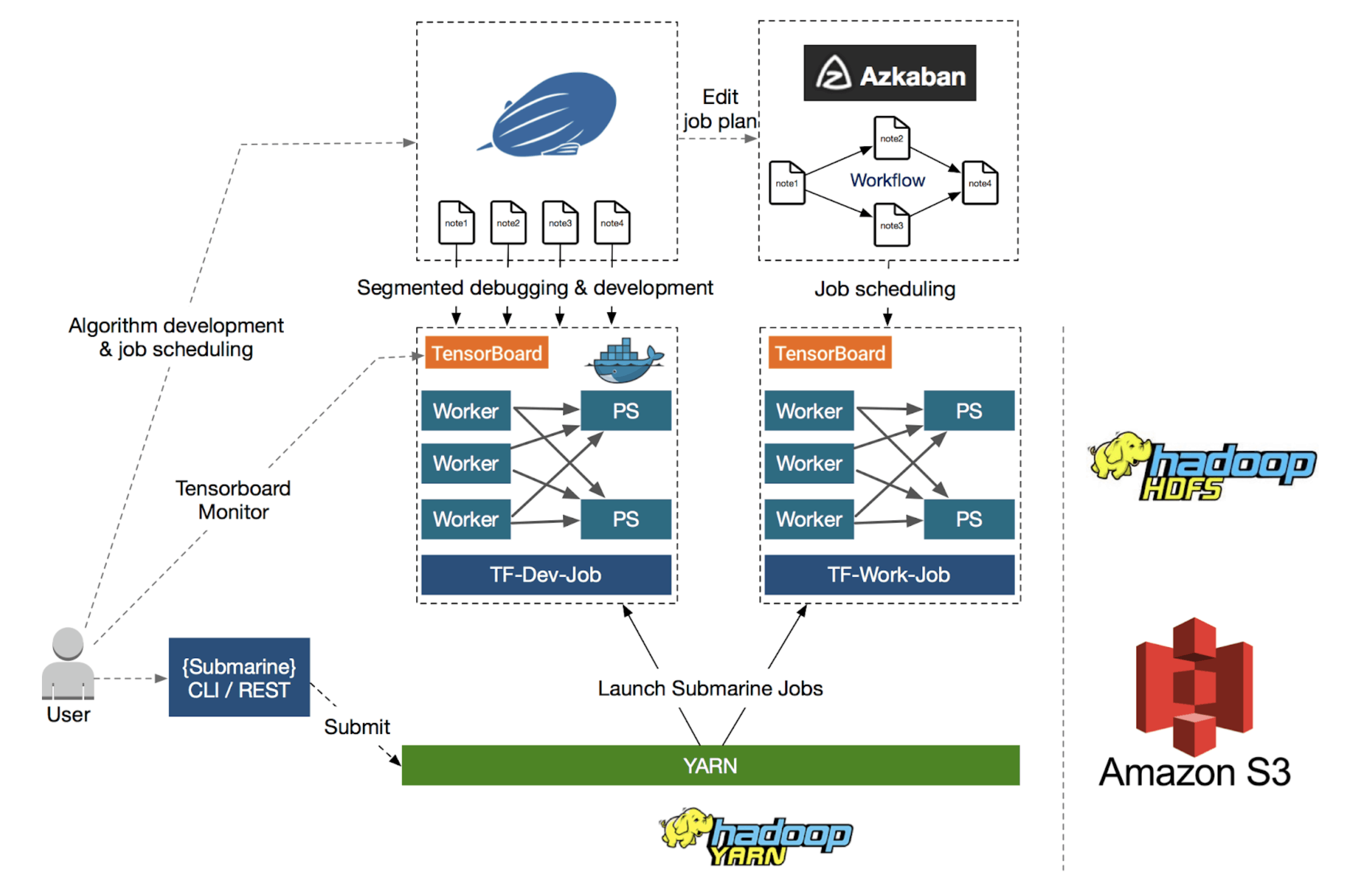
A diagram illustrates Submarine, bottom shows Submarine computation engine, it is just another YARN application. On top of the computation engine, it integrates to other ecosystems such as notebook (Zeppelin/Jupyter) and Azkaban.
What Submarine computation engine can do?
By using Submarine computation engine, users c\an simply submit a simple CLI to run single/distributed deep learning training jobs and get your notebook from YARN UI. All other complexities such as running distributed etc will take care by YARN. Let’s take a look at a few examples:
Launch Distributed Deep Learning Training job like Hello world.
Following command launches a deep learning training job reads cifar10 data on HDFS. The job is using user-specified Docker image, sharing computation resources (like CPU/GPU/Memory) with other jobs running on YARN.
| yarn jar hadoop-yarn-applications-submarine-<version>.jar job run \ –name tf-job-001 –docker_image <your docker image> \ –input_path hdfs://default/dataset/cifar-10-data \ –checkpoint_path hdfs://default/tmp/cifar-10-jobdir \ –num_workers 2 \ –worker_resources memory=8G,vcores=2,gpu=2 \ –worker_launch_cmd “cmd for worker …” \ –num_ps 2 \ –ps_resources memory=4G,vcores=2 \ –ps_launch_cmd “cmd for ps” |
Access all your job training history on the same tensorboard
Following command launches a deep learning training job reads cifar10 data on HDFS.
| yarn jar hadoop-yarn-applications-submarine-<version>.jar job run \ –name tensorboard-service-001 –docker_image <your docker image> \ –tensorboard |
On the YARN UI, the user can access tensorboard by a simple click:

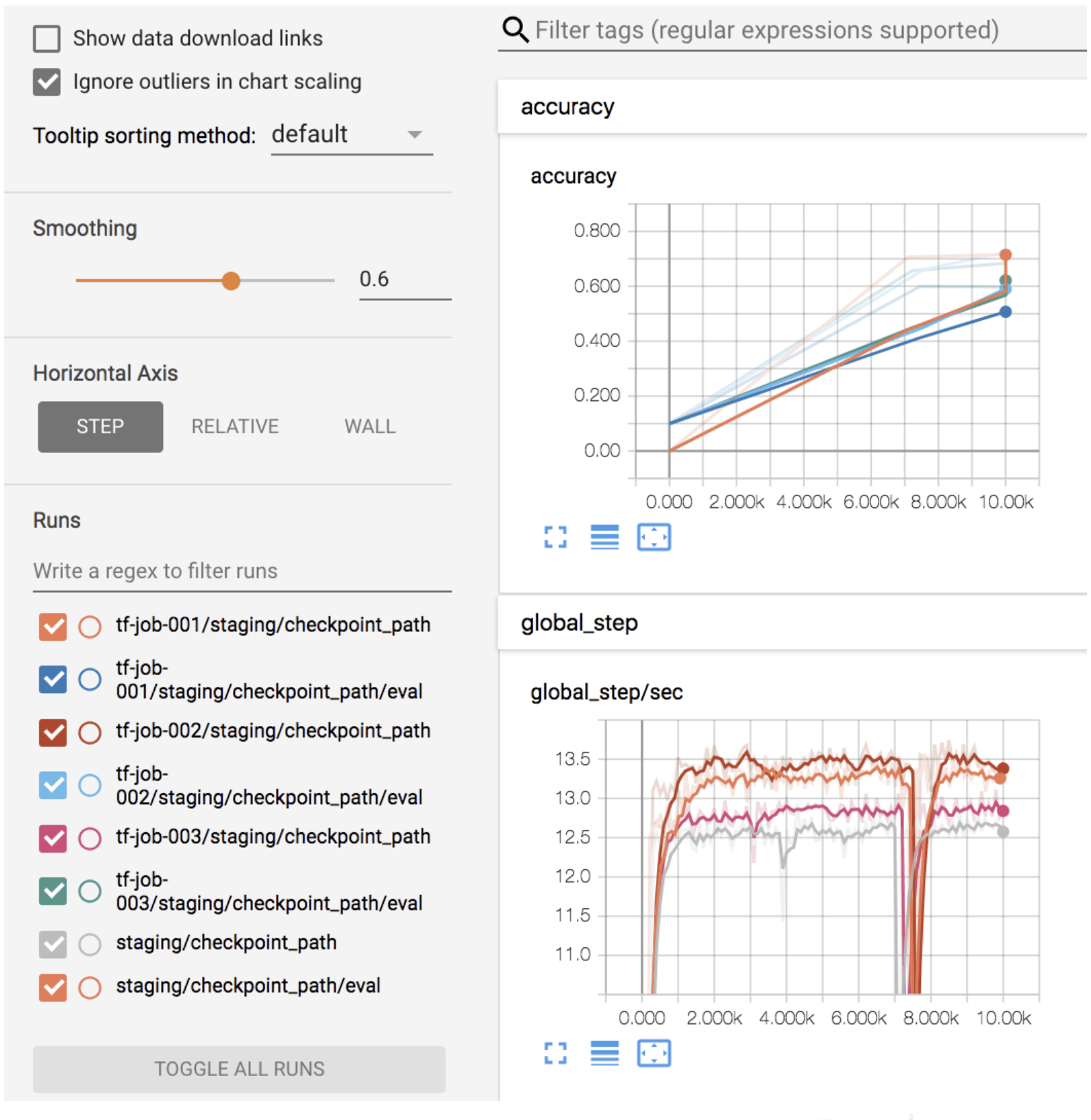
Viewing job training status and histories on the same Tensorboard.
Cloud notebook for data scientists
Wanna to write your algorithms from notebooks on a GPU machine? Using Submarine you can get cloud notebook from YARN resource pools.
By running the command below, you can get a notebook which includes 8GB memory, 2 vcores and 4 GPUs from YARN.
| yarn jar hadoop-yarn-applications-submarine-<version>.jar job run \ –name zeppelin-note—book-001 –docker_image <your docker image> \ –num_workers 1 \ –worker_resources memory=8G,vcores=2,gpu=4 \ –worker_launch_cmd “/zeppelin/bin/zeppelin.sh” \ –quicklink Zeppelin_Notebook=http://master-0:8080 |
Then on YARN UI, you can access the notebook by a single click.

Submarine Ecosystem Projects
The goal of the Hadoop Submarine project is to provide the service support capabilities of deep learning algorithms for data (data acquisition, data processing, data cleaning), algorithms (interactive, visual programming and tuning), resource scheduling, algorithm model publishing, and job scheduling.
By combining with Zeppelin, it is obvious that the data and algorithm can be solved. Hadoop Submarine will also solve the problem of job scheduling with Azkaban. The three-piece toolset: Zeppelin + Hadoop Submarine + Azkaban will provide an open and ready-to-use deep learning development platform.
Zeppelin integration with Submarine
Zeppelin is a web-based notebook that supports interactive data analysis. You can use SQL, Scala, Python, etc. to make data-driven, interactive, collaborative documents.
You can use the more than 20 interpreters in Zeppelin (for example Spark, Hive, Cassandra, Elasticsearch, Kylin, HBase, etc.) to collect data, clean data, feature extraction, etc. in the data in Hadoop before completing the machine learning model training. The data preprocessing process.
We provided Submarine interpreter in order to support machine learning engineers doing development from Zeppelin notebook, and submit training jobs directly to YARN job and get results from notebook.
Use submarine interpreter of Zeppelin
You can create a submarine interpreter notebook in Zeppelin.
Enter ‘%submarine.python’ repl in the notebook and start to code the python algorithm for tensorflow.
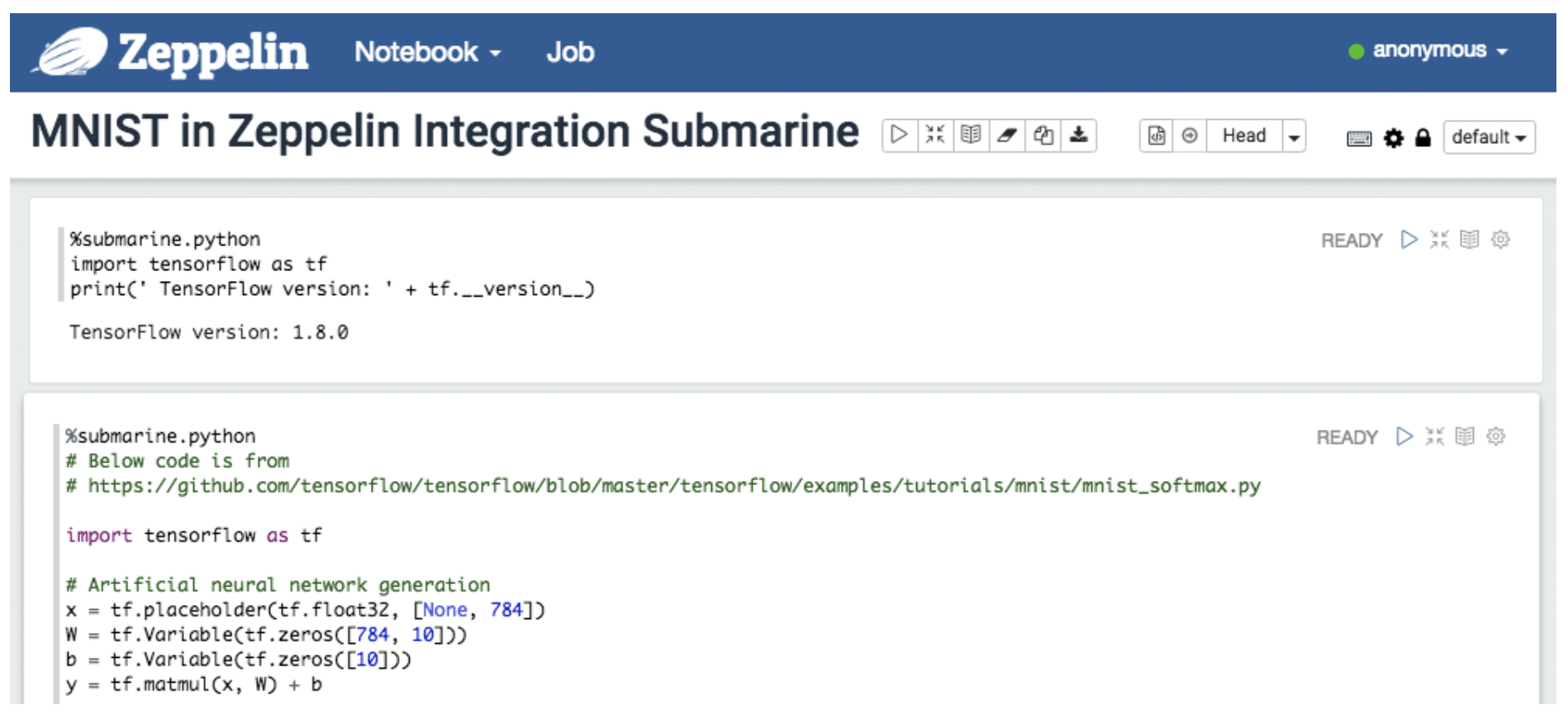
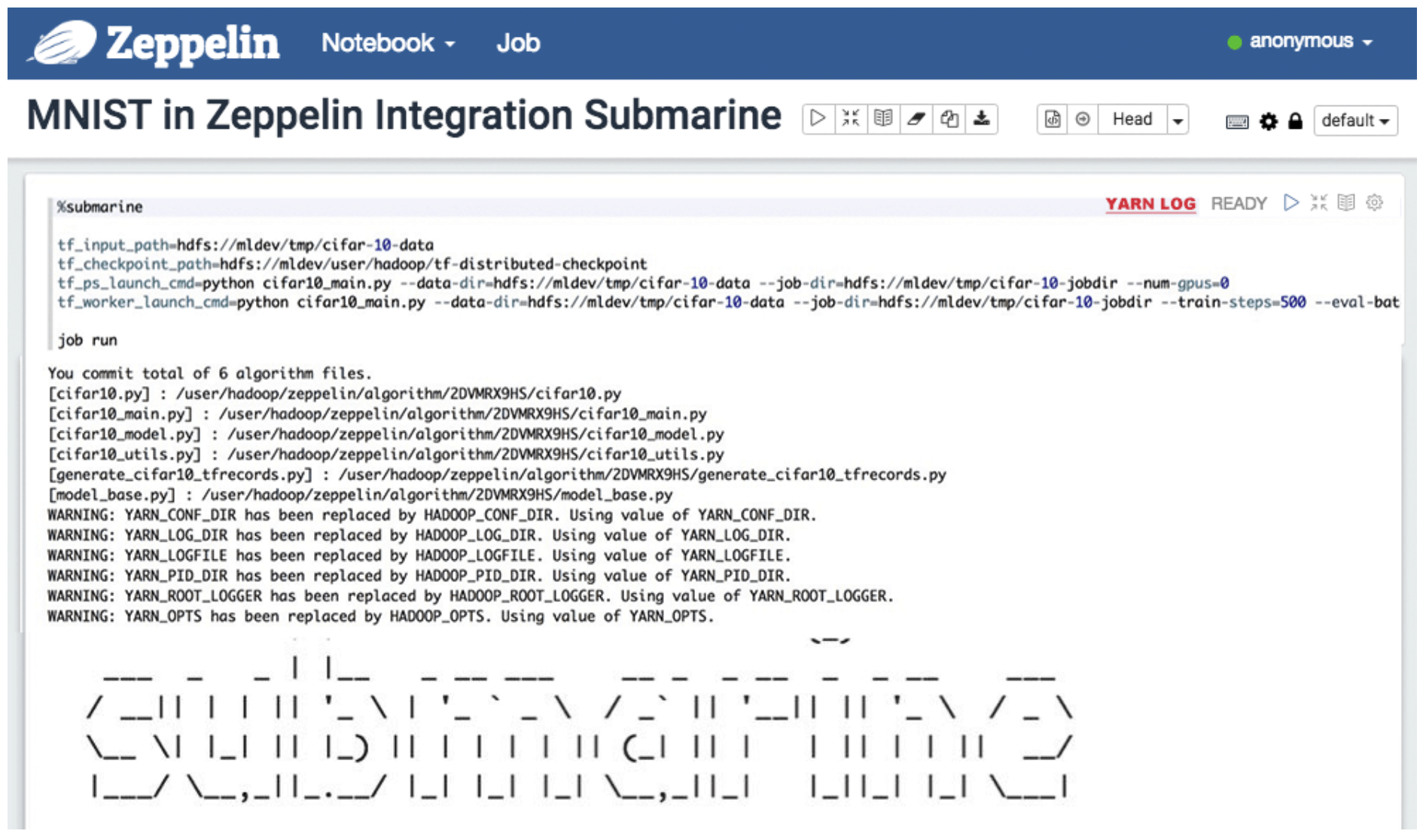
The zeppelin submarine interpreter automatically merges the algorithm files into sections and submits them to the submarine computation engine for execution.
By clicking on the “YARN LOG” hyperlink in the notebook, you can open the YARN management page to view the execution of the task.
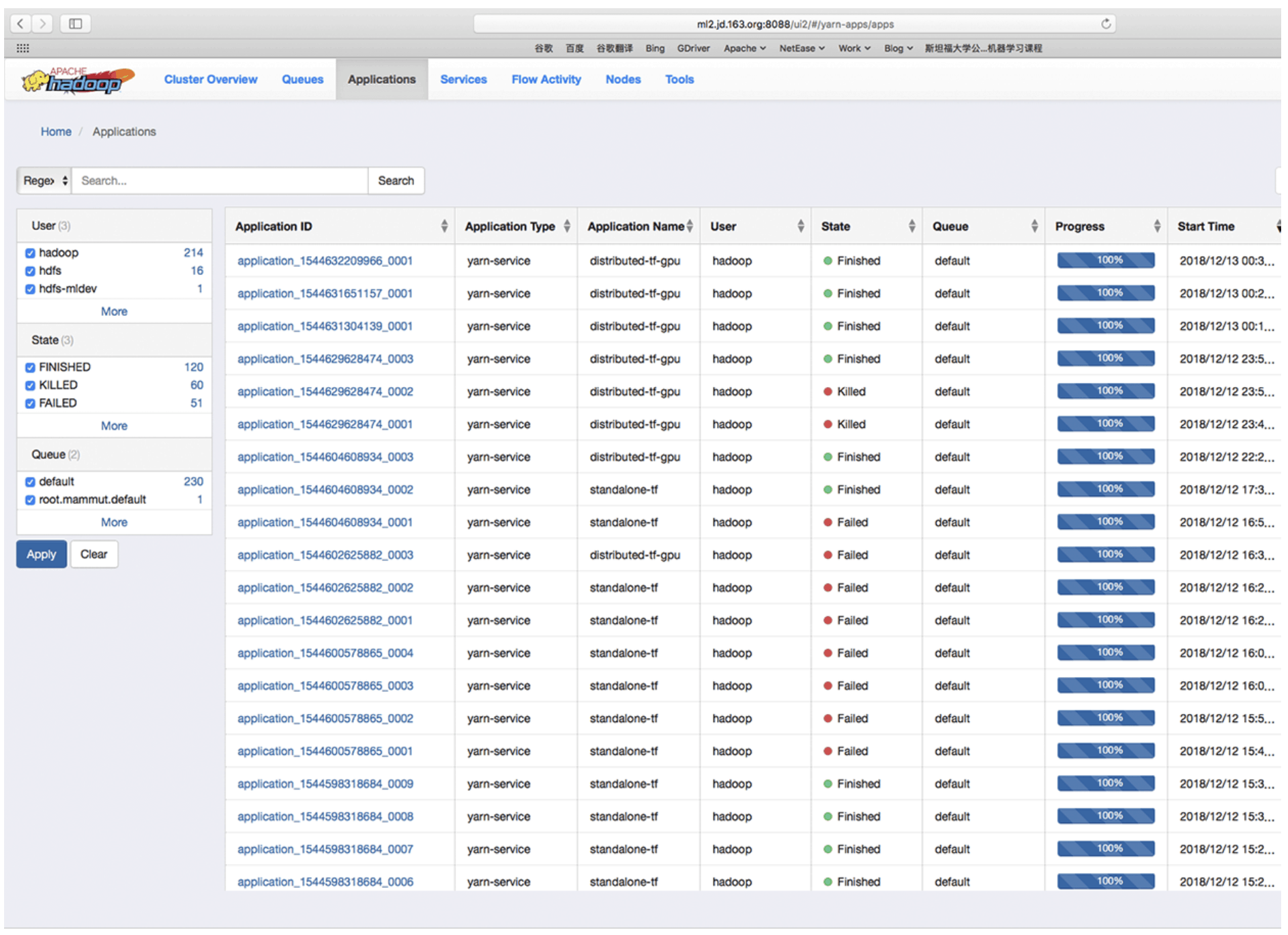
In the YARN management page, you can open your own task link, view the task’s docker container usage clear and all execution logs.
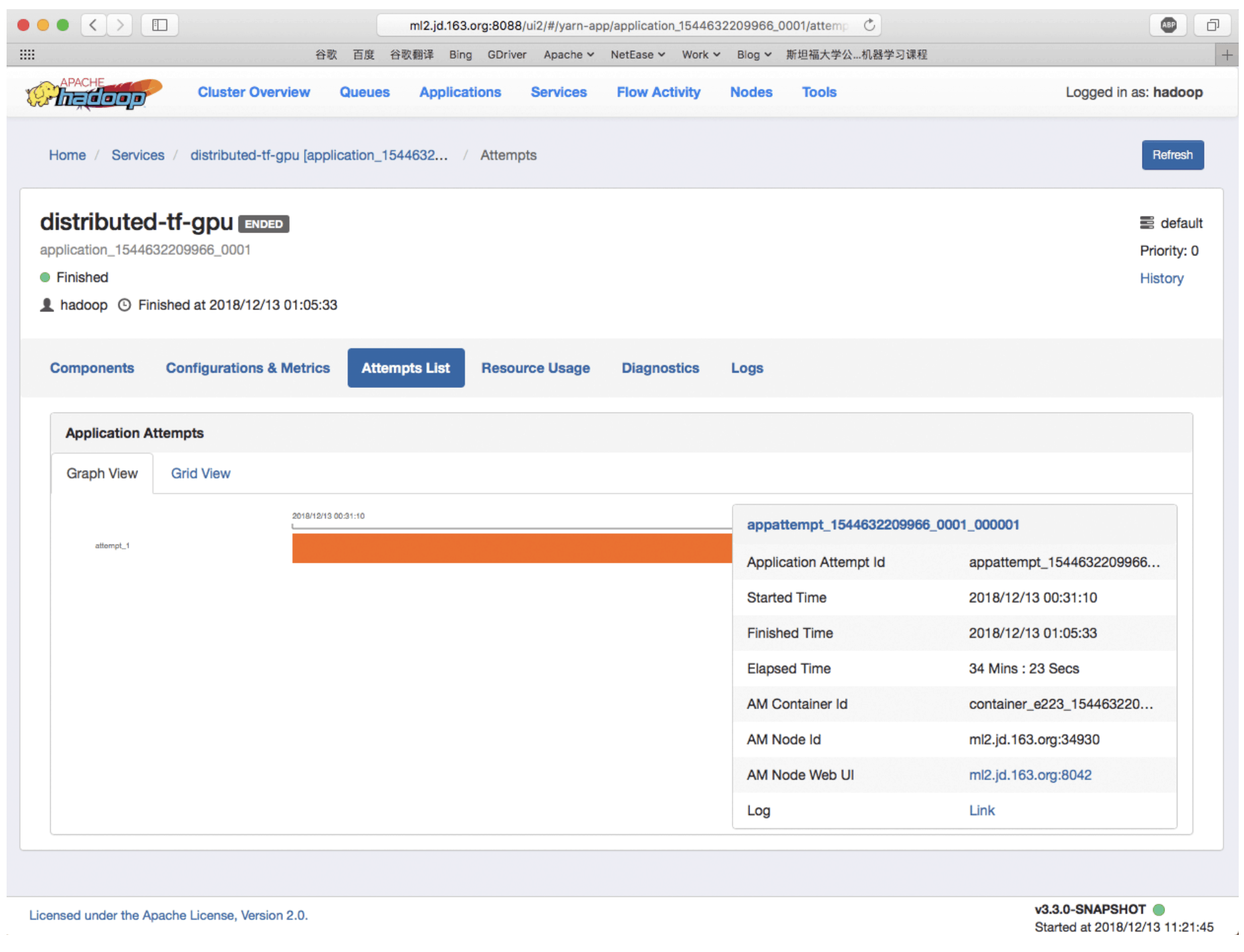
With this powerful tool, data scientists don’t need to understand complexities of YARN or how to use Submarine computation engine. Submitting a Submarine training job is exactly the same as run Python scripts inside notebook. And most importantly, users don’t need to change their program in order to run as Submarine jobs.
Azkaban integration with Submarine
Azkaban is an easy-to-use workflow scheduling service that schedules the workflow of individual notes and individual paragraphs by Azkaban scheduling the Hadoop submarine note written in Zeppelin.
You can use Azkaban’s job file format in Zeppelin. Write multiple notebook execution tasks with execution dependencies.
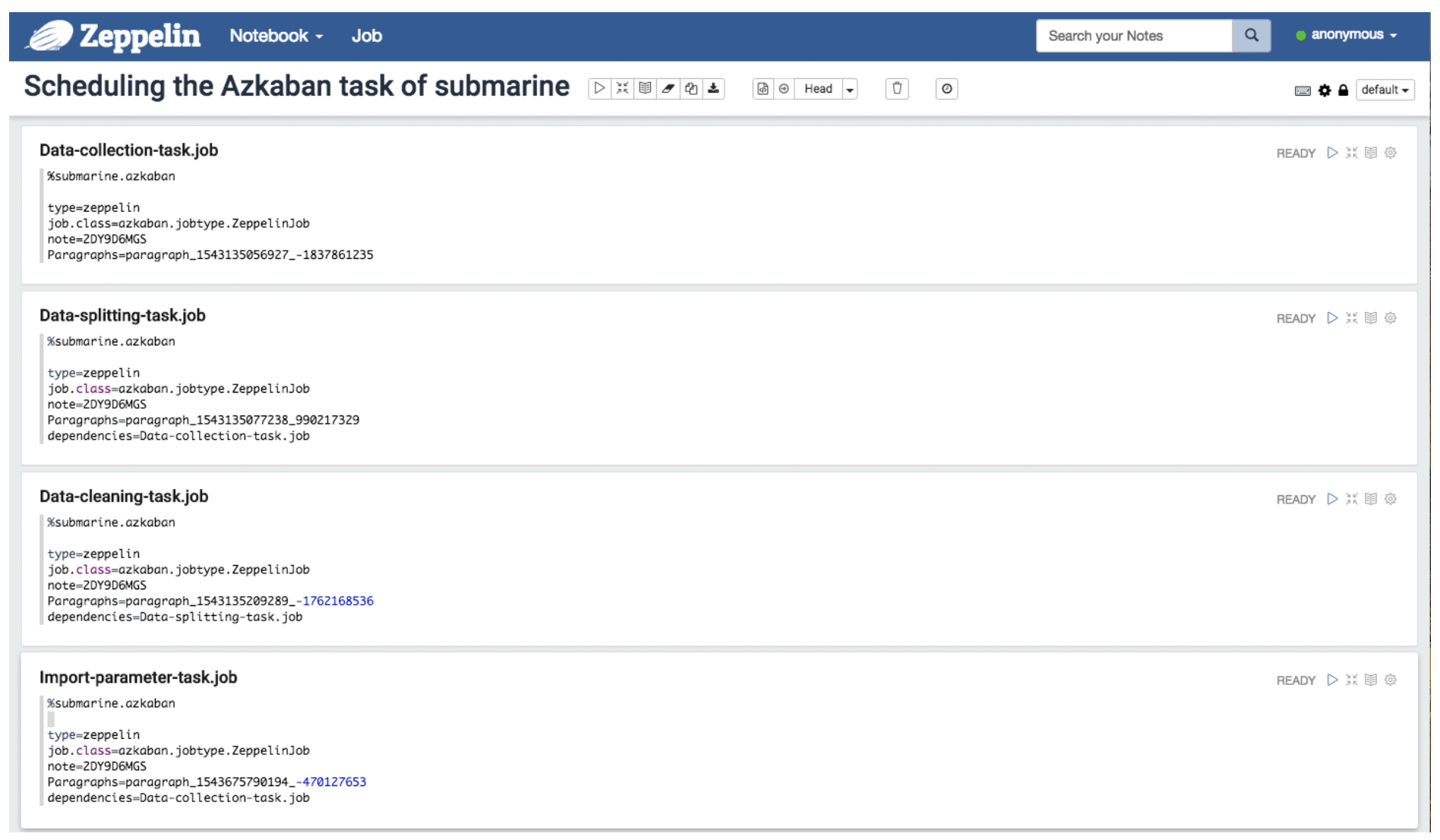
Azkaban can schedule these notebooks in zeppelin as dependencies.
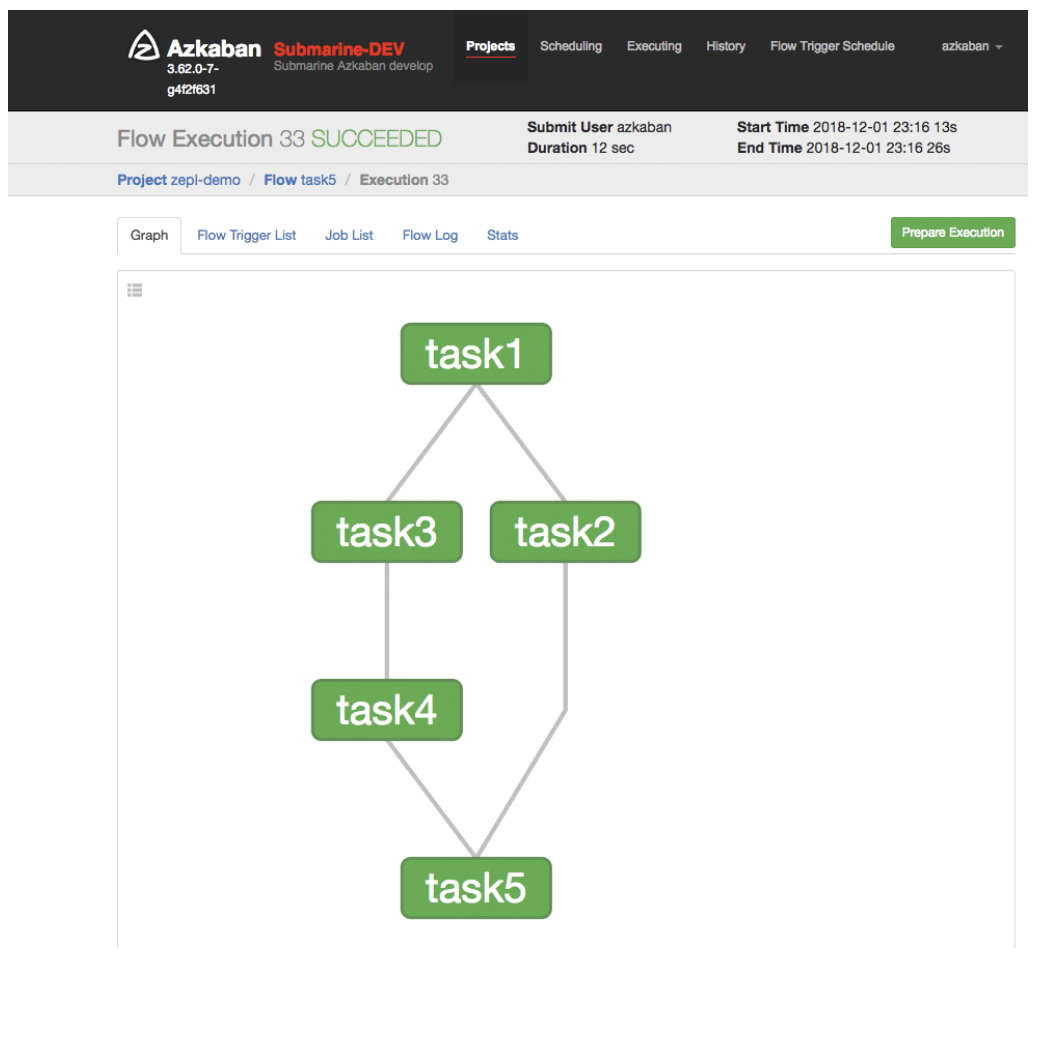
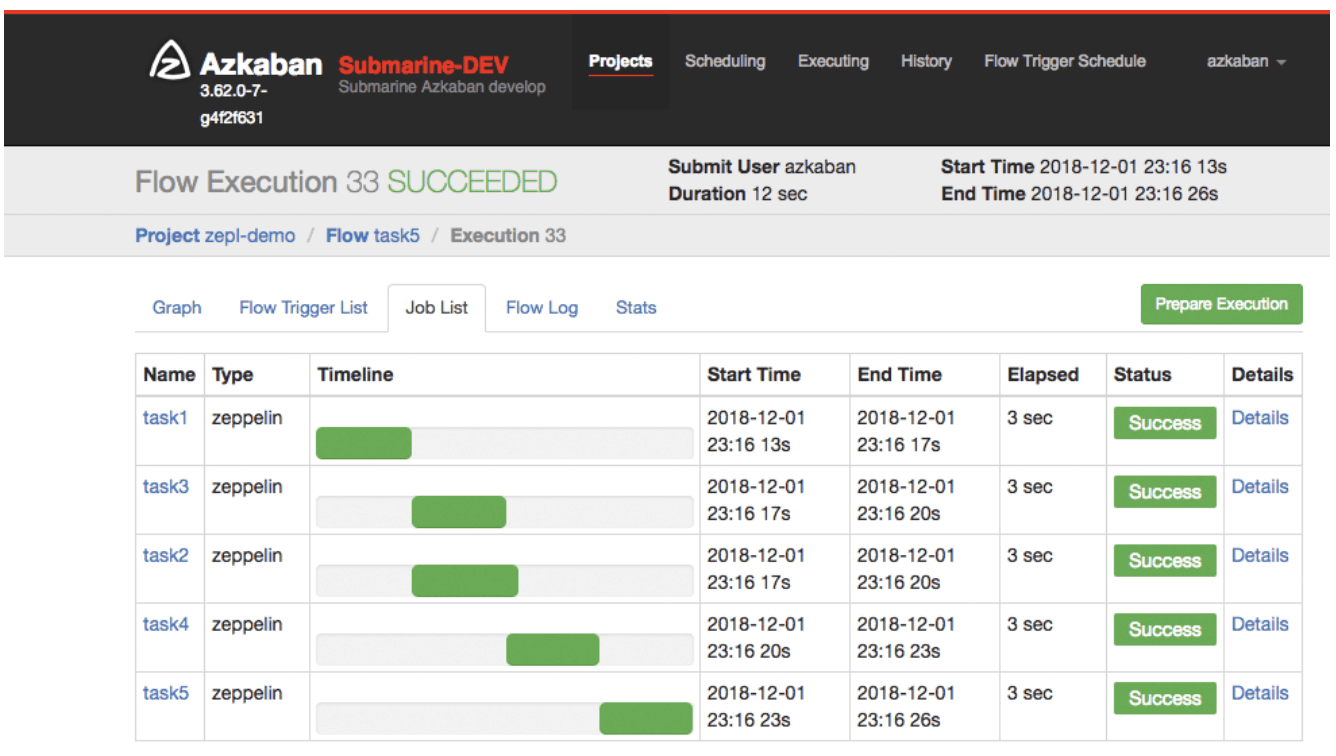
Once notebook with Azkaban script executed, it will be compiled to Azkaban workflow and submit to Azkaban to be executed.
Hadoop submarine installer
Since the distributed deep learning framework needs to run in multiple Docker containers and needs to be able to coordinate the various services running in the container, complete the services of model training and model publishing for distributed machine learning. Involving multiple system engineering problems such as DNS, Docker, GPU, Network, graphics card, operating system kernel modification, etc. It is very difficult and time-consuming to properly deploy the Hadoop {Submarine} runtime environment.
We have provided you with the installation tool submarine installer for the Hadoop submarine runtime environment.
Status
Alpha solution is merged to trunk. (part of 3.2.0 release), still under active dev/testing. Umbrella JIRA: YARN-8135.
Submarine can run on Apache Hadoop 3.1+.x release.
Case Study – Netease
Netease is one of the major contributors of Submarine project.
Status of the existing computation cluster:
- One of the largest online game/news/music provider in China.
- Total ~ 6k nodes YARN cluster.
- 100k jobs per day, 40% are Spark jobs.
A separate 1000 nodes Kubernetes cluster (equipped with GPU) for machine learning workloads.
- 1000 ML jobs per day.
- All data comes from HDFS and processed by Spark, etc.
Existing problems:
- Poor user experience
There is no integrated operating platform, all by manually implementing algorithms, submitting jobs and checking running results. It is inefficient and error-prone.
- Low utilization (YARN tasks cannot leverage this cluster)
Unable to reuse existing YARN cluster resources.
Unable to integrate existing big data processing systems (eg: spark, hive, etc.)
- High maintenance cost (Need to manage the separated cluster)
We also need to operate the Hadoop and Kubernetes 2 operating environments, increasing maintenance costs and learning costs.
Status of submarine deployment inside Netease.
- Actively working with the Submarine community to develop, verifying Submarine on 20 Nodes GPU cluster.
- Plan to move all deep learning workload to Submarine in the future.
See Also
- Submarine design Google doc: , umbrella JIRA for computation engine: YARN-8135
- Submarine ecosystem projects: Github link.
- Submarine slides for Strata Data Conf 2018.
Contributions are welcome!
About authors
Wangda Tan @ Hortonworks, Engineering Manager of YARN team @ Hortonworks. Apache Hadoop PMC member and committer, working on Hadoop since 2011. Major working field: scheduler / deep learning on YARN / GPUs on YARN, etc.
Xun Liu @ Netease, has been working on Hadoop development for 5 years. Currently in the Netease Hangzhou Research Institute is responsible for the machine learning development team.
Sunil Govindan, Staff Software Engineer @Hortonworks. Contributing to Apache Hadoop project since 2013 in various roles as Hadoop Contributor, Hadoop Committer and a member Project Management Committee (PMC). Majorly working on YARN Scheduling improvements / Multiple Resource types support in YARN etc.
Quan Zhou @ Netease, Senior Big Data Engineer @NetEase, Focusing on Hadoop, yarn, and hive, worked at Cisco since 2013 and joined in NetEase in 2015
Zhankun Tang. Staff Software Engineer @Hortonworks. He’s interested in big data, cloud computing, and operating system. Now focus on contributing new features to Hadoop as well as customer engagement. Prior to Hortonworks, he works for Intel.
Acknowledgments
Thanks for inputs and contributions from Vinod Vavilapalli, Saumitra Buragohain, Yanbo Liang, Zian Chen, Weiwei Yang, Zhe Zhang (Linkedin), Jonathan Hung (Linkedin), Keiqiu Hu (Linkedin), Anthony Hsu.
Editor's Choice


Nice post sharing and very informative post we are proud of our legacy of building marine spares for marine service
Thank you for the tutorial. I would like to deploy the distributed deep learning model followed by Hadoop on a toy example. Like I want to use three Personals computers, one would be work as a parameter server and the other two would be work as worker machines. Here I initially configure the Hadoop over the three machines (do not know exactly how it would be done on the three machines). Then I would like to apply the data parallelism model synchronously on the data set. What would be the steps to implement a small distributed deep learning system?