

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
1. Motivation
The HiveWarehouseConnector (HWC) is an open-source library which provides new interoperability capabilities between Hive and Spark. In practice, Hive and Spark are often leveraged together by companies to provide a scalable infrastructure for data warehousing and data analytics. However, as they both continue to expand their capabilities, interoperability between the two becomes difficult. HWC is positioned to maintain interoperability between the two, even as they diverge. HWC is included in HDP as of the 3.0 release.
Hive has matured to become a more traditional data-warehouse with support for ACID semantics and enterprise security integration with Ranger. Neither ACID tables or Ranger secured tables are natively accessible from Spark. On the other hand, Spark has simplified streaming analytics data-flows with the Structured Streaming API.
As an introduction to HWC, this post describes the three main use-cases where HWC can be leveraged:
- Creating DataFrames from the result set of a Hive LLAP query
- Writing out Spark DataFrames to Hive managed tables
- Spark Structured Streaming sink for Hive managed tables
2. Use-Cases
2.1. Creating DataFrames from the result set of a Hive LLAP query
HWC works as a pluggable library to Spark with Scala, Java, and Python support. It exposes a JDBC-style API to Spark developers for executing queries to Hive. Results are returned as a DataFrame for any further processing/analytics inside Spark. Since data is loaded from LLAP daemons to Spark executors in parallel, this is much more efficient and scalable than using a standard JDBC connection from Spark to Hive.
As an example, we use a dataset of FBI crime rate per year (see Appendix for example data). The example below compares the crime rate between 2000 and 2010. The code would be executed in the spark-shell or embedded in an application for use with spark-submit.
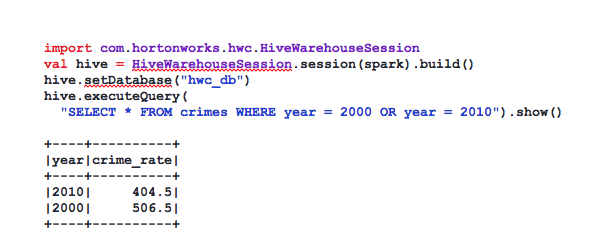
Note that the result of executeQuery is a DataFrame, so we could have formulated the same query, by applying DataFrame operations on top of executeQuery:

Since the result is a DataFrame, we can even register it as a Spark temporary table, to be referenced in standard SparkSQL queries or pass it to Spark libraries such as MLlib.
HWC supports push-downs of DataFrame filter and projection operations applied on top of executeQuery. So for the previous example, the filter operation will be applied as an additional WHERE clause to the SQL executed by LLAP. On the other hand, join and aggregation operations are applied by Spark on the resulting data from executeQuery.
Row/Column level access control for Spark reads from Hive can be controlled through Apache Ranger, since access from HWC is mediated by HiveServer. The following diagram demonstrates the dataflow for a query using HWC from Spark:
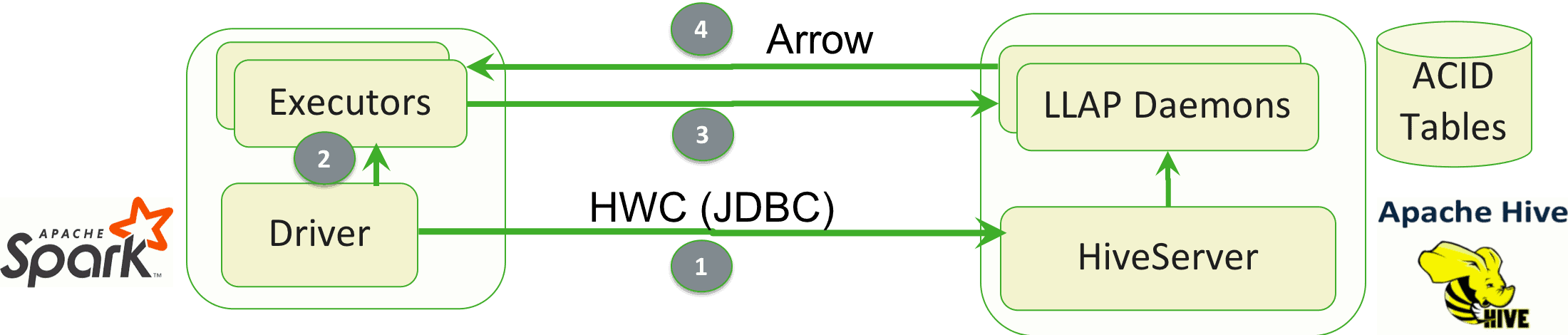
(1) Spark will submit the executeQuery SQL text to HiveServer, to obtain a set of InputSplits for submission to LLAP. The submitted SQL is augmented by any additional filter or projection push-downs. (2) The InputSplits are distributed to Spark executors, one split per-task. (3) Each task submits its split to an LLAP daemon to retrieve the data for that split. (4) Data is exchanged between LLAP and Spark in the Apache Arrow format. Now the result set is available natively for Spark and could be cached, persisted, or further processed.
2.2. Writing out Spark DataFrames to Hive managed tables
As described, Spark doesn’t natively support writing to Hive’s managed ACID tables. Using HWC, we can write out any DataFrame into a Hive table. DataFrames written out by HWC are not restricted as to their origin. Any data which has been exposed to Spark through the DataFrame abstraction can be written.
Here, the dataframe from use case 2.1 is written into a different Hive table after being filtered. We’ll call the new table crimes_2010_2012.

HWC supports the standard SaveMode options provided by Spark: ErrorIfExists, Append, Overwrite, and Ignore.
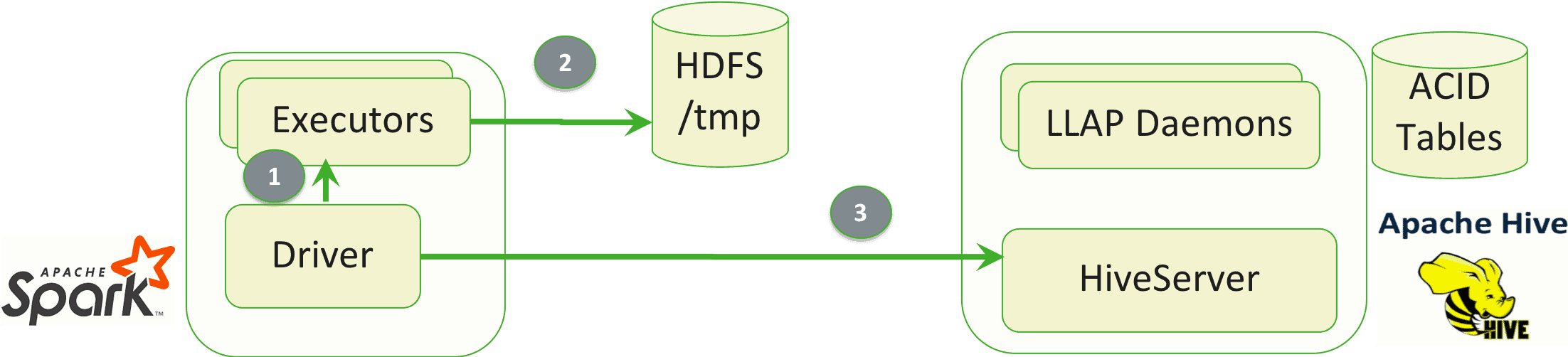
(1) The Driver will instruct Spark executors that a terminal “action” (in this case save()) is being initiated on the DataFrame. This will cause Spark to compute the DataFrame output from its lineage of operations (2) The HWC plugin running in the executors will write the results to storage such as HDFS. (3) HWC will instruct HiveServer to load the data into the target table.
2.3. Structured Streaming Writes
Using distributed stream-based processing with Spark and Kafka is a common way to pump data in a central data-warehouse, such as Hive, for further ETL or BI use-cases. HWC provides a Spark Streaming “Sink” for this purpose. HWC is agnostic as to the Streaming “Source”, although we expect Kafka to be a common source of stream input.
For illustration, a streaming socket source is used here as a simplified example.
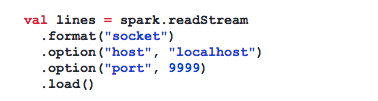
In another terminal, we can use netcat to insert test data:
![]()
and we create a target table to store the stream data (for more information about DDL operations provided by HWC, see Ref [1]):
![]()
Now, the stream data is ready and we can start the structured streaming job.

At the terminal which was opened by netcat we can insert arbitrary data. Since we have applied a Structured Streaming filter, this continuously inserts the word Hortonworks into the table hwx_table.
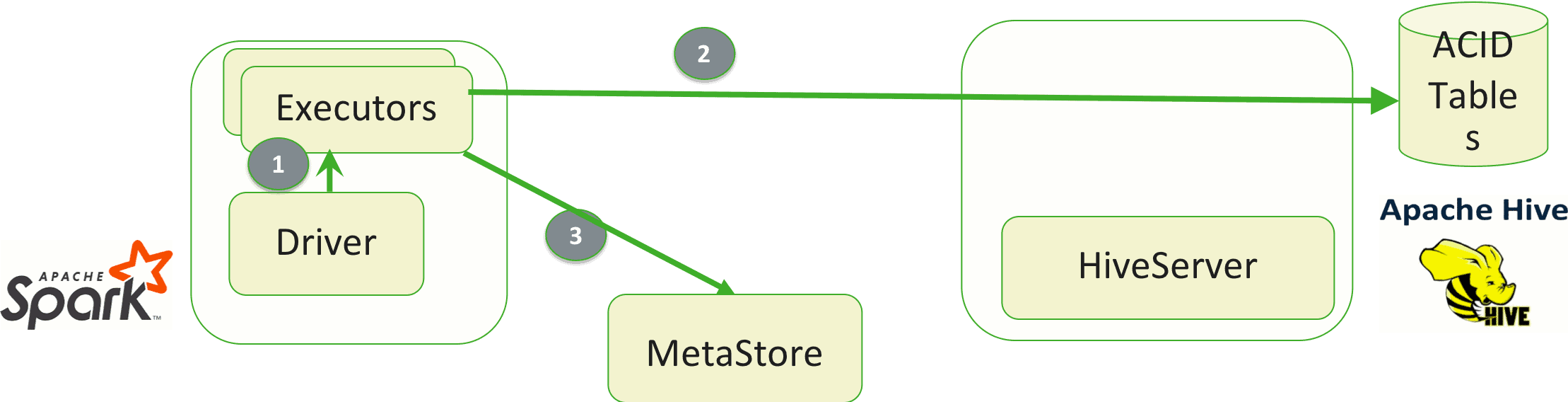
HWC supports Spark Structured Streaming in the traditional micro-batch processing model. For each micro-batch initiated by the Driver (1), data produced by tasks is written to a transactional tablespace (2), which is then committed once the batch completes successfully (3). LLAP is not required for using HWC’s streaming sink since data is written directly to disk from Spark. The HWC sink plugin works to coordinate streaming transactions through begin/commit/abort operations with the Hive Metastore.
3. Additional Resources
- For details on setup and configuration see Ref [1]
- HWC supports usage through Zeppelin and Livy, see Ref [1] and [2] for more information
- Spark and Hive support different sets of data types, see Ref [1] for details on data type conversion
- For a more extensive walkthrough of examples with setup details, check out Ref [2]
- This blog focused on the DML operation support in HWC. See Ref [1] for additional APIs and options for DDL metadata creation and introspection.
4. References
[3] Source code: https://github.com/hortonworks-spark/spark-llap
Appendix
SQL INSERT queries to insert for examples in sections 2.1 and 2.2 (data)

Editor's Choice

