


Machine learning (ML) has become one of the most critical capabilities for modern businesses to grow and stay competitive today. From automating internal processes to optimizing the design, creation and marketing processes behind virtually every product consumed, ML models have permeated almost every aspect of our work and personal lives — and for businesses, the stakes have never been higher. Failing to adopt ML as a core competency will result in major competitive disadvantages that will define the next market leaders.
Because of this, business and technology leaders need to implement ML models across their entire organization, spanning a large spectrum of use cases. However, this sense of urgency, combined with growing regulatory scrutiny, creates new and unique governance challenges that are currently difficult to manage. For example: How are my models impacting services provided to end customers? Am I still compliant with both governmental and internal regulations? How will my security rules translate to models in production?
Beyond regulatory or legal concerns, there are a number of reasons to have governance processes and procedures for Machine Learning. Examples include ways of increasing productivity (such as reusing assets like models and features), controlling and maintaining models across many different business lines to ensure business-critical applications are doing what they’re intended to do (or finding those that aren’t), and seeing a history of models and predictions including deprecated assets.
In tackling these challenges, it is worth defining what models and features are conceptually (see Figure 1). Many different definitions exist, but generally, a model is any self-contained package that takes features computed from input data and produces a prediction (or score) and metadata. This package can take many forms but always includes a mathematical representation, code, business logic and training data. The model’s predictions are consumed downstream by systems or users.
Many enterprises operate ML model infrastructure at different sizes and maturity that they require tools to help them govern their models. Ultimately, needs for ML governance can be distilled into the following key areas: visibility; and model explainability, interpretability, and reproducibility.
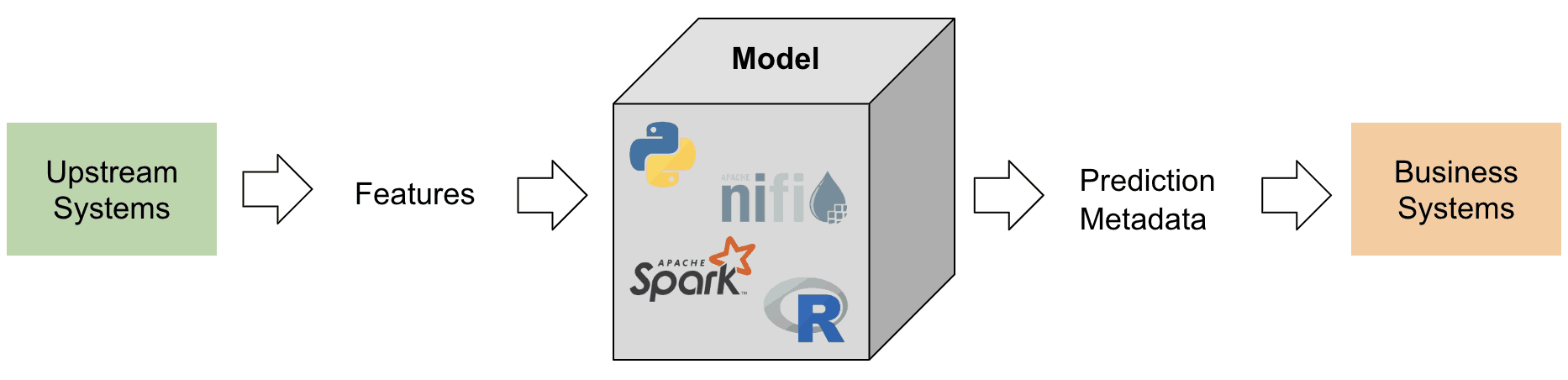
Figure 1
Visibility of models & features within teams and across organizations
A basic requirement for model governance is enabling teams to understand how machine learning is being applied in their organizations. This requires a canonical catalog of models and features. In the absence of such a catalog, many organizations are unaware of their models and features, where they are deployed, what they are doing, etc. This leads to rework, model inconsistency, recomputing features, and other inefficiencies.
Model explainability, interpretability, and reproducibility
Models are often seen as a black box: data goes in, something happens, and a prediction comes out. This non-transparency is challenging on a number of levels and is often represented in loosely related terms such as:
- Explainability: description of the internal mechanics of an ML model in human terms
- Interpretability: the ability to a) understand the relationship between model inputs, features and outputs, and b) to predict the response to changes in inputs.
- Reproducibility: the ability to reproduce the output of a model in a consistent fashion for the same inputs.
All these require common functionality including a tie into source data, a clear understanding of the models’ internals like code and training data, and other methods to probe and analyze models themselves.
Model Metadata with an example
To address the governance problems defined above, let us start by thinking about an example. Consider a food delivery website. The company wants to leverage machine learning to estimate time for delivery.
The training data set consists of the event logs from previous deliveries, which contain the delivery times for each delivery made in the past. This data is used to train a model to estimate future delivery times.
An event log could look something like this:
An order was placed at 10AM for food to be picked up from loc1 and delivered to loc2. The courier picked it up from the restaurant at 10:15AM and delivered it at 10:55AM, taking a total of 55 mins from placing order to delivery

Assume loc1 and loc2 are street addresses. This is abbreviated here to keep it short and easy to read.
The event logs are stored in HBase. The engineering architecture for the model development is as follows:
- Data engineers identify the time window of event logs to be used to solve the problem. A new structured Hive table is created by parsing the raw event logs with the identified time window.
- Feature engineers (this could be a role within data scientists, or ML engineers) identify and develops new features:
- Rush Hour Feature: A function to identify if rush hour conditions exist given a location and a time.
- Restaurant “Busy”ness Feature: A function to identify if a given restaurant is experiencing high wait times based on historical data. This historical data is gathered separately.
- The above identified features are then built as a python library for reuse.
- This library is used to apply the function to the structured Hive table to create a new table which will be the final Training Data Set. A row in the new table looks like this:

Assume loc1 and loc2 are street addresses. This is abbreviated here to keep it short and easy to read.
- Data Scientists run a linear regression on the Training Data Set set to predict the time for delivery. At this point, they have to use the same feature library which was used to extract the features in the training data set.
- The model is deployed as a Function-as-a-Service (FaaS) endpoint used by the web application to predict time for delivery.
Note that the model needs to compute the features for prediction in real-time. These features are libraries that are used internally by the model. A visualization of the various activities performed and artifacts generated in this example might look like this:
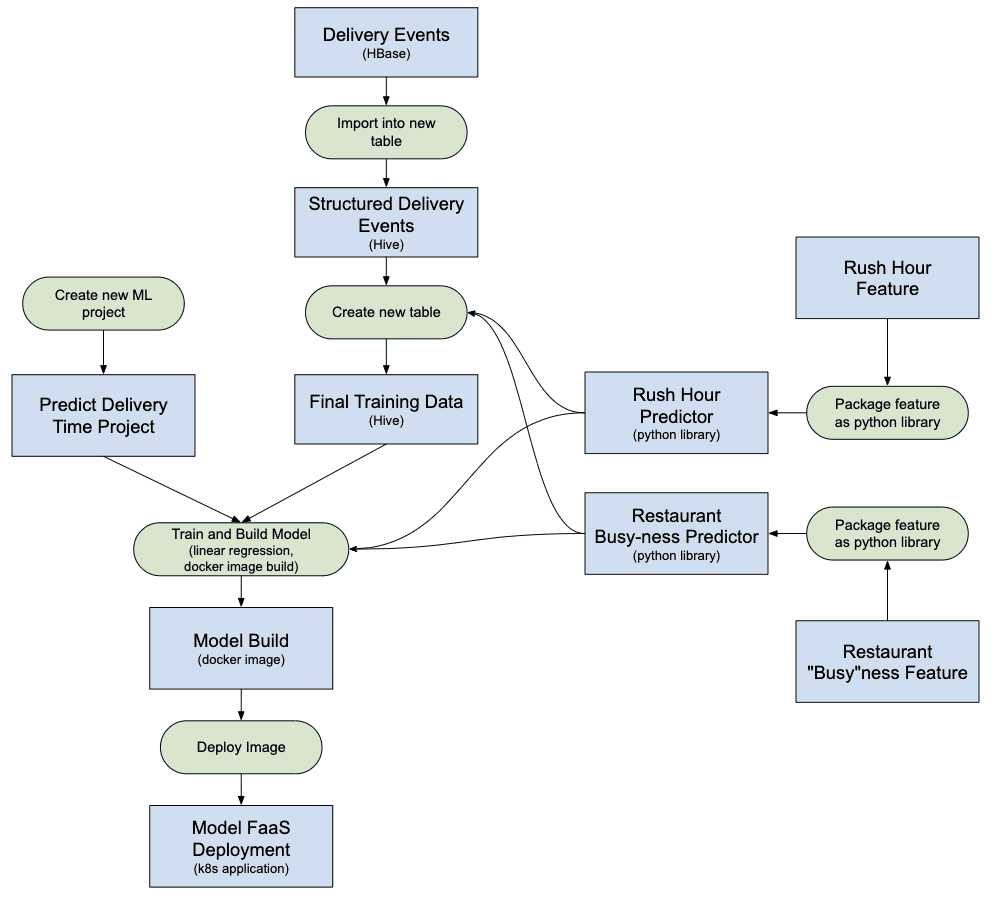
The blue boxes represent ML entities (nouns) such as a code, project, builds, deployments, etc. The green boxes represent processes (verbs) which act upon entities and produce other entities.
The visualization and relationships which define the transformations on the structure of data is collectively termed as lineage. In the database world, adding a new column to a table will modify its lineage. In the machine learning world, retraining a model by consuming features and data sets will modify the lineage. For the food delivery website, to answer the question: “is there a difference between the feature extraction during training vs. scoring”, we need the lineage information. This is just one example of the usefulness of lineage metadata in the machine learning world.
Apache Atlas as a governance tool
It is evident that building a complete end-to-end lineage for ML workflows—from training data sets to model deployments—becomes a key requirement to address the governance problems identified. The integration of data management and machine learning must enable explainability, interpretability, and reproducibility.
Collection, storage, and visualization of ML metadata needs a standard backend software system. An open and extensible metadata definition will enable standardization of governance operations regardless of where the models are developed or served. The obvious candidate for Cloudera (and our customers) is Apache Atlas.
Apache Atlas is already a set of widely-used governance tools with pre-defined metadata types for data management. In the context of ML governance, it is well suited for defining and capturing the metadata required for machine learning concepts. Additionally, Apache Atlas provides advanced capabilities such as classifications, integration with Apache Ranger (for authorization and tagging) to name a few, and has an extensible addons system which allows the community to collaborate around and incrementally define integrations to various other tools in the ML space. It is left as an exercise for the reader to explore Apache Atlas’ UI and see how to use these capabilities.
ML Metadata Definition in Apache Atlas
The Apache Atlas Type System fits all of our needs for defining ML Metadata objects. It is open-source, extensible, and has pre-built governance features. A Type in Atlas is a definition of how a particular type of metadata object is stored and accessed. It also represents one or more attributes that define the properties for the metadata object. For ML governance, Atlas Type System can be used to define new Types, capturing ML entities and processes as Atlas metadata objects. In addition to the definition of the Types, the relationship between the entities and processes is also required to visualize the end-to-end lineage flow.
If we relate this to the food-delivery website example described earlier, the Atlas Type System provides a good foundation to define the Machine Learning lineage. A generalized ML lineage system is visualized as follows:
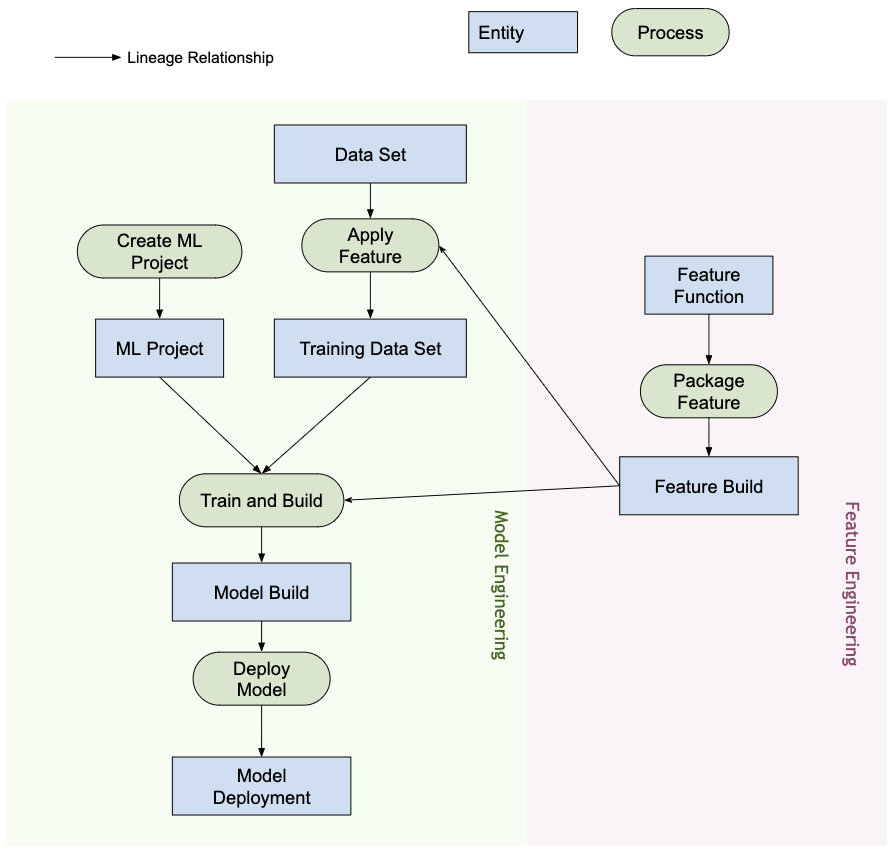
As evident from the diagram above, the Metadata Definition for machine learning closely follows the actual machine learning workflow. Training data sets are the starting point for a model lineage flow. These data sets can be tables from a data warehouse or an embedded csv file. Once a data set has been identified, the lineage follows into training, building and deploying the model.
ML feature development is a parallel and specialized activity which can be termed as feature engineering (different from model engineering). Today, in many cases, the two activities (model engineering and feature engineering) are performed by the same person or team. With the democratization and industrialization of features, this could change in the future, with specialized teams for model development and feature development.
The ML type system can now be defined through the following new types:
“Create Machine Learning Project” and “Machine Learning Project”
A single Machine Learning Project represents a single business use case. The Machine Learning Project represents the container of files and other embedded assets. At the minimum, the project metadata contains:
- List of files used in the model
- Historical version of all files
- The simplest implementation would be to maintain the project as a git repository relying on Git to maintain history of all files.
“Training Data Set”
A subtype of a DataSet in Atlas which represents a training data set. The Training Data Set entity is used in the model training process. It can be associated with a feature if the data generated is the result of applying feature extraction (or transformation) to another data set.
“Train and Build”
A process that represents the action of training and building a model. Includes running experiments, tuning, and finalizing the choice of a training algorithm. Train and Build Process could optionally be consuming the output of a Feature Build; for example, a library function defining feature extraction used internally by the model.
“Model Build”
The model is hardened and versioned once a data scientist has completed experimenting and training the model. This processing results in a Model Build, which is an immutable artifact that forms the building block for productionizing models. A Docker image is an example of a Model Build entity.
“Deploy Model” and “Model Deployment”
A Model Build goes through a deploy process, which creates a Model Deployment. The Model Deployment represents an active instantiation of a model. A Kubernetes based REST service (FaaS-style deployment) is an example of a Model Deployment entity.
“Feature Function”
A machine learning feature has two interpretations: 1) Feature Function and 2) Transformed Data Set.
The Feature Function entity is a custom function (expressed in code) that defines how to extract an identified feature from an input. This represents the code for features, similar to how ML Project represents the container for ML code.
The Feature Function is first packaged as a library (versioned and hardened). The library is then consumed and applied on a given DataSet to transform it into a new DataSet (with the features extracted). The Transformed Data Set is represented by the Training Data Set entity defined above.
“Package Feature” and “Feature Build”
The code in the Feature Function is packaged for sharing (with other models) or for runtime scoring. These packages are called Feature Builds. For example, a Feature Build may contain a packaged library (in python) or a jar file (in Java). This package can be absorbed during the model train and build process to ensure that the same feature is used during extraction as well as prediction.
Try out and get involved in defining the future of ML Metadata Definition
We have started work on ATLAS-3432 which is the first implementation of the Machine Learning Type System leveraging Cloudera Data Science Workbench (CDSW) as the pilot client. Thanks to Na Li from the Cloudera engineering team for leading the work on building the CDSW integration. ATLAS-3432 will allow the model metadata from a CDSW instance to be pushed to an Apache Atlas instance to explore lineage. CDSW currently does not support features (or a feature store), and so the lineage related to features will be unavailable.
At Cloudera, we don’t want to simply solve this problem for our customers – we believe that ML metadata definitions should be universal similar to how tables, columns, etc. are very standard for data structures. We hope that communities will contribute to defining this standard to help companies get the most of their ML platforms.
Do you have a machine learning governance use-case which does not fit into the metadata model? Join the conversation by posting your suggestions to dev@atlas.apache.org.
Editor's Choice

