


Riding the wave of the generative AI revolution, third party large language model (LLM) services like ChatGPT and Bard have swiftly emerged as the talk of the town, converting AI skeptics to evangelists and transforming the way we interact with technology. For proof of this megatrend look no further than the instant success of ChatGPT, where it set the record for the fastest-growing user base, reaching 100 million users in just 2 months after its launch. LLMs have the potential to transform almost any industry and we’re only at the dawn of this new generative AI era.
There are many benefits to these new services, but they certainly are not a one-size-fits-all solution, and this is most true for commercial enterprises looking to adopt generative AI for their own unique use cases powered by their data. For all the good that generative AI services can bring to your company, they don’t do so without their own set of risks and downsides.
In this blog, we will delve into these pressing issues, and also provide you with enterprise-ready alternatives. By shedding light on these concerns, we aim to foster a deeper understanding of the limitations and challenges that come with using such AI models in the enterprise, and explore ways to address these problems in order to create more responsible and reliable AI-powered solutions.
Challenges to enterprise adoption of generative AI
Data Privacy
Data privacy is a critical concern for every company as individuals and organizations alike grapple with the challenges of safeguarding personal, customer, and company data amid the rapidly evolving digital technologies and innovations that are fueled by that data.
Generative AI SaaS applications like ChatGPT are a perfect example of the types of technological advances that expose individuals and organizations to privacy risks and keep infosec teams up at night. Third-party applications may store and process sensitive company information, which could be exposed in the event of a data breach or unauthorized access. Samsung may have an opinion on this after their experience.
Contextual limitations of LLMs
One of the significant challenges faced by LLM models is their lack of contextual understanding of specific enterprise questions. LLMs like GPT-4 and BERT are trained on vast amounts of publicly available text from the internet, encompassing a wide range of topics and domains. However, these models have no access to enterprise knowledge bases or proprietary data sources. Consequently, when queried with enterprise-specific questions, LLMs may exhibit two common responses: hallucinations or factual but out-of-context answers.
Hallucinations describe a tendency of LLMs to resort to generating fictional information that seems realistic. The difficulty with discerning LLM hallucinations is they are an effective mix of fact and fiction. A recent example is fictional legal citations suggested by ChatGPT, and subsequently being used by the lawyers in the actual court case. Applied in enterprise context, as an employee if we were to ask about company travel and relocation policies, a generic LLM will hallucinate reasonable sounding policies, which will not match what the company publishes.
Factual but out-of-context answers result when an LLM is unsure about the specific answer to a domain-specific query, and the LLM will provide a generic but true response that is not tailored to the context. An example would be asking about the price of CDW (Cloudera Data Warehouse), as the language model doesn’t have access to the enterprise price list and standard discount rates the answer will probably provide the typical rates for a collision damage waiver (also abbreviated as CDW), the answer will be factual but out of context.
How can enterprises address these challenges?
Enterprise hosted LLMs Ensure Data Privacy
One option to ensure data privacy is to use enterprise developed and hosted LLMs in the applications. While training an LLM from scratch may seem attractive, it is prohibitively expensive. Sam Altman, Open AI’s CEO, estimates the cost to train GPT-4 to be over $100 million.
The good news is that the open source community remains undefeated. Every day new LLMs developed by various research teams and organizations are released on HuggingFace, built upon cutting-edge techniques and architectures, leveraging the collective expertise of the wider AI community. HuggingFace also makes access to these pre-trained open source models trivial, so your company can start their LLM journey from a more beneficial starting point. And new and powerful open alternatives continue being contributed at a rapid pace (MPT-7B from MosaicML, Vicuna)
Open source models enable enterprises to host their AI solutions in-house within their enterprise without spending a fortune on research, infrastructure, and development. This also means that the interactions with this model are kept in house, thus eliminating the privacy concerns associated with SaaS LLM solutions like ChatGPT and Bard.
Adding Enterprise Context to LLMs
Contextual Limitation is not unique to enterprises. SaaS LLM services like OpenAI have paid offerings to integrate your data into their service, but this has very obvious privacy implications. The AI community has also recognized this gap and have already delivered a variety of solutions, so you can add context to enterprise hosted LLMs without exposing your data.
By leveraging open source technologies such as Ray or LangChain, developers can fine-tune language models with enterprise-specific data, thereby improving response quality through the development of task-specific understanding and adherence to desired tones. This empowers the model to understand customer queries, provide better responses, and adeptly handle the nuances of customer-specific language. Fine tuning is effective at adding enterprise context to LLMs.
Another powerful solution to contextual limitations is the use of architectures like Retrieval-Augmented Generation (RAG). This approach combines generative capabilities with the ability to retrieve information from your knowledge base using vector databases like Milvus populated with your documents. By integrating a knowledge database, LLMs can access specific information during the generation process. This integration allows the model to generate responses that are not only language-based but also grounded in the context of your own knowledge base.
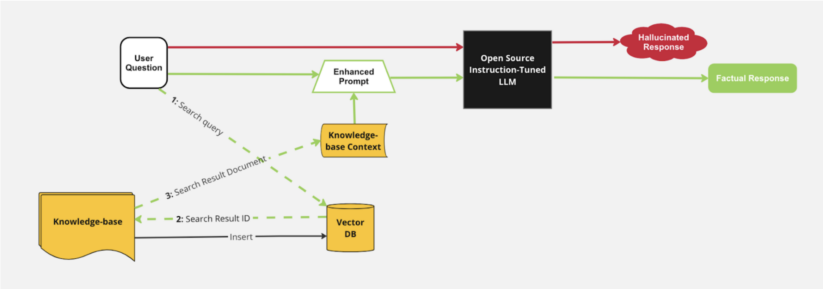
RAG Architecture Diagram for knowledge context injection into LLM Prompts
With these open source superpowers, enterprises are enabled to create and host subject matter expert LLMs, that are tuned to excel at specific use cases rather than generalized to be pretty good at everything.
Cloudera – Enabling Generative AI for the Enterprise
If taking on this new frontier of Generative AI feels daunting, don’t worry, Cloudera is here to help guide you on this journey. We have several unique advantages that position us as the perfect partner to extract maximum value from LLMs with your own proprietary or regulated data, without the risk of exposing it.
Cloudera is the only company that offers an open data lakehouse in both public and private clouds. We provide a suite of purpose built data services enabling development across the data lifecycle, from the edge to AI. Whether that’s real-time data streaming, storing and analyzing data in open lakehouses, or deploying and monitoring machine learning models, the Cloudera Data Platform (CDP) has you covered.
Cloudera Machine Learning (CML) is one of these data services provided in CDP. With CML, businesses can build their own AI application powered by an open source LLM of their choice, with their data, all hosted internally in the enterprise, empowering all their developers and lines of business – not just data scientists and ML teams – and truly democratizing AI.
It’s Time to Get Started
At the start of this blog, we described Generative AI as a wave, but to be honest it’s more like a tsunami. To stay relevant companies need to start experimenting with the technology today so that they can prepare to productionize in the very near future. To this end, we are happy to announce the release of a new Applied ML Prototype (AMP) to accelerate your AI and LLM experimentation. LLM Chatbot Augmented with Enterprise Data is the first of a series of AMPs that will demonstrate how to make use of open source libraries and technologies to enable Generative AI for the enterprise.
This AMP is a demonstration of the RAG solution discussed in this blog. The code is 100% open source, so anyone can make use of it, and all Cloudera customers can deploy with a single click in their CML workspace.
Editor's Choice

