

Introduction
In this blog, we’re going to look at transfer learning, a technique that enables the transfer of knowledge from one task to another. The traditional machine learning approach is to start with zero knowledge, and the model learns the structure and parameters of the model with the training examples provided: this type of learning is called “learning from scratch.” Rather than developing an entirely customized solution to your problem, transfer learning allows you to transfer knowledge from related problems to help solve your custom problem more easily. Consider an example where you join a sports team and learn how to play from your coach, gaining expert advice and knowledge from your coach’s experience that helps you in facing situations in the future. In a similar manner, a deep neural network that is already trained on a huge dataset, and has knowledge about it in the form of weights, enables you to use this knowledge to solve your problems by making only certain changes as needed, rather than having to build your model from scratch.
How transfer learning helps
Less training data: Using transfer learning, you can reuse the model–which is already trained on millions of data inputs–on your specific use case, which means you don’t need as much data to train the model for the new task. For example, you can reuse a dog-detection model for your own dog-related task. This helps you train the model in situations where you have a lot less data available–as well as helping you to run models faster, and on cheaper hardware.
Faster training process: As discussed in the previous point, the training time for transfer learning is less, compared to training from scratch: transfer learning reduces the number of trainable parameters.
Model generalizes better: Transfer learning allows the model to perform better on new, unseen data, because state-of-the-art pretrained models are trained to learn generic features, thus allowing them to avoid overfitting.
How to use pretrained models
- You can understand the exact architecture followed in pretrained models and can build your own model that can work better in your use case.
- You can use pretrained models as a feature extractor, where you simply modify the output layer according to your dataset.
- You can freeze some of the layers in the pretrained model, then make other layers trainable on your dataset. (This may lead to updating of weights and consume more time.)
Consider the popular image classification model Resnet-50. The architecture was chosen as the result of years of research and experimentation from various deep learning experts. Within this complicated structure there are 25 million weights, and optimizing these weights from scratch can be nearly impossible without extensive knowledge of each of the model’s components. With transfer learning, you can reuse both the complicated structure and the optimized weights, significantly lowering the barrier to entry for deep learning. Fig1 shows how to load the ResNet50 model and add your layers on top of it for your specific use case. The last layer has 10 output classes to predict using CIFAR10 dataset. For complete implementation of this use case, check out the Building a Convolutional Neural Network Model.

Model interpretability
It is often said that a deep neural network is a black box, and it is very difficult to understand how the model makes predictions. Interpretability of models is very important to trusting the model, and therefore it is very important to understand how the model predicts. In order to build trust in intelligent systems and move toward their meaningful integration into our everyday lives, it is clear that we have to build transparent models that explain why they predict what they do. There are many techniques that have been developed to understand the representation and interpretation of visual concepts. This blog covers a few of the most important techniques.
Visualizing the intermediate convolution layer outputs: Visualizing the intermediate outputs of convolution layers helps us understand how the input is transformed by the layers and how different filters are learned by the network. The output of a given input is taken care of by the activation layer, which is the activation function output. Initial convolution layers try to detect the edges of the image, and deeper layers learn the complex patterns in the image.

Using gradient-based visualization methods
Saliency maps: The idea behind saliency is to compute the gradient of the output category with respect to the input image. This should tell us how the output value changes with respect to a small change in input. We can use these gradients to highlight input regions that cause the most change in the output. Intuitively, this should highlight the salient image regions that contribute most to the output.
Grad-CAM: Gradient-weighted Class Activation Mapping (Grad-CAM) uses the class-specific gradient information flowing into the final convolutional layer of a CNN to produce a coarse localization map of the important regions in the image.
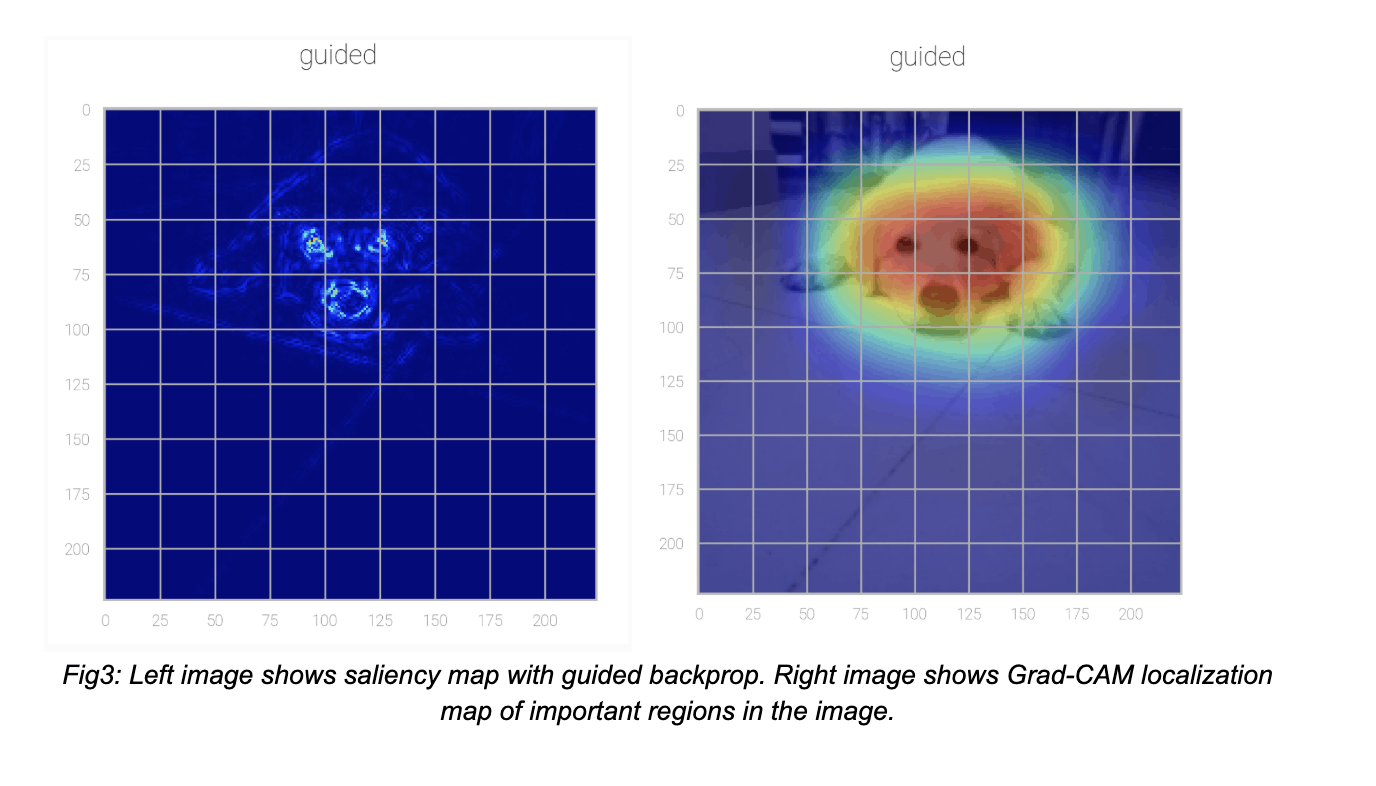
Conclusion
Congratulations! You have learned the concepts of transfer learning and model interpretability. Excited to build the CNN model using Transfer Learning and Model Interpretability? Learn how to build CNN model using transfer learning and model interpretability by completing the tutorial Building a Convolutional Neural Network Model.
Editor's Choice

