

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Guest Author: Greg Kincade, MBA, is an electrical engineer and Sr. Ecosystem Enablement Program Manager for the Micron Storage Solutions Center.
We used to build data lakes. Now we fill data oceans.
As my fellow users of Hortonworks® Data Platform, powered by Apache Hadoop®, users know, those of us working with Big Data are tasked with deriving real-time analytics to drive business solutions, concrete actions and valuable content from these data oceans to keep our organizations competitive. That’s if we can get to the data fast enough.

The Micron® Technology perspective is as both a user of HDP® and an IT infrastructure solution provider for Big Data applications like Hadoop. New containerization, support for deep learning workloads and a real-time database should lead to faster business insights for the Micron data architects and strategists. Key innovations in Apache Hadoop 3.1-based distribution will further help Micron IT increase efficiencies in our manufacturing processes for higher yield and quality on Micron memory and storage products. I look forward to how the real-time database query optimizations, with best-of-breed Micron NVMe™ solid state drives (SSDs), will accelerate the time-to-insights so critical for decision making for our common customers.
The benchmark test journey for Hadoop at Micron’s customer quality lab in Austin, Texas, started with v2.6 of HDP Hive™ in 2017. We found adding even one Micron SSD to a node could speed up queries for real-time analytics. This year, Micron and Hortonworks are testing the Apache Hadoop 3.1-based distribution, and we see some intriguing results. We will be sharing them live Wednesday afternoon, 20 June, at the DataWorks Summit 2018: How to use flash drives with Apache Hadoop 3.x: Real world use cases and proof points—better results, better economics. In this session, my colleague Mike Cunliffe, senior data architect at Micron, will also share Micron IT’s implementation of real-world Hive manufacturing analytics to be rolled out across our 13 global fab sites.
Flash Fills the Need, the Need for Speed
Hadoop facilitates handling large amounts of data sets to derive value from various data sources, while Micron excels in enabling efficient access to the underlying data. Velocity — accelerating the speed of data creation and decision — depends on the underlying storage and memory. To enhance velocity, latency must be properly addressed in big data initiatives. Latency essentially chokes the server’s ability to process bigger and bigger data sets, bringing workloads to a grinding halt, making sophisticated analytics more time-consuming and reducing their value.

Hard disk drives (HDDs) are no longer sufficient to capture, index, parse, report and act on mountains of unstructured data. Micron is committed to deploying our flash to replace spinning media and enabling the wave of organizations turning to SSDs and flexible DRAM for in-memory processing.
Bigger Data Sets Can Overcome Gaps and Overlaps
Asynchronous data streams caused by issues like bandwidth limitations, transmission latency and distance differences can lead to related data arriving at different, time-staggered intervals. Staggered arrivals can cause interruptions (gaps) and restarts (overlaps). These can interfere with the synchronization required for complete, real-time analysis and cause inconsistent streams and results. You also don’t want to starve your high-value resources (CPUs and memory) of data and cause them to sit idle. And processing before all related streams are complete risks analyzing an incomplete data set, which can create a data gap, imprecise results and less timely insights.
What if you stored and accelerated an entire data set of I/O instead of just small slivers? In our testing, we leveraged the ingest (write) rate of a single Micron 9200 NVMe™ SSD, which ranges from 1.95 GB/s to 2.4 GB/s (random write IOPS from 95,000 to 270,000), with delivery (read) rates ranging from 4.3 GB/s to 6 GB/s (random read IOPS from 620,000 to 800,000, exact numbers are configuration-dependent). We compared query runs in Hive v3.0 using some flash storage to all-HDD storage (15K RPM).
Intriguing Results from Testing Queries on Apache Hadoop 3.1
Hortonworks gave us early access to an Apache Hadoop 3.1-based Hive database on HDFS/YARN solution, which was deployed on two separate 4-node clusters. The clusters were configured as shown in the table below, but the primary configuration difference was the introduction of a single Micron 9200 MAX NVMe SSD to each node as a YARN cache to the HDDs. Our database size-to-memory ratio was targeted at two to one for the cluster with our total database size being 2TB and our aggregate cluster memory of 822GB available after OS overhead.

We then performed each of the 99 queries used within the Transaction Processing Performance Council’s TPC-DS benchmark and measured the time to completion for each query on each cluster configuration. We used the configuration that only used HDDs as the baseline for comparison with the NVMe cached configuration. (Of the 99 benchmark queries, we could complete 94 with enough confidence to publish the results. This may be due to our using an early beta version of the software.) We’ll reveal more of the benchmark results at our DataWorks Summit presentation, but here’s a bar chart showing some intriguing and positive results with NVMe-based flash storage.
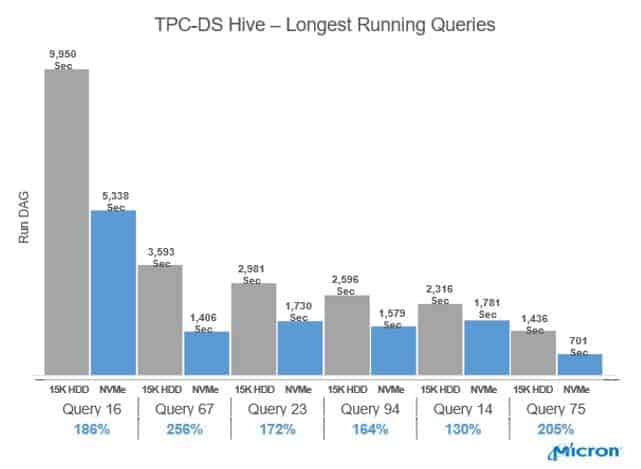
Can the cost efficiency and reliability of high-density 3D NAND storage help overcome disk I/O bottlenecks?
For large, busy clusters, reducing run time has real implications. If our cluster is busy and we can process a data set faster, we free up cluster resources sooner (because we complete processing sooner). This enables the cluster to begin working on the next data set.
Want to see more? Hope to see you in San Jose for the DataWorks Summit! Check out How to use flash drives with Apache Hadoop 3.x: Real world use cases and proof points—better results, better economics.
LEARN MORE ABOUT HADOOP 3:
- First-Class Support for Long Running Services on Apache Hadoop YARN
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Apache Hadoop 3.1.0 released. And a look back!
- Apache Hadoop 3.1 – A Giant Leap for Big Data
- Trying Out Containerized Applications on Apache Hadoop YARN 3.1
- Containerized Apache Spark on YARN in Apache Hadoop 3.1
Editor's Choice

