

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 7th blog of the Hadoop Blog series (part 1, part 2, part 3, part 4, part 5, part 6). In this blog, we will share our experiences running LLAP as a YARN Service. This is specifically a follow up to part 1.
Apache Hive LLAP is a key long running application for query processing, designed to run on a shared multi-tenant Apache Hadoop YARN cluster. We’ll share our experience of migrating LLAP from Apache Slider to the YARN Service framework.
LLAP is a long running application consisting of a set of processes. LLAP takes Apache Hive to the next level by providing asynchronous spindle-aware IO, prefetching and caching of column chunks, and multi-threaded JIT-friendly operator pipelines.
It is important for the Apache Hive/LLAP community to focus on the core functionalities of the application. This means less time spent on dealing with its deployment model and less time to understand YARN internals for creation, security, upgrade, and other aspects of lifecycle management of the application. For this reason, Apache Slider was chosen to do the job. Since its first version, LLAP has been running on Apache Hadoop YARN 2.x using Slider.
With the introduction of first class services support in Apache Hadoop 3, it was important to migrate LLAP seamlessly from Slider to the YARN Service framework – HIVE-18037 covers this work.
Running LLAP as a YARN Service
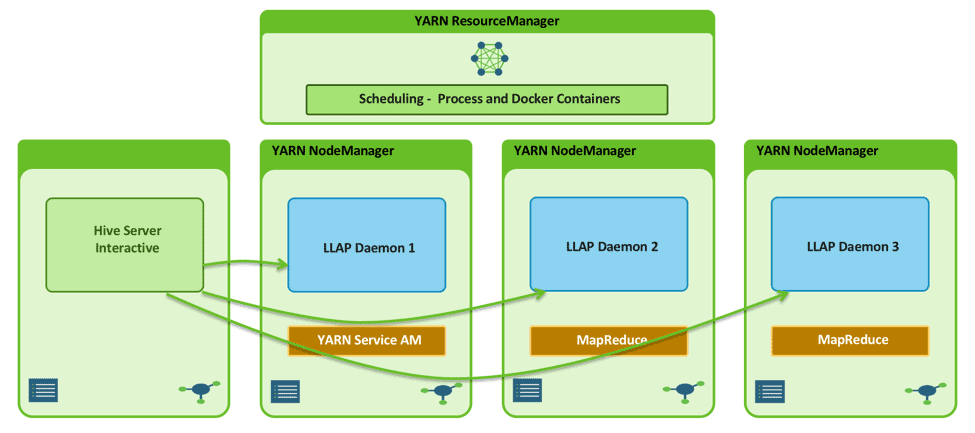
Even though Slider helped the LLAP community to focus on their application, it wasn’t the easiest experience possible. It still involved maintenance of configuration files along with a bunch of wrapper python scripts. There was no support for REST APIs to easily submit and manage application lifecycle. Command-line submission and management made start, stop, and status checks slow. Integration with the Slider Java SDK to make things faster forced dealing with YARN/Slider internals. The primary purpose of choosing a tool like Slider was being defeated!
With the YARN Service framework, all the above pain points and shortcomings are eliminated. Creation and lifecycle management are now handled easily via REST APIs, hence the overhead of starting a JVM for every command line no longer exists. All the python wrapper scripts were eliminated now once Slider’s agent architecture is thrown out in favor of a more powerful YARN NodeManager. The remaining set of configuration files shrunk to a single JSON file called a Yarnfile.
Past: With Apache Slider
This is how LLAP’s Apache Slider wrapper scripts and configuration files directory looked, in a recursive view –
├── app_config.json ├── metainfo.xml ├── package │ └── scripts │ ├── argparse.py │ ├── llap.py │ ├── package.py │ ├── params.py │ └── templates.py └── resources.json
Present: With YARN Service Framework
Now with the YARN Service framework, this is how the recursive directory view looks – clean!
├── Yarnfile
Yarnfile: YARN Service JSON specification for LLAP
Even for a complex application like LLAP, the Yarnfile looks very simple!
The template checked into Apache Hive’s git repository is available here https://github.com/apache/hive/blob/master/llap-server/src/main/resources/templates.py
A slightly simplified version is pasted below for quick perusal.
{
"name": "llap0",
"version": "1.0.0",
"queue": "llap",
"configuration": {
"properties": {
"yarn.service.rolling-log.include-pattern": ".*\\.done"
}
},
"components": [
{
"name": "llap",
"number_of_containers": 10,
"launch_command": "$LLAP_DAEMON_BIN_HOME/llapDaemon.sh start",
"artifact": {
"id": ".yarn/package/LLAP/llap-25Jan2018.tar.gz",
"type": "TARBALL"
},
"resource": {
"cpus": 1,
"memory": "10240"
},
"placement_policy": {
"constraints": [
{
"type": "ANTI_AFFINITY",
"scope": "NODE",
"target_tags": [ "llap" ]
}
]
},
"configuration": {
"env": {
"JAVA_HOME": "/base/tools/jdk1.8.0_112",
"LLAP_DAEMON_BIN_HOME": "$PWD/lib/bin/",
"LLAP_DAEMON_HEAPSIZE": "2457"
}
}
}
],
"quicklinks": {
"LLAP Daemon JMX Endpoint": "http://llap-0.${SERVICE_NAME}.${USER}.${DOMAIN}:15002/jmx"
}
}
Few attributes to focus on:
- “artifact”: Specifies the type of artifact (TARBALL in this case) and its location in HDFS. Other supported types are DOCKER and SERVICE (more details in follow up posts of this blog series). In case of LLAP, the tarball llap-25Jan2018.tar.gz was previously uploaded to .yarn/package/LLAP/ under user hive’s HDFS home directory.
- “env”: Defines a set of environment variables required by the LLAP daemon start script.
- “placement_policy”: Anti-affinity placement policy specifies that there should be no more than one LLAP daemon per node.
Further, Apache Ambari simplified the end-to-end experience of installing Hive/LLAP and subsequent lifecycle management like start, stop, restart, and flex up/down. This same Ambari based experience will continue to work with LLAP as a YARN Service.
Relation to YARN features in Apache Hadoop 3.0/3.1
Making LLAP as a first-class YARN service also enables us to use some of the other powerful features in YARN that were added in Apache Hadoop 3.0 / 3.1, some of them are noted below.
- Advanced container placement scheduling such as affinity and anti-affinity. What Slider used to handle in a custom way is now a core first-class feature (YARN-6592).
- Rich APIs for users to fetch/query application details using Timeline Service V2 (YARN-2928 and YARN-5355).
- New and improved Services UI in YARN UI2 improving debuggability and log access.
- Continuous rolling log aggregation of long running containers (YARN-2443).
- Auto-restart of containers by NodeManagers (YARN-4725).
- Windowing and threshold based container health monitor (YARN-8122).
- In the future, we can also leverage YARN level rolling upgrades for containers and the service as a whole (YARN-7512 and YARN-4726).
Takeaway
Notable features of YARN Service framework support for long running services include the simplicity of the Yarnfile specification for launching applications, support for most existing Slider features, and myriad new features and improvements. These first class capabilities in YARN should pave the way for all existing Slider applications to migrate and new applications to onboard onto Apache Hadoop YARN 3.x, enabling them to take advantage of its rich framework.
We would like to extend our gratitude to the Hive community members Miklos Gergely, Deepesh Khandelwal and Ashutosh Chauhan for their help towards reviewing and testing the changes required for this migration.
What’s next
This blog post provided details on how simple it is to run complex applications such as LLAP on the YARN Service framework. In subsequent blog posts, we will start to deep dive into the internals of the framework like REST APIs, DNS Registry, Docker support and many more. Stay tuned!
LEARN MORE ABOUT HADOOP 3:
- First-Class Support for Long Running Services on Apache Hadoop YARN
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Apache Hadoop 3.1.0 released. And a look back!
- Apache Hadoop 3.1 – A Giant Leap for Big Data
- Trying Out Containerized Applications on Apache Hadoop YARN 3.1
- Containerized Apache Spark on YARN in Apache Hadoop 3.1
Editor's Choice


i am running cloudera 6.3. can i install Hive LLAP