


Apache Ozone is a distributed, scalable, and high-performance object store, available with Cloudera Data Platform (CDP), that can scale to billions of objects of varying sizes. It was designed as a native object store to provide extreme scale, performance, and reliability to handle multiple analytics workloads using either S3 API or the traditional Hadoop API.
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases. There are also newer AI/ML applications that need data storage, optimized for unstructured data using developer friendly paradigms like Python Boto API.
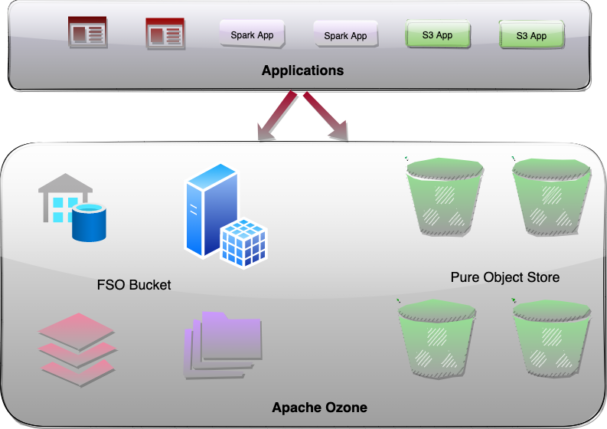
Apache Ozone caters to both these storage use cases across a wide variety of industry verticals, some of which include:
- Manufacturing, where the data they generate can provide new business opportunities like predictive maintenance in addition to improving their operational efficiency
- Retail, where big data is used across all stages of the retail process—from product development, pricing, demand forecasting, and for inventory optimization in the stores.
- Healthcare, where big data is used for improving profitability, conducting genomic research, improving patient experience, and to save lives.
Similar use cases exist across all other verticals like insurance, finance and telecommunications.
In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3). A unified storage architecture that can store both files and objects and provide a flexible, scalable, and high-performance system. Furthermore, data stored in Ozone can be accessed for various use cases via different protocols, eliminating the need for data duplication, which in turn reduces risk and optimizes resource utilization.
Diversity of workloads
Today’s fast growing data-intensive workloads that drive analytics, machine learning, artificial intelligence, and smart systems demand a storage platform that is both flexible and efficient. Apache Ozone natively provides Amazon S3 and Hadoop File System compatible endpoints and is designed to work seamlessly with enterprise scale data warehousing, batch processing, machine learning, and streaming workloads. Ozone supports various workloads, including the following prominent storage use cases, based on the nature through which they are integrated with storage service:
- Ozone as a pure S3 object store semantics
- Ozone as a replacement filesystem for HDFS to solve the scalability issues
- Ozone as a Hadoop Compatible File System (“HCFS”) with limited S3 compatibility. For example, for key paths with “/” in it, intermediate directories will be created
- Interoperability of the same data for several workloads: multi-protocol access
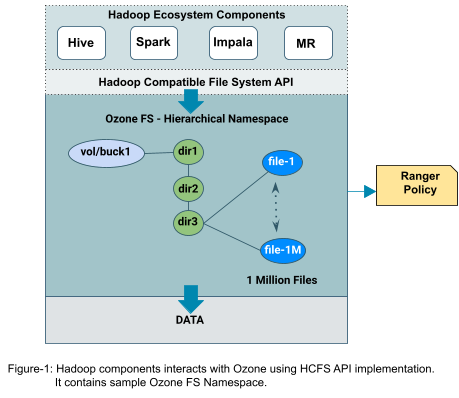
The following are the major aspects of big data workloads, which require HCFS semantics.
- Apache Hive: drop table query, dropping a managed Impala table, recursive directory deletion, and directory move operation are much faster and strongly consistent without any partial results in case of any failure. Please refer to our earlier Cloudera blog for more details about Ozone’s performance benefits and atomicity guarantees.
- These operations are also efficient without requiring O(n) RPC calls to the Namespace Server where “n” is the number of file system objects for the table.
- Job committers of big data analytics tools like Apache Hive, Apache Impala, Apache Spark, and traditional MapReduce often rename their temporary output files to a final output location at the end of the job to become publicly visible. The performance of the job is directly impacted by how quickly the renaming operation is completed.
Bringing files and objects under one roof
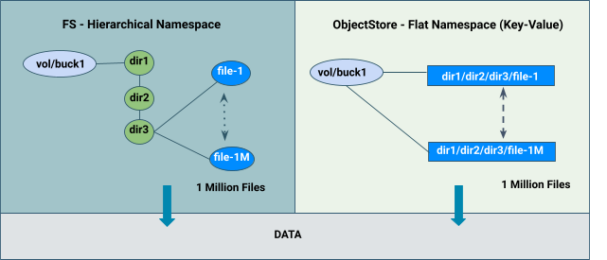
A unified design represents files, directories, and objects stored in a single system. Apache Ozone achieves this significant capability through the use of some novel architectural choices by introducing bucket type in the metadata namespace server. This allows a single Ozone cluster to have the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3) features by storing files, directories, objects, and buckets efficiently. It removes the need to port data from an object store to a file system so analytics applications can read it. The same data can be read as an object, or a file.
Bucket types
Apache Ozone object store recently implemented a multi-protocol aware bucket layout feature in HDDS-5672,available in the CDP-7.1.8 release version. The idea here is to categorize Ozone Buckets based on the storage use cases.
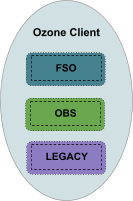
FILE_SYSTEM_OPTIMIZED Bucket (“FSO”)
- Hierarchical FileSystem namespace view with directories and files similar to HDFS.
- Provides high performance namespace metadata operations similar to HDFS.
- Provides capabilities to read/write using S3 API*.
OBJECT_STORE Bucket (“OBS”)
- Provides a flat namespace (key-value) similar to Amazon S3.
LEGACY Bucket
- Represents existing pre-created Ozone bucket for smooth upgrades from previous Ozone version to the new Ozone version.
Creating FSO/OBS/LEGACY buckets using Ozone shell command. Users can specify the bucket type in the layout parameter.
$ozone sh bucket create --layout FILE_SYSTEM_OPTIMIZED /s3v/fso-bucket $ozone sh bucket create --layout OBJECT_STORE /s3v/obs-bucket $ozone sh bucket create --layout LEGACY /s3v/bucket
BucketLayout Feature Demo, describes the ozone shell, ozoneFS and aws cli operations.
Ozone namespace overview
Here is a quick overview of how Ozone manages its metadata namespace and handles client requests from different workloads based on the bucket type. Also, the bucket type concept is architecturally designed in an extensible fashion to support multi-protocols like NFS, CSI, and more in the future.
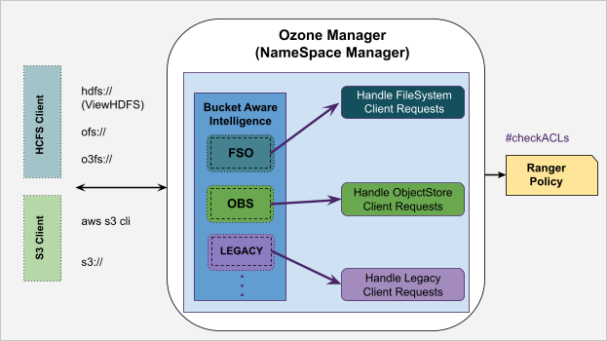
Ranger policies
Ranger policies enable authorization access to Ozone resources (volume, bucket, and key). The Ranger policy model captures details of:
- Resource types, hierarchy, support recursive operations, case sensitivity, support wildcards, and more
- Permissions/actions performed on a specific resource like read, write, delete, and list
- Allow, deny, or exception permissions to users, groups, and roles
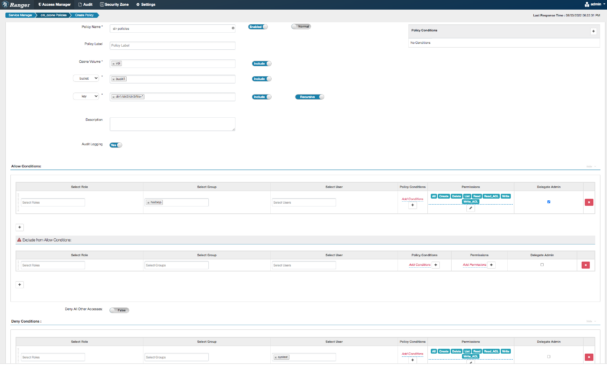
Similar to HDFS, with FSO resources, Ranger supports authorization for rename and recursive directory delete operations as well as provides performance-optimized solutions irrespective of the large set of subpaths (directories/files) contained within it.
Workload migration or replication across clusters:
Hierarchical file system (“FILE_SYSTEM_OPTIMIZED”) capabilities bring an easy migration of workloads from HDFS to Apache Ozone without significant performance changes. Moreover, Apache Ozone seamlessly integrates with Apache data analytics tools like Hive, Spark, and Impala while retaining the Ranger policy and performance characteristics.
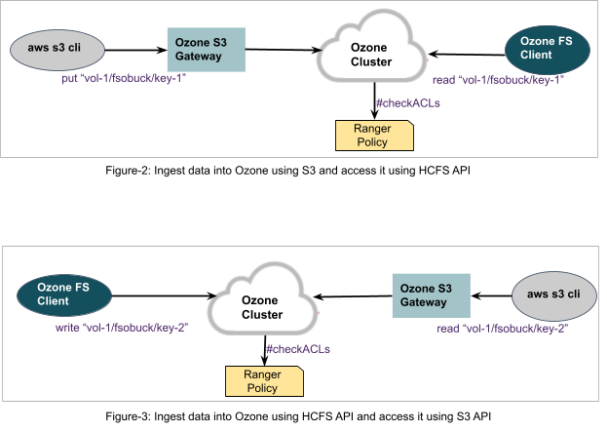
Interoperability of data: multi-protocol client access
Users can store their data into an Apache Ozone cluster and access the same data via different protocols: Ozone S3 API*, Ozone FS, Ozone shell commands, etc.
For example, a user can ingest data into Apache Ozone using Ozone S3 API*, and the same data can be accessed using Apache Hadoop compatible FileSystem interface and vice versa.
Basically, this multi-protocol capability will be attractive to systems that are primarily oriented towards File System like workloads, but would like to add some object store feature support. This can improve the efficiency of the user platform with on-prem object store. Furthermore, data stored in Ozone can be shared for various use cases, eliminating the need for data duplication, which in turn reduces risk and optimizes resource utilization.
Summary
An Apache Ozone cluster provides a single unified architecture on CDP that can store files, directories, and objects efficiently with multi-protocol access. With this capability, users can store their data into a single Ozone cluster and access the same data for various use cases using different protocols (Ozone S3 API*, Ozone FS), eliminating the need for data duplication, which in turn reduces risk and optimizes resource utilization.
In short, combining file and object protocols into one Ozone storage system offers the benefits of efficiency, scale, and high performance. Now, users have more flexibility in how they store data and how they design applications.
S3 API* – refers to Amazon S3 implementation of the S3 API protocol.
Further Reading
Introducing Apache Hadoop Ozone
Apache Hadoop Ozone – Object Store Architecture
Apache Ozone – A High Performance Object Store for CDP Private Cloud
Editor's Choice

