

As organizations wrangle with the explosive growth in data volume they are presented with today, efficiency and scalability of storage become pivotal to operating a successful data platform for driving business insight and value. Apache Ozone is a distributed, scalable, and high performance object store, available with Cloudera Data Platform Private Cloud. CDP Private Cloud uses Ozone to separate storage from compute, which enables it to handle billions of objects on-premises, akin to Public Cloud deployments which benefit from the likes of S3. Ozone is also fully compatible with S3 API*, establishing it as a future proof solution and enabling CDP Hybrid Cloud to meet the growing demand for a hybrid data cloud .
Apache Ozone has added a new feature called File System Optimization (“FSO”) in HDDS-2939. This feature is merged upstream into the master branch and will be available in the next Ozone release. The FSO feature provides file system semantics (hierarchical namespace) efficiently while retaining the inherent scalability of an object store. With FSO, Apache Ozone guarantees atomic directory operations, and renaming or deleting a directory is a simple metadata operation even if the directory has a large set of sub-paths (directories/files) within it. In fact, this gives Apache Ozone a significant performance advantage over other object stores in the data analytics ecosystem. Moreover, Ozone seamlessly integrates with Apache data analytics tools like Hive, Spark and Impala. Also, various use cases like Apache Hive drop table query, recursive directory deletion, directory moving operations are now much faster and are strongly consistent without any partial results in case of any failure.
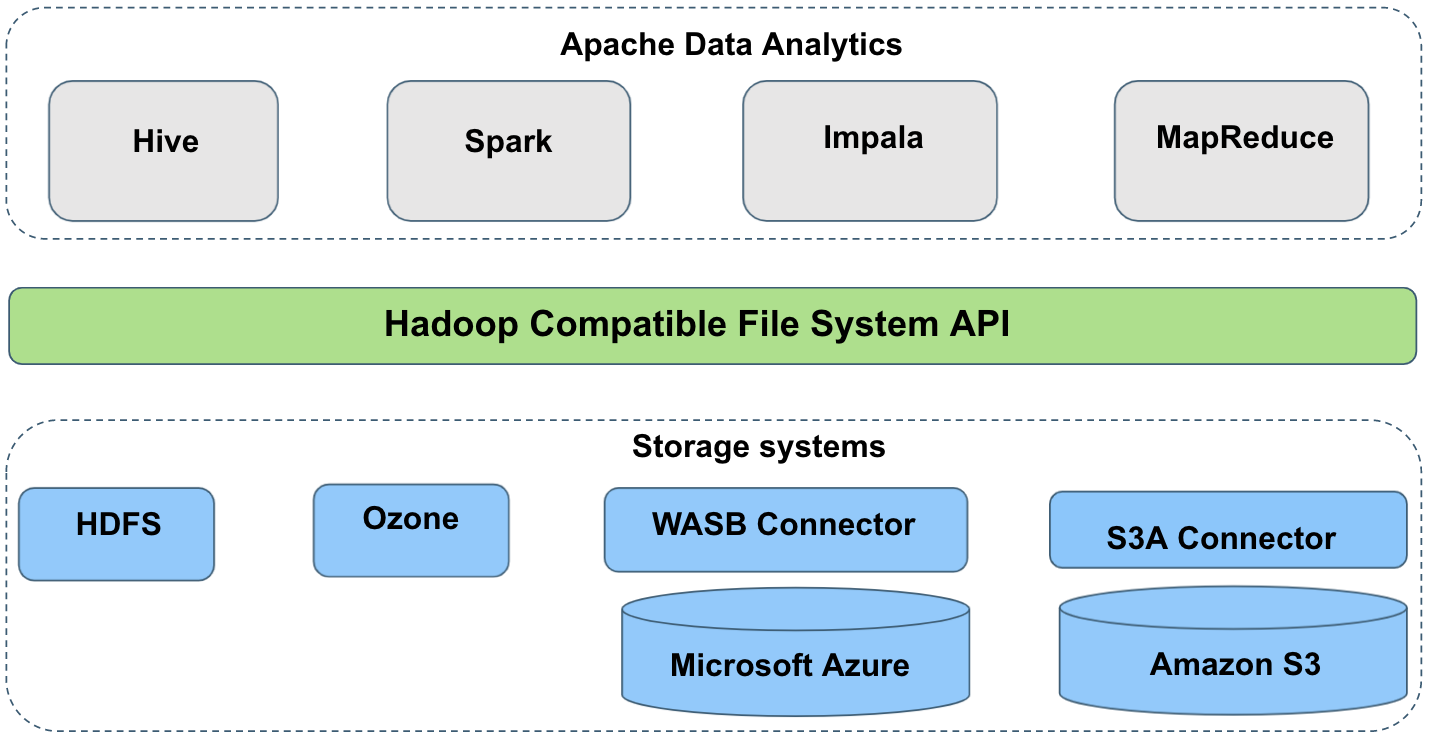
Apache Ozone supports interoperability of the same data for various use cases. For example, a user can ingest data into Apache Ozone using FileSystem API, and the same data can be accessed via Ozone S3 API*. This would potentially improve the efficiency of the user platform with on-prem ObjectStore.
Please refer to Apache Ozone documentation for more details regarding Apache Ozone’s atomicity guarantees.
In this blog post, we will look into benchmark test results measuring the performance of Apache Hadoop Teragen and a directory/file rename operation with Apache Ozone (native o3fs) vs. Ozone S3 API*. We enabled Apache Ozone’s FSO feature for the benchmarking tests.
Job Committers:
Apache data analytics traditionally assumes that rename and delete operations are strictly atomic. Most data analytics tools like Apache Hive, Apache Impala, Apache Spark, MR, etc. often write output to temporary locations and then rename it at the end of the job to become publicly visible. For example, the job committers of Hive and Impala require consistency of directory listing and atomicity of rename operations. Consequently, the performance of the query is directly impacted by how quickly the intermediate rename operation is completed. This means that job output is observed by readers on an all-or-nothing basis. Below is a high-level view of Apache data analytics and the interactions between the storage systems like Apache HDFS, Apache Ozone, S3-like object stores, etc. Even though Ozone is an object store, it does not need any special output committers.
Performance comparison between Apache Ozone and S3 API*
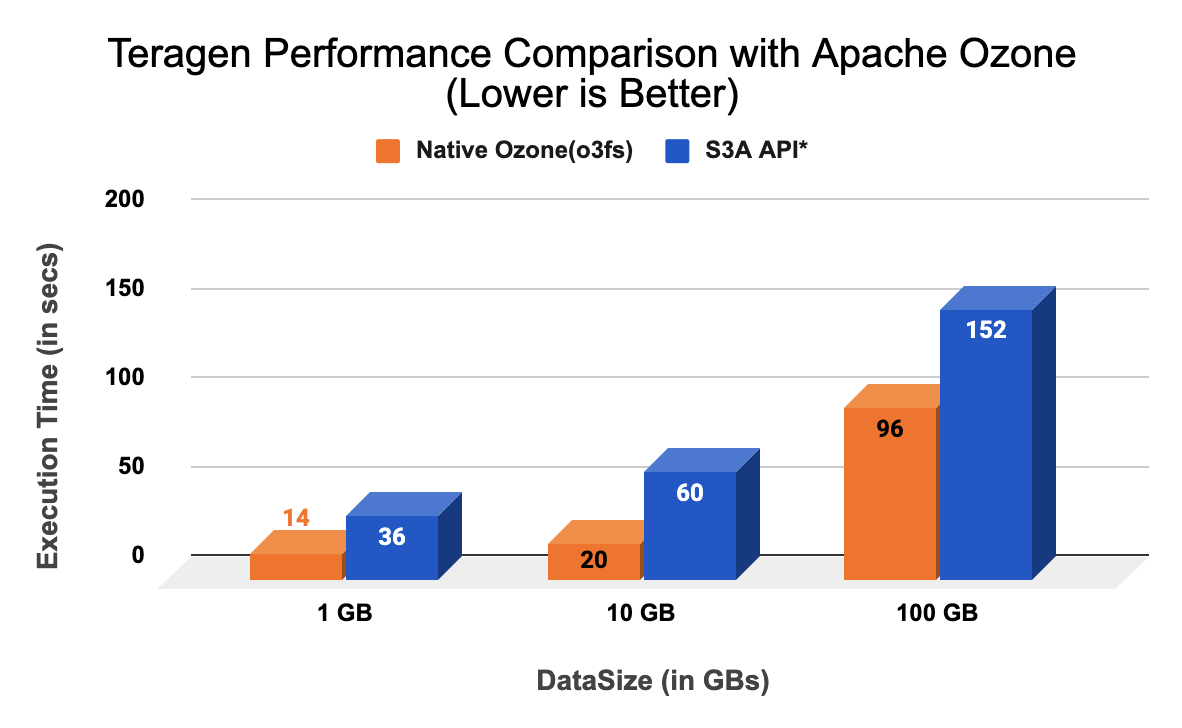
- Benchmarking Apache Ozone vs. S3 API* using Teragen:
We ran Apache Hadoop Teragen benchmark tests in a conventional Hadoop stack consisting of YARN and HDFS side by side with Apache Ozone. We used an Apache Hadoop S3A Filesystem connector to connect to the S3 API* and also used Hadoop’s default file committer to commit work to S3.
The following measurements were obtained using Teragen for various runs with data size in the range of 1GB, 10GB and 100GB respectively. We performed multi-run testing (three runs) for each data size, and the performance numbers have been averaged out with a max deviation of ~10% between runs. The results show that the performance of Native Ozone is faster than S3 object stores, e.g., S3 API*, etc).
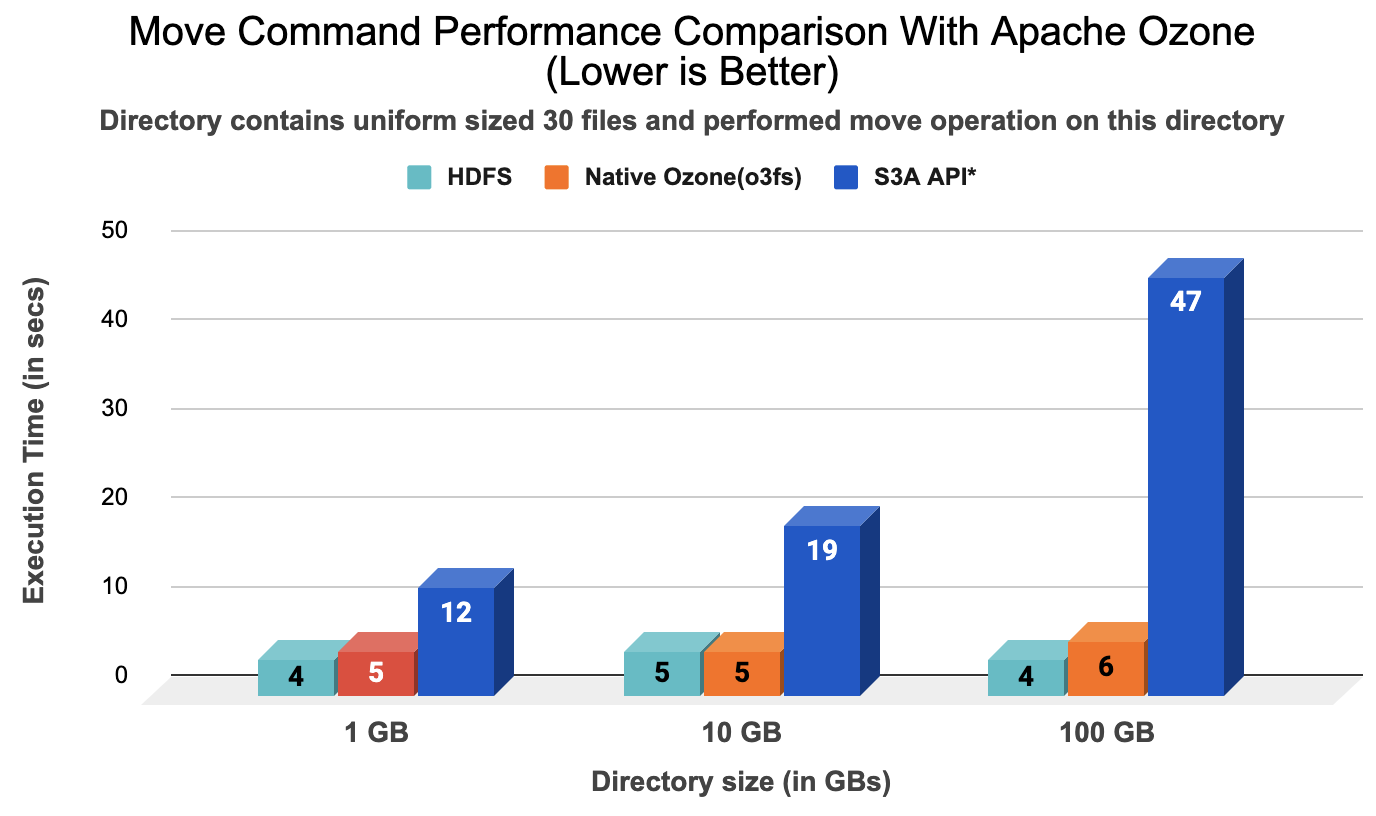
- File movement performance comparison:
We ran “hadoop mv command” tests on a directory of size in the range of 1GB, 10GB and 100GB respectively, stored in Apache Ozone and S3 API*. This directory contained a uniform-sized 30 files. Apache Native Ozone (o3fs) performed the renaming of source directory to destination directory similar to HDFS but unlike S3a (S3 API*, etc) which does a copy object and delete original object operation.
The following chart shows that Ozone performance for the move operation is in the same order as HDFS while retaining the atomicity guarantee. We performed multi-run testing (three runs) for each directory size, and the performance numbers have been averaged out with a max deviation of ~10% between runs.
Test Environment Details:
The cluster setup consisted of 10 uniform physical nodes with 40 core Intel® Xeon® processors, 128 GB of RAM, 3 x 2 TB disks, 1 x 1 TB disk and a 10 Gb/s network, configured with 3 dedicated disks for data storage. The nodes ran CentOS 7, and Cloudera Runtime 7.1.7, which contains Hadoop 3.1.1, ZooKeeper 3.5.5 and Ozone built from Apache master branch, version 1.1.0, github commit hash 19ed79464ca9ed2210ca8ac47a4736fb67d8bd3e.
SSL/TLS was turned off and in unsecure mode. High availability was enabled for the Apache Ozone service.
We used an Apache Hadoop S3A Filesystem connector to connect to the AWS S3 object store and also used Hadoop’s default file committer to commit work to S3.
Conclusion
The benchmark results showed that Apache Ozone with the File System Optimization (“FSO”) feature enabled was faster than an S3 API*-like an object store and very attractive for high-performance data-intensive workloads. With FSO, Ozone directory/file rename and delete operations are strongly consistent and give deterministic performance numbers irrespective of the large set of subpaths (directories/files) contained within it.
In short, Ozone with FSO helps users to achieve the same atomicity guarantees as HDFS with job and task commits thus making it natively integrated with Apache data analytics tools like Hive, Spark and Impala, etc. without the need for an S3Guard-like layer, while retaining its performance characteristics. Ozone in CDP Private Cloud provides out of the box security integration with Apache Ranger and Apache Atlas. Furthermore, data stored in Ozone can be shared between use cases deployed as part of CDP as well as external third-party analytics, eliminating the need for data duplication, which in turn reduces risk and optimizes resource utilization.
Further Reading
Apache Ozone – Object Store Overview
Apache Ozone – Object Store Architecture
S3 API* – refers to Amazon S3 implementation of the S3 API protocol.
Editor's Choice

