

Disclaimer: the scenario below is hypothetical. Any similarity to any specific telecommunications company is purely coincidental.
Although we use the example of a telecommunications company the following applies to every organization with customers or voluntary stakeholders.
Introduction
Imagine that you are a Chief Data Officer at a major telecommunications provider and the CEO has asked you to overhaul the existing customer churn analytics. The current process relies on manual export of data from dozens of data sources including ERP, CRM, and Call Detail Record (CDR) databases onto a user’s PC. The data is then manually collated into a massive spreadsheet which is copied and sent to ten different department heads, each of which does their own analysis based on the products and services they provide. The spreadsheet takes 15 minutes to open on their laptops but… it works. Recently the Chief Marketing Officer decided he needed a holistic view and bought an expensive, off-the-shelf software package including a pre-trained model to analyze the whole dataset.
The Problem
After many years of operating in this way the marketing intern who had been collating the data into that spreadsheet is ready to graduate. The programs and campaigns haven’t had a noticeable impact on overall churn and the Chief Information Officer is being asked tough questions about ROI. In addition, the newly appointed Data Protection Officer has sent official memos stating that the current practices leave the company at considerable risk of violating numerous government regulations relating to data privacy and acceptable use. More importantly you, as Chief Data Officer, receive an email from the CMO who has recently spent an inordinate amount of money on a post-mortem analysis with churned customers. The results can be summarized by one former customer’s comment:
“I switched carriers months ago and I have just now received an email, three phone calls, and four text messages from your company, each one offering me a different new feature for my upcoming renewal. Upcoming renewal?! I changed carriers months ago and none of the features they offered had anything to do with it. In any case, I’d like you to stop marketing to me, stop calling me, and erase all of my data.”
Anonymous Customer
The problem is clear. The existing process is too slow, too inaccurate, not holistic, leaves the business at considerable risk and relies on one person’s undocumented, manual work. Your palms are literally sweating at the idea of cleaning hundreds of historical spreadsheets on dozens of laptops and home directories… and those are just the ones you know about. Oh, and then there are all the source databases too.
“Hell hath no fury like an angry CDO.”
Anonymous IT Manager
The Solution
While the specific resolution is not obvious, you realize that the problem has been solved in similar domains using modern platforms and machine learning techniques. As you research options, you realize that the solution must be built around the core concepts of Speed and Agility with the following building blocks:
- Open Source: Anything (whether it is a single employee or a consultant or OEM software provider) that doesn’t allow your organization to OWN your data, your algorithms, and your models will eventually leave you blind. (By “own,” you understand not only the intellectual property rights but also have an intimate knowledge of the inner workings and capabilities.) Although you may need to rely on outside advice for building these capabilities initially, your team must have an intimate knowledge of the data and models to truly own your future. Additionally, open source software and libraries allow for rapid innovation and continuous development of your ability to meet your customers’ needs.
- Near-Real-Time: Monthly, manual updates of churn data are much too slow to really meet the needs of the business. Any processes and platforms used in this solution must enable the team’s ability to rapidly move through the workflow of data acquisition, visualization, model training, testing, deployment, and monitoring. Stale data and models are more insidious than none at all, since they give the false impression that an organization is making decisions based on timely insights.
- Governance and Lineage: Similar to the dangers of stale data, the organization faces real risks if it cannot understand what data is being used to make decisions. Rather than manually-curated copies of data, the solution must have a centralized single-point-of-truth that is used by all stakeholders to make decisions. Data stewards will ingest, clean and curate data in a central location while keeping track of versions, validity and other aspects of the data lifecycle.
- Secure and Auditable: Good governance, security and auditability are the vital foundations of rapid innovation with data. A data platform which lacks these enterprise-grade capabilities will eventually be shut down for not meeting regulatory compliance requirements.
- Interpretability: You’ve read the Interpretability report from Cloudera Fast Forward Labs and you know that many machine learning models can be “black boxes” which are nearly impossible to explain. Lacking clarity as to why a model has made a prediction, the business faces the real risk of making bad decisions. At best, the marketing and sales teams may recommend the wrong cross-sell or up-sell options to a customer. At worst, the company could spend tens of millions of dollars on an ill-advised campaign. Additionally, the Risk and Compliance team have warned you that Article 22 of the European Union’s General Data Protection Regulation (GDPR) stipulates that – among other things – ML models should be easily interpretable.
Starting with a Modern Platform
Coincidentally, your Advanced Analytics department has spent the last couple of months building a modern data platform based on Cloudera’s platform for machine learning and analytics. Your new Enterprise Data Cloud provides massive scale-out capabilities to efficiently analyze petabytes of data (in batch and near-real-time) with full governance, security, audit, and lineage. Additionally, the platform includes Cloudera Data Science Workbench which empowers data engineers and data scientists to leverage open-source frameworks in R, Python and Scala to rapidly ingest, explore, visualize, train, test and deploy machine learning models. You can see the light at the end of the tunnel. You’re a happy CDO!
“The world loves happy CDOs.”
Confucius
Meanwhile on the Data Science Team
Working in parallel with the platform build-out, your Head of Data Science is rebuilding the team. You’ve had a couple of false starts in the past two years with data scientists coming and going and, while you feel that you are off to a good restart, you recognize that time is of the essence.
With a modern platform, tooling, and open-source frameworks in place, the team worked with the marketing intern to set up an ingest pipeline using Cloudera Data Flow to regularly pull data from all of the data sources which they had previously been manually pulling. They have created a single-source-of-truth dataset with tagging and views to govern use, and to enable easy data deletion and audit access. Now your data science team can be turned loose to build a predictor model using something like scikit-learn for Python or Apache Spark MLlib.

Data Scientist: “Hey boss, our model predicts churn with a 90% accuracy.”
CDO: “EXCELLENT! On what is the prediction based? Which features led to the prediction? What can we do to influence any one customer? Can we do better than 90%? Are we at risk of overfitting?”
Data Scientist: “Hmmm… I’ll get back to you.”
Building Interpretable Models
Given enough time, you know that the team can build the interpretable churn models that you need. However, you have to show results very quickly and need a quick infusion of experience while the team is getting up to speed. You’ve learned the dangers of buying generic, off-the-shelf models, and decide to bring in Cloudera Fast Forward Labs’ (CFFL) Application Prototype and Development Services to rapidly build out a churn model and application that YOU own.
The CFFL team jumps in and, after dedicating some time to understanding your problem, your data and your upstream business processes, they begin working with your data scientists to build a model and deploy it with a RESTful API endpoint in Cloudera Data Science Workbench (CDSW).
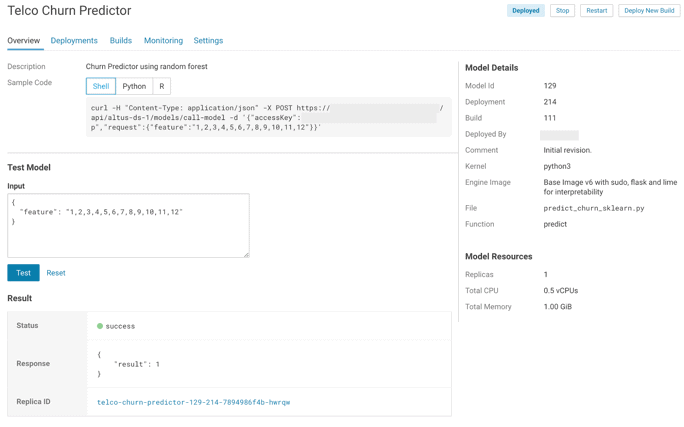
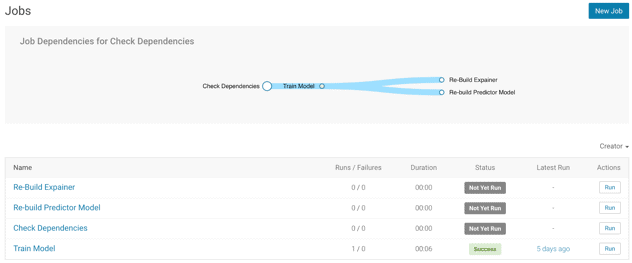
Now upstream business processes and applications can make calls into this API and receive a churn prediction for a customer. You are also leveraging the Jobs framework of CDSW to retrain, test, and deploy your predictor model on a weekly basis. On Monday mornings your team arrives to an email waiting in their inboxes with results of model retraining and the option to push models to production.
“I love Monday mornings now! I hated them at my last company.”
Anonymous Data Scientist
Now you focus on the interpretability questions. Although simple linear regression models, for example, can be fairly easy to explain, more complex and powerful models are usually a black box. Your CFFL team member proposes Local Interpretable Model-agnostic Explanation (LIME) algorithms to explain your black box models.
LIMEs and Mimes
LIME is an algorithm which takes as its input a trained model and an instance of data (e.g., a customer name) to be explained. LIME will feed the instance into the model and receive a churn prediction. The algorithm will then alter the input features of that instance slightly and get another prediction from the model. Repeating this process many times for each feature, LIME will “learn” how sensitive the model is to each feature. In this way, LIME is rather like a mime in a glass box feeling the perimeter of the model to understand its structure.
Using the Models interface of CDSW, your CFFL team has helped you deploy the Explainer Model next to the Predictor Model, and you see how LIME mimes can turn black box models into explainable glass boxes.
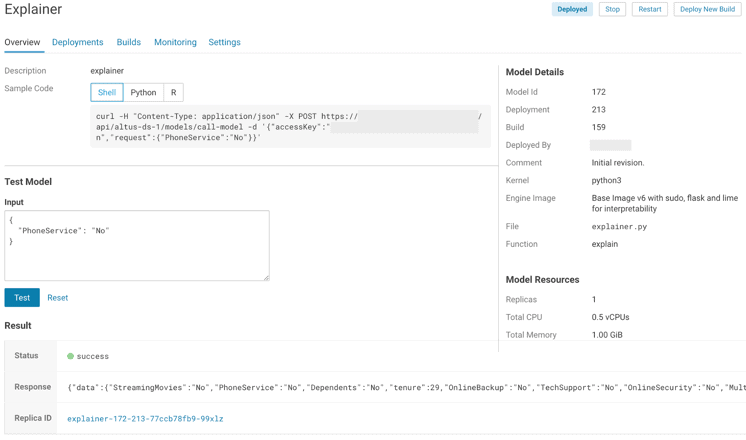
Okay, well, mostly explainable… The output of the LIME algorithm is something like this…
{"explanation":{"Service": 0.1464603218,"Contract":0.1258780537,"CLV": 0.0962594925,"tenure":0.096075437,"OOWServices":-0.0495489836,"Multi": 0.0485714257,"MonthlyBill":0.046862225,"Family":0.0461930664,"OSvcs":0.0357243848,"Generation":-0.0320810646}}
Everyone loves JSON, right?
“JSON is super cool!”
Anonymous Software Engineer
Visual Interpretability: Beyond glass boxes
While interpretability approaches like LIME provide some needed visibility, it’s also clear that many users across the organization will need to interact with the model and most of these users do NOT speak JSON. Since CDSW uses Docker containers and Kubernetes to deploy your Python code as a micro-service, you can use Flask to create a web-based, micro-services, frontend application of the LIME output.

Using the Experiments interface of CDSW, you can deploy the Flask application right next to both the predictor and explainer models. This Flask application displays the same JSON data as a list of features, where the color represents the relative importance of that feature in terms of its impact, positive or negative, on the likelihood of customer churn. Additionally, the application user has the ability to tactically change the value of features and see the resulting impact on the churn prediction. This is the “local” view of the model’s prediction for that particular instance.
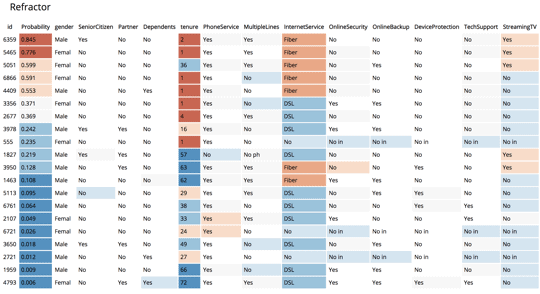
CFFL has also built for you a “global” view. By taking a random sample of instances, you can rank them in order of churn likelihood and represent them all in a table. Or – potentially – you could batch score the entire customer-base and stack-rank them on churn probability. In this way users can see, in one view, how sensitive each feature is across the whole sample.
Conclusion
In just about a month’s time, you have taken your company’s previous customer churn process and updated it to a fast, secure process – using the latest techniques in machine learning and AI. More importantly, you have a scalable platform, good data governance practices, and foundational ML capability development experience to quickly implement the next use-case. It’s a good thing, too. You have proven your abilities to quickly provide business value, and the Customer Operations Team is now knocking down your door to build a sentiment analysis engine for incoming support calls.
“You’re my favorite CDO. You haven’t quite solved world peace, but… people from all over the company have had a joyful experience understanding how their actions may influence customer retention.”
Anonymous CEO
Ready to get started? Check-out our upcoming webinar to see how it’s done.
We’ll cover using CDSW to build application prototypes that demonstrate how ML models can be implemented in data products and business processes, as well as building interpretability into models for transparency, accountability, and actionable insights. Register here.
Editor's Choice

