


Businesses often need to aggregate topics because it is essential for organizing, simplifying, and optimizing the processing of streaming data. It enables efficient analysis, facilitates modular development, and enhances the overall effectiveness of streaming applications. For example, if there are separate clusters, and there are topics with the same purpose in the different clusters, then it is useful to aggregate the content into one topic.
This blog post walks you through how you can use prefixless replication with Streams Replication Manager (SRM) to aggregate Kafka topics from multiple sources. To be specific, we will be diving deep into a prefixless replication scenario that involves the aggregation of two topics from two separate Kafka clusters into a third cluster.
This tutorial demonstrates how to set up the SRM service for prefixless replication, how to create and replicate topics with Kafka and SRM command line (CLI) tools, and how to verify your setup using Streams Messaging Manger (SMM). Security setup and other advanced configurations are not discussed.
Before you begin
The following tutorial assumes that you are familiar with SRM concepts like replications and replication flows, replication policies, the basic service architecture of SRM, as well as prefixless replication. If not, you can check out this related blog post. Alternatively, you can read about these concepts in our SRM Overview.
Scenario overview
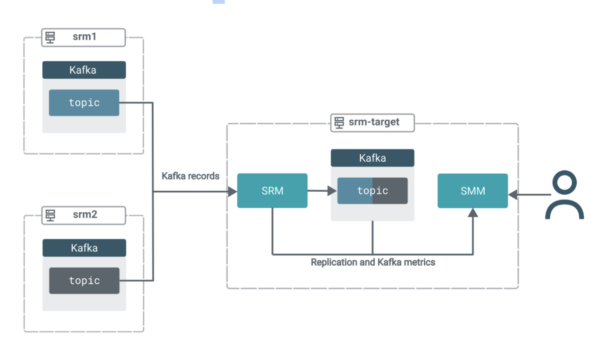
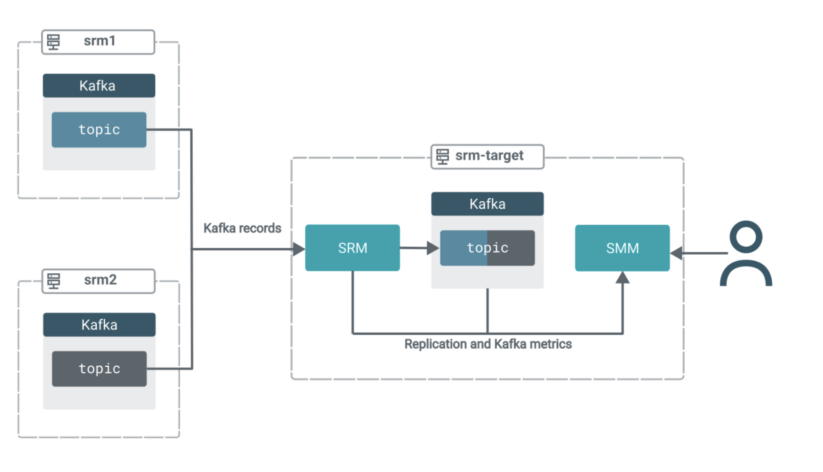
In this scenario you have three clusters. All clusters contain Kafka. Additionally, the target cluster (srm-target) has SRM and SMM deployed on it.
The SRM service on srm-target is used to pull Kafka data from the other two clusters. That is, this replication setup will be operating in pull mode, which is the Cloudera-recommended architecture for SRM deployments.
In pull mode, the SRM service (specifically the SRM driver role instances) replicates data by pulling from their sources. So rather than having SRM on source clusters pushing the data to target clusters, you use SRM located on the target cluster to pull the data into its co-located Kafka cluster.Pull mode is recommended as it is the deployment type that was found to provide the highest amount of resilience against various timeout and network instability issues. You can find a more in-depth explanation of pull mode in the official docs.
The records from both source topics will be aggregated into a single topic on the target cluster. All the while, you will be able to use SMM’s powerful UI features to monitor and verify what’s happening.
Set up SRM
First, you need to set up the SRM service located on the target cluster.
SRM needs to know which Kafka clusters (or Kafka services) are targets and which ones are sources, where they are located, how it can connect and communicate with them, and how it should replicate the data. This is configured in Cloudera Manager and is a two-part process. First, you define Kafka credentials, then you configure the SRM service.
Define Kafka credentials
You define your source (external) clusters using Kafka Credentials. A Kafka Credential is an item that contains the properties required by SRM to establish a connection with a cluster. You can think of a Kafka credential as the definition of a single cluster. It contains the name (alias), address (bootstrap servers), and credentials that SRM can use to access a specific cluster.
- In Cloudera manager, go to the Administration > External Accounts > Kafka Credentials page.
- Click “Add Kafka Credentials.”
- Configure the credential.
The setup in this tutorial is minimal and unsecure, so you only need to configure Name, Bootstrap Servers, and Security Protocol lines. The security protocol in this case is PLAINTEXT.
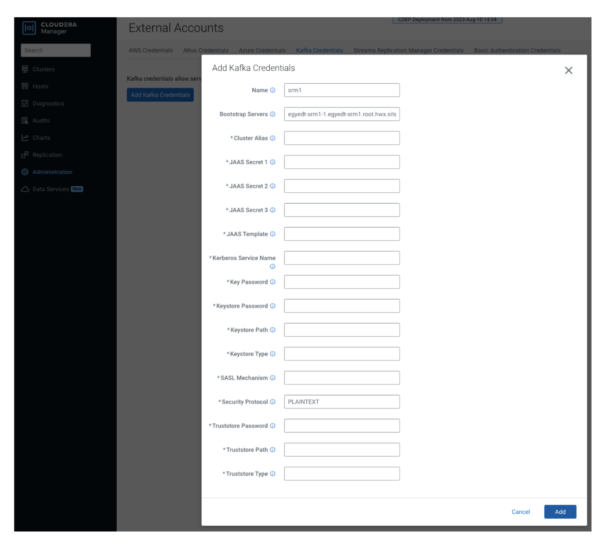
4. Click “Add” once you’re done, and repeat the previous step for the other cluster (srm2).
Configure the SRM service
After the credentials are set up, you’ll need to configure various SRM service properties. These properties specify the target (co-located) cluster, tell SRM what replications should be enabled, and that replication should happen in prefixless mode. All of this is done on the configuration page of the SRM service.
1. From the Cloudera Manager home page, select the “Streams Replication Manager” service.
2. Go to “Configuration.”
3. Specify the co-located cluster alias with “Streams Replication Manager Co-located Kafka Cluster Alias.”
The co-located cluster alias is the alias (short name) of the Kafka cluster that SRM is deployed together with. All clusters in an SRM deployment have aliases. You use the aliases to refer to clusters when configuring properties and when running the srm-control tool. Set this to:

Notice that you only need to specify the alias of the co-located Kafka cluster, entering connection information like you did for the external clusters is not ended. This is because Cloudera Manager passes this information automatically to SRM.
4. Specify External Kafka Accounts.
This property must contain the names of the Kafka credentials that you created in a previous step. This tells SRM which Kafka credentials it should import to its configuration. Set this to:

5. Specify all cluster aliases with “Streams Replication Manager Cluster” alias.
The property contains a comma-delimited list of all cluster aliases. That is, all aliases you previously added to the Streams Replication Manager Co-located Kafka Cluster Alias and External Kafka Accounts properties. Set this to:

6. Specify the driver role target with Streams Replication Manager Driver Target Cluster.
The property contains a comma-delimited list of all cluster aliases. That is, all aliases you previously added to the Streams Replication Manager Co-located Kafka Cluster Alias and External Kafka Accounts properties. Set this to:

7. Specify service role targets with Streams Replication Manager Service Target Cluster.
This property specifies the cluster that the SRM service role will gather replication metrics from (i.e. monitor). In pull mode, the service roles must always target their co-located cluster. Set this to:
8. Specify replications with Streams Replication Manager’s Replication Configs.
This property is a jack-of-all-trades and is used to set many SRM properties that are not directly available in Cloudera Manager. But most importantly, it is used to specify your replications. Remove the default value and add the following:

9. Select “Enable Prefixless Replication”
This property enables prefixless replication and tells SRM to use the IdentityReplicationPolicy, which is the ReplicationPolicy that replicates without prefixes.
10. Review your configuration, it should look like this:
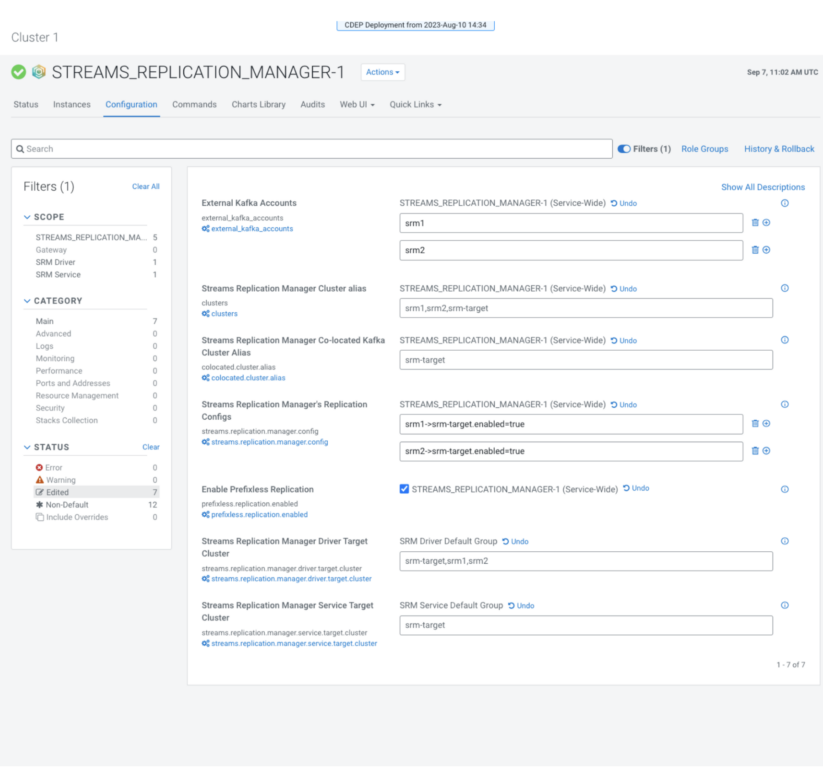
13. Click “Save Changes” and restart SRM.
Create a topic, produce some records
Now that SRM setup is complete, you need to create one of your source topics and produce some data. This can be done using the kafka-producer-perf-test CLI tool.
This tool creates the topic and produces the data in one go. The tool is available by default on all CDP clusters, and can be called directly by typing its name. No need to specify full paths.
- Using SSH, log in to one of your source cluster hosts.
- Create a topic and produce some data.
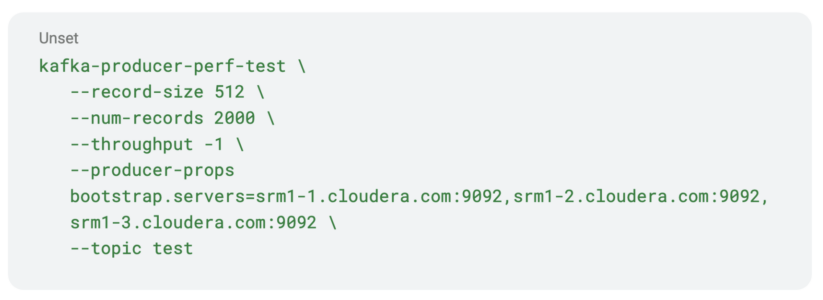
Notice that the tool will produce 2000 records. This will be important later on when we verify replication on the SMM UI.
Replicate the topic
So, you have SRM set up, and your topic is ready. Let’s replicate.
Although your replications are set up, SRM and the source clusters are connected, data is not flowing, the replication is inactive. To activate replication, you need to use the srm-control CLI tool to specify what topics should be replicated.
Using the tool you can manipulate the replication to allow and deny lists (or topic filters), which control what topics are replicated. By default, no topic is replicated, but you can change this with a few simple commands.
- Using SSH, log in to the target cluster (srm-target).
- Run the following commands to start replication.

Notice that even though the topic on srm2 doesn’t exist yet, we added the topic to the replication allow list as well. The topic will be created later. In this case, we are activating its replication ahead of time.
Insights with SMM
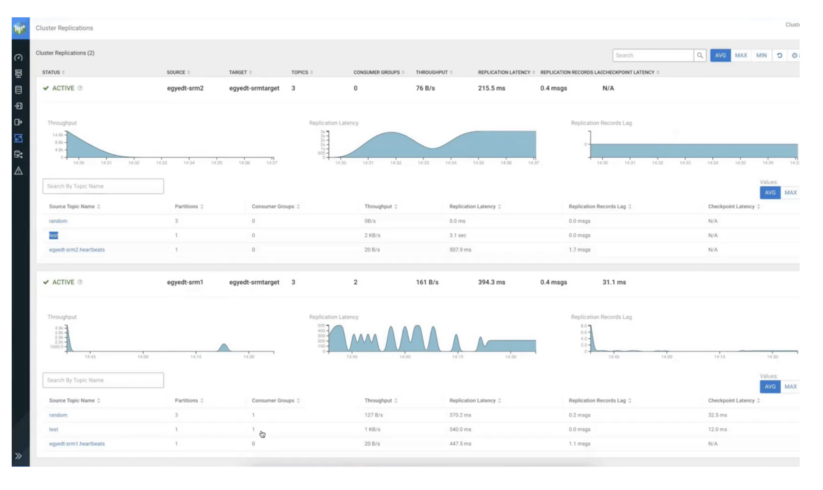
Now that replication is activated, the deployment is in the following state:
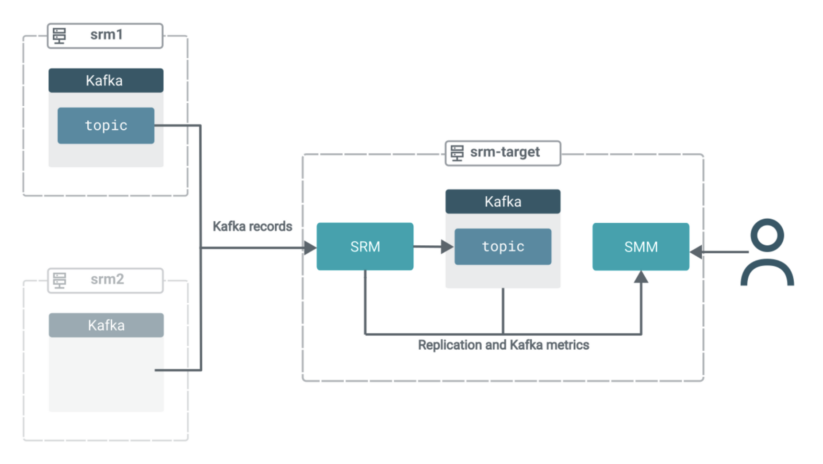
In the next few steps, we will shift the focus to SMM to demonstrate how you can leverage its UI to gain insights into what is actually going on in your target cluster.

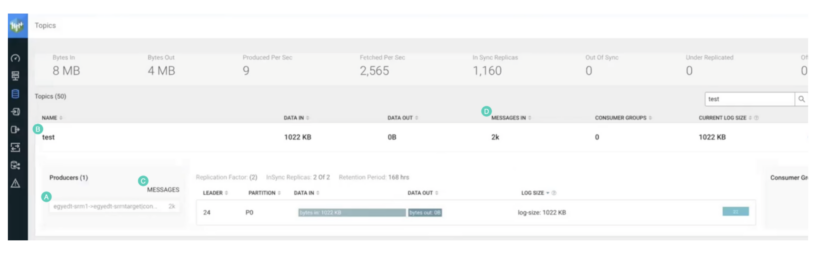
Notice the following:
- The name of the replication is included in the name of the producer that created the topic. The -> notation means replication. Therefore, the topic was created with replication.
- The topic name is the same as on the source cluster. Therefore, it was replicated with prefixless replication. It does not have the source cluster alias as a prefix.
- The producer wrote 2,000 records. This is the same amount of records that you produced in the source topic with kafka-producer-perf-test.
- “MESSAGES IN” shows 2,000 records. Again, the same amount that was originally produced.
On to aggregation
After successfully replicating data in a prefixless fashion, its time move forward and aggregate the data from the other source cluster. First you’ll need to set up the test topic in the second source cluster (srm2), as it doesn’t exist yet. This topic must have the exact same name and configurations as the one on the first source cluster (srm1).
To do this, you need to run kafka-producer-perf-test again, but this time on a host of the srm2 cluster. Additionally, for bootstrap you’ll need to specify srm2 hosts.

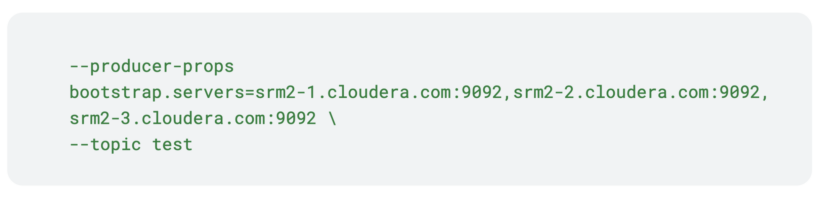
Notice how only the bootstraps are different from the first command. This is crucial, the topics on the two clusters must be identical in name and configuration. Otherwise, the topic on the target cluster will constantly switch between two configuration states. Additionally, if the names do not match, aggregation will not happen.
After the producer is finished with creating the topic and producing the 2000 records, the topic is immediately replicated. This is because we preactivated replication of the test topic in a previous step. Additionally, the topic records are automatically aggregated into the test topic on srm-target.
You can verify that aggregation has happened by having a look at the topic in the SMM UI.
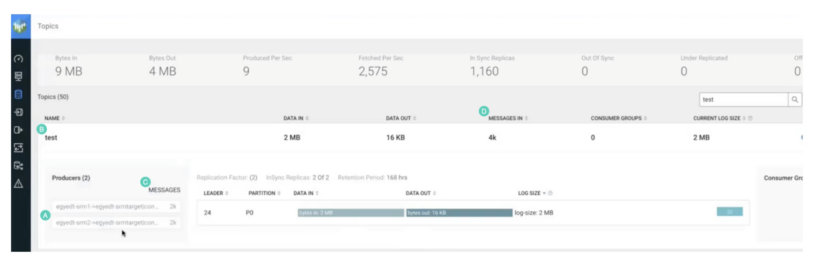
The following indicates that aggregation has happened:
- There are now two producers instead of one. Both contain the name of the replication. Therefore, the topic is getting records from two replication sources.
- The topic name is still the same. Therefore, perfixless replication is still working.
- Both producers wrote 2,000 records each.
- “MESSAGES IN” shows 4,000 records.

 Summary
Summary
In this blog post we looked at how you can use SRM’s prefixless replication feature to aggregate Kafka topics from multiple clusters into a single target cluster.
Although aggregation was in focus, note that prefixless replication can be used for non-aggregation type replication scenarios as well. For example, it is the perfect tool to migrate that old Kafka deployment running on CDH, HDP, or HDF to CDP.
If you want to learn more about SRM and Kafka in CDP Private Cloud Base, hop over to Cloudera’s doc portal and see Streams Messaging Concepts, Streams Messaging How Tos, and/or the Streams Messaging Migration Guide.
To get hands on with SRM, download Cloudera Stream Processing Community edition here.
Interested in joining Cloudera?
At Cloudera, we are working on fine-tuning big data related software bundles (based on Apache open-source projects) to provide our customers a seamless experience while they are running their analytics or machine learning projects on petabyte-scale datasets. Check our website for a test drive!
If you are interested in big data, would like to know more about Cloudera, or are just open to a discussion with techies, visit our fancy Budapest office at our upcoming meetups.
Or, just visit our careers page, and become a Clouderan!
Editor's Choice

