

Replication is a crucial capability in distributed systems to address challenges related to fault tolerance, high availability, load balancing, scalability, data locality, network efficiency, and data durability. It forms a foundational element for building robust and reliable distributed architectures. It is also important to have multiple options (like normal and prefixless replication) to do the replication process, since every solution has its own advantages.
Streams Replication Manager (SRM) is an enterprise-grade replication solution that enables fault tolerant, scalable, and robust cross-cluster Kafka topic replication. SRM replicates data at high performance and keeps topic properties in sync across clusters. Replication can be dynamically enabled for topics and consumer groups. SRM also delivers custom extensions that facilitate installation, management, and monitoring, making SRM a complete replication solution that is built for mission-critical workloads.
Introduction
Kafka as an event streaming component can be applied to a wide variety of use cases. SRM provides cross-cluster Kafka topic replication to make it more fault tolerant and robust. SRM is based on the Mirror Maker 2 (MM2) component of Kafka, which is the improved version of Mirror Maker (MM1). MM1 has been used for years in large-scale production environments, but not without several limitations—that is why MM2 was introduced.
These are some of the MM1 limitations that MM2 addresses:
- Topics are created with default configuration, often needed to be repartitioned manually.
- ACL and configuration changes are not synced across mirrored clusters. This makes it difficult to manage multiple clusters.
- Records are repartitioned with DefaultPartitioner. Semantic partitioning may be lost.
- Any configuration change means the cluster must be bounced. This includes adding new topics to the whitelist, which may be a frequent operation.
- No mechanism to migrate producers or consumers between mirrored clusters.
- No support for exactly once delivery. Records may be duplicated during replication.
- Rebalancing causes latency spikes, which may trigger further rebalances.
When SRM replicates a topic, it renames the topic in the target cluster by prefixing the name of the topic with the alias (name) of the source cluster. This differs from the way replication worked in MM1, where the target topics had the same name as the source (thus “prefixless”). The MM1 behavior is crucial for some use-cases. For example, cluster migration scenarios cannot be correctly carried out with the default replication behavior of SRM, the MM1 behavior is a must. Up until now, this type of replication was not available or fully supported. Moreover, MM1 was deprecated in one of the more recent releases of Kafka (Kafka 3.0.0) and its use is no longer recommended.
To address this, Cloudera introduced a new MM1-compatible mode in SRM. Starting with Cloudera Data Platform (CDP) Private Cloud Base 7.1.9, prefixless replication is generally available with replication monitoring support in SRM. This makes it possible to migrate cluster replication workloads from the deprecated MM1 to SRM without change in the replicated topic names.
Replicated topic names
The naming of the replicated topics is defined by the replication policy that SRM is configured to use. By default, SRM uses the DefaultReplicationPolicy, which adds the source cluster alias as a prefix to the name of replicated topics. In the past, this was the only policy available natively in SRM and the design of the replication monitoring features in the service was based on the assumption that every replicated topic would always have a prefix. Therefore, SRM service role instances were only able to monitor replication flows that used a replication policy that uses prefixes, such as the DefaultReplicationPolicy.
Once the IdentityReplicationPolicy was introduced, users were able to replicate topics without having prefixes added to the replicated topic names. Due to the design of the SRM service though, these replications could not be monitored until the release of CDP Private Cloud Base 7.1.9.
Note: SRM supports custom topic naming policies through a plugin called replication policy. There are two different Replication policy types shipped with SRM by default:
- DefaultReplicationPolicy – default policy. Prefixes topic names with “<source_cluster>.”
- IdentityReplicationPolicy – policy which does not change topic names during replication. (with this policy, replication monitoring does not work until CDP 7.1.9 release)
Remote topic discovery
SRM needs to be able to know which topics are replicas and what are their respective source topics. It relies on the replication policy and the topic naming conventions to discover replica topics by default. The process lists all of the topic names of a cluster, then detects the source cluster name. When using the DefaultReplicationPolicy, SRM knows that a topic is a replica when it has a prefix that is a valid cluster alias (<cluster_alias>.). The replica topic name contains the alias of the source cluster and name of the source topic. For instance, the topic name can be source-cluster.topic-name. In this case source-cluster will be the alias of the source cluster, while topic-name will be the name of the topic in the source cluster.
This discovery procedure has some limitations, since it relies on topic naming conventions to provide source cluster information. When the IdentityReplicationPolicy is used, the source cluster cannot be identified by this method. Furthermore, the current state of the replication (stopped, active, etc.) has no connection with the replica topic detection—if a topic has been removed from the SRM replication configuration, the logic will still detect the prefixed topic as a replica topic.
The above shortcomings were addressed in the CDP Private Cloud Base 7.1.9. In this release, SRM is shipped with a new property Use Internal Topic For Remote Topics Discovery, which is enabled for new installations. For upgraded clusters, this feature will be disabled by default to ensure that existing SRM deployments will continue to work without changes in behavior.
When Use Internal Topic For Remote Topics Discovery is enabled, SRM drivers will write the list of source topic—target topic pairs that have to be replicated to an internal, compacted topic (srm-meta.internal), stored on the target cluster. SRM drivers will periodically check which topics need to be replicated and will write updates to the internal topic as needed.
Clients trying to discover replica topics are able to scan the “srm-meta.internal” topic, and consume the latest message—which lists the currently replicated topics. This data also contains the source-target topic name mappings. It makes the feature independent of the ReplicationPolicy that is in use.
Prefixless replication
From CDP 7.1.9, SRM supports data replication, checkpointing, and monitoring with the IdentityReplicationPolicy. Identity replication, or prefixless replication, means that replica topics’ names will be the same as on the source cluster (MM1-compatible mode, but with the advantages of MM2). The IdentityReplicationPolicy can also be used for topic aggregation use cases, where the same topic on multiple clusters are replicated to the same identically-named “aggregated topic” on a different cluster. Of course, aggregation can be avoided if DefaultReplicationPolicy is in use or if the separate source clusters have different topic names.
To enable prefixless replication for SRM, you only need to select the “Enable Prefixless Replication” property in the SRM service configuration.
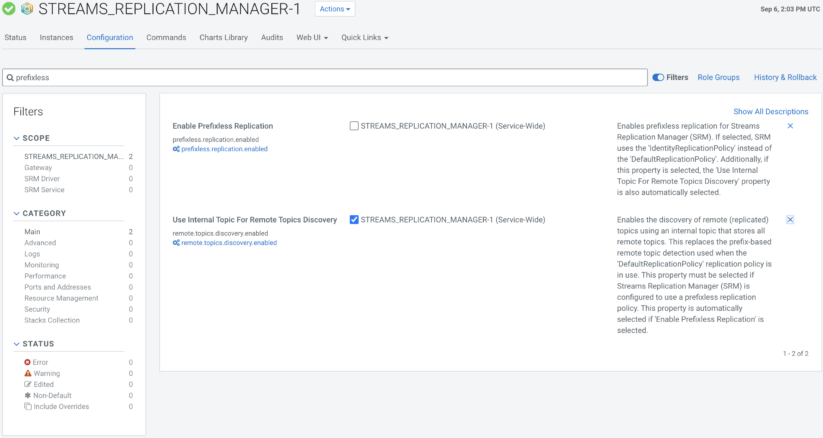
When “Enable Prefixless Replication” is selected, SRM must also enable the “Use Internal Topic For Remote Topics Discovery” feature due to the limitations of replica discovery mentioned previously in this blog. Fortunately, Cloudera Manager handles this automatically, so if a user enables the “Enable Prefixless Replication” option, Cloudera Manager will override the configuration of “Use Internal Topic For Remote Topics Discovery” to enable it.
Prefixless replication is not free of limitations or caveats. Be aware of the following:
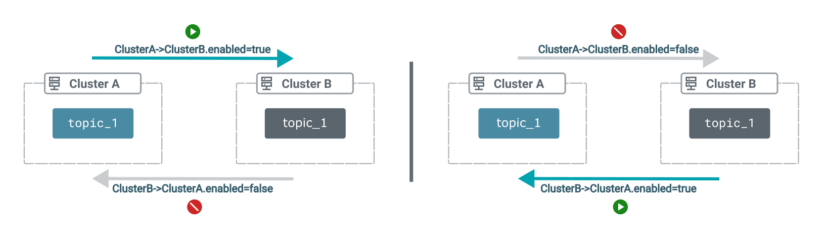
- Replication loop detection is not supported
As a result, you must ensure that topics are not replicated in a loop between your source and target clusters. You can ensure this by setting up your topic allow and deny lists (also known as topic filters) in a way that’s appropriate for your use case.
For example, assume you have two replications that replicate topics between two clusters, but in different directions. If both replications include topic_1, they must never be enabled at the same time.
- All SRM services must use the same replication policy
For example, if you want to use prefixless replication then all of the SRM services should use IdentityReplicationPolicy. In case of prefixed replication DefaultReplicationPolicy should be used everywhere. Clusters connected by replication flows, regardless of the number of SRM services, should only use one ReplicationPolicy. Otherwise, replications will be mixed up and unwanted side effects can happen.
- Group offset sync should be disabled
SRM makes a mapping about Kafka message offsets of the source and target clusters. Offset checkpoints are stored in the source clusters and they will be interpreted only if the message is coming from the current source cluster. If more source clusters have the same group offsets, then they can interfere with each other, so group offset sync should be disabled.
- Not all REST API endpoints and SMM UI features are supported
- The /v2/topic-metrics/{target}/{downstreamTopic}/{metric} endpoint of the SRM Service v2 API does not work properly with prefixless replication. Use the /v2/topic-metrics/{source}/{target}/{upstreamTopic}/{metric} endpoint instead.
- The replication metric graphs shown on the Topic Details page of the SMM UI do not work with prefixless replication. The graph is not displayed.
Summary
Prefixless replication enables you to use MM1-like replication behavior in CDP while having access to the many enterprise ready features that SRM provides. While aggregation is the main use case for prefixless replication, it can also be used to build traditional replication pipelines that provide a safety net for your Kafka data if things go amiss. Better yet, prefixless replication is also a perfect tool to migrate that old Kafka deployment running on CDH, HDP, or HDF to CDP.
In addition, the changes and improvements to remote topic discovery that were introduced alongside prefixless replication make SRM more robust than ever as some core features within SRM, like replication monitoring, no longer need to rely on topic prefixes to function.
If you want to learn more about SRM and Kafka in CDP Private Cloud Base, hop over to Cloudera’s doc portal and see Streams Messaging Concepts, Streams Messaging How Tos, and/or the Streams Messaging Migration Guide. This is the first of a two-blog series, to continue your journey on Streams Replication, click here.
To get hands on with SRM, download Cloudera Stream Processing Community edition here.
Interested in joining Cloudera?
At Cloudera, we are working on fine-tuning big data related software bundles (based on Apache open-source projects) to provide our customers a seamless experience while they are running their analytics or machine learning projects on petabyte-scale datasets. Check our website for a test drive!
If you are interested in big data, would like to know more about Cloudera, or are just open to a discussion with techies, visit our fancy Budapest office at our upcoming meetups. Or, just visit our careers page, and become a Clouderan!
Editor's Choice

