

More of you are moving to public cloud services for backup and disaster recovery purposes, and Cloudera has been enhancing the capabilities of Cloudera Manager and CDH to help you do that. Specifically, Cloudera Backup and Disaster Recovery (BDR) now supports backup to and restore from Amazon S3 for Cloudera Enterprise customers.
BDR lets you replicate Apache HDFS data from your on-premise cluster to or from Amazon S3 with full fidelity (all file and directory metadata is replicated along with the data). In case of replicating Apache Hive data, apart from data, BDR replicates metadata of all entities (e.g. databases, tables, etc.) along with statistics (e.g. Apache Impala(incubating) statistics, etc.) This feature supports many different use cases. For example, you can:
- Use Amazon S3 as a lower-cost alternative to running your own backup cluster.
- Run batch workloads such as ETL data pipelines on data stored in S3 on transient clusters run by Cloudera Altus or AWS instances provisioned by Cloudera Director.
- Run Hive and Impala queries directly against data on S3 without copying it to HDFS first.
- Migrate the data from long running AWS clusters using local storage into to S3-backed clusters.
This blog post takes you through a BDR-S3 replication use case. Initially we will backup the Hive tables from an on-premise cluster to Amazon S3. There will be another cluster deployed in AWS with only a small amount of storage to reduce the operating cost. We will then restore Hive tables to the cluster in the cloud. During the restore, we will choose the option of Hive-on-S3 which will not copy data to HDFS, but instead creates Hive external tables pointing to the data in S3. We will be able to run all possible operations on Hive tables while data remains in S3.
Prerequisites
- Backup to and restore from Amazon S3 is supported from CM 5.9 onwards and CDH 5.9 onwards.
- When Hive data is backed up to Amazon S3 with a CDH version, the same data can be restored to the same CDH version.
Adding AWS Credentials
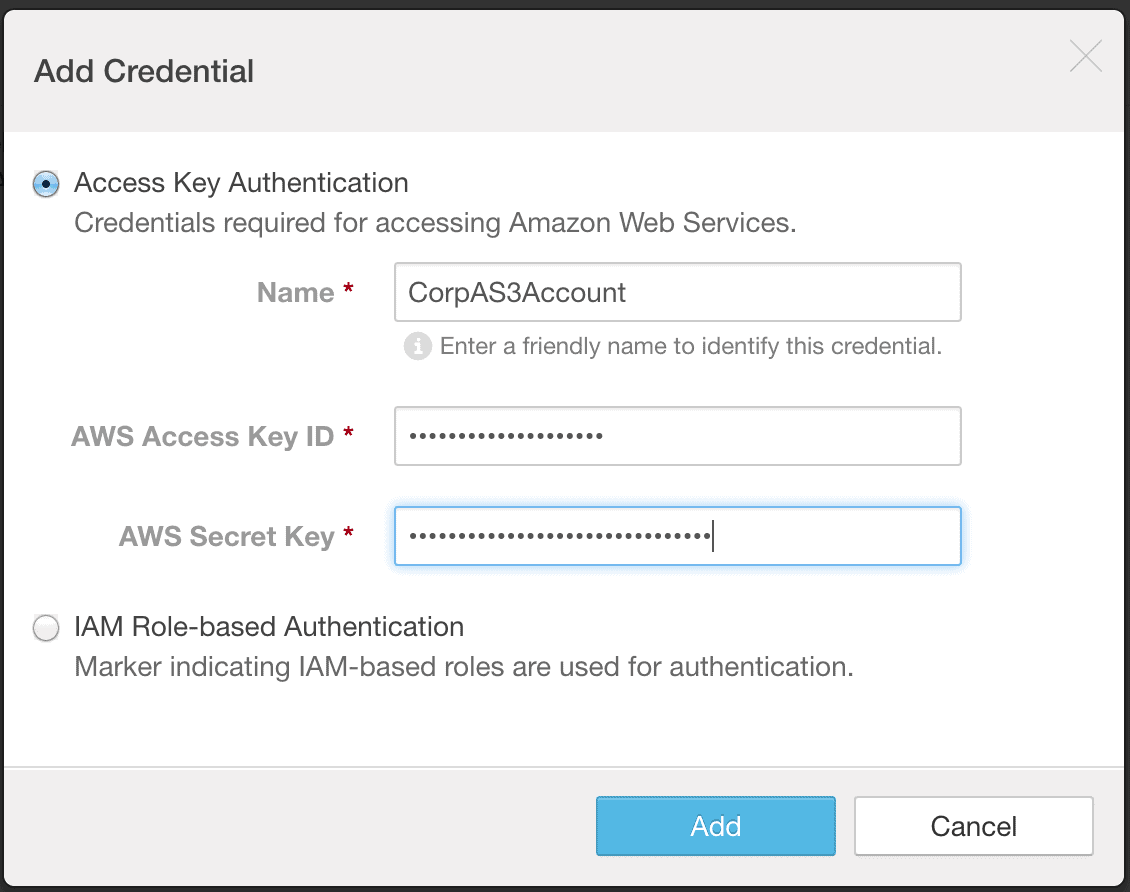
The first step for using BDR’s S3 replication is to add your AWS credentials in the Cloudera Manager Admin Console. Please refer to the documentation for configuring AWS Credentials. You’ll need the AWS access key and secret key for Access Key Authentication.
- Go to “Administration” -> “AWS Credentials”.
- Click “Add”.
- Add the AWS S3 access key and secret key. This is a one-time setup step. Add the credentials using the Cloudera Manager Admin Console on both the source cluster and the cloud cluster where you will restore the data.
Backup to and restore from Amazon S3 operations use these keys to access the given bucket.
Backing up a Hive table to S3:
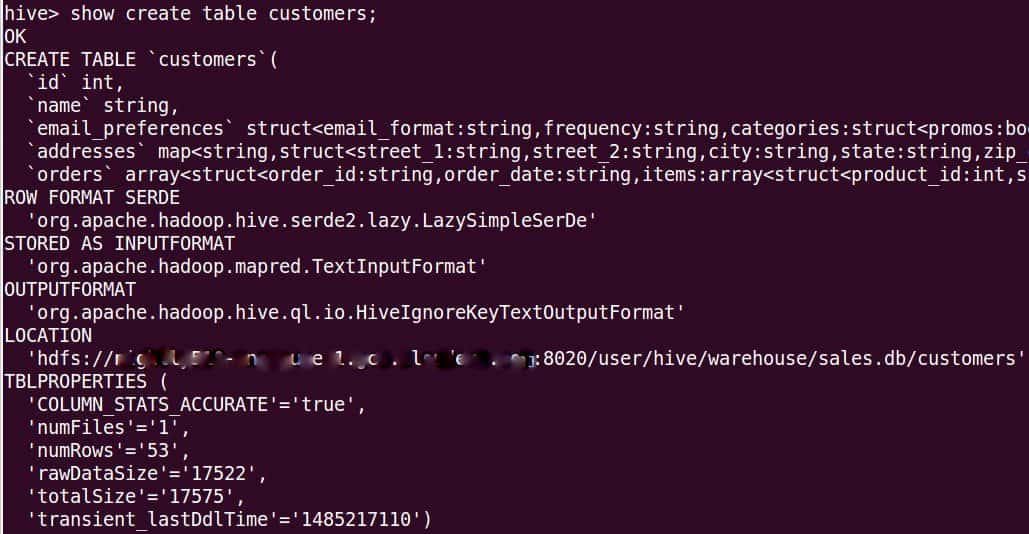
Suppose we have “customers” table in the “sales” database in Hive in the on-premise cluster and we want to take a backup. The following screenshot shows the information for the table. Please note the location of the table is in local HDFS.
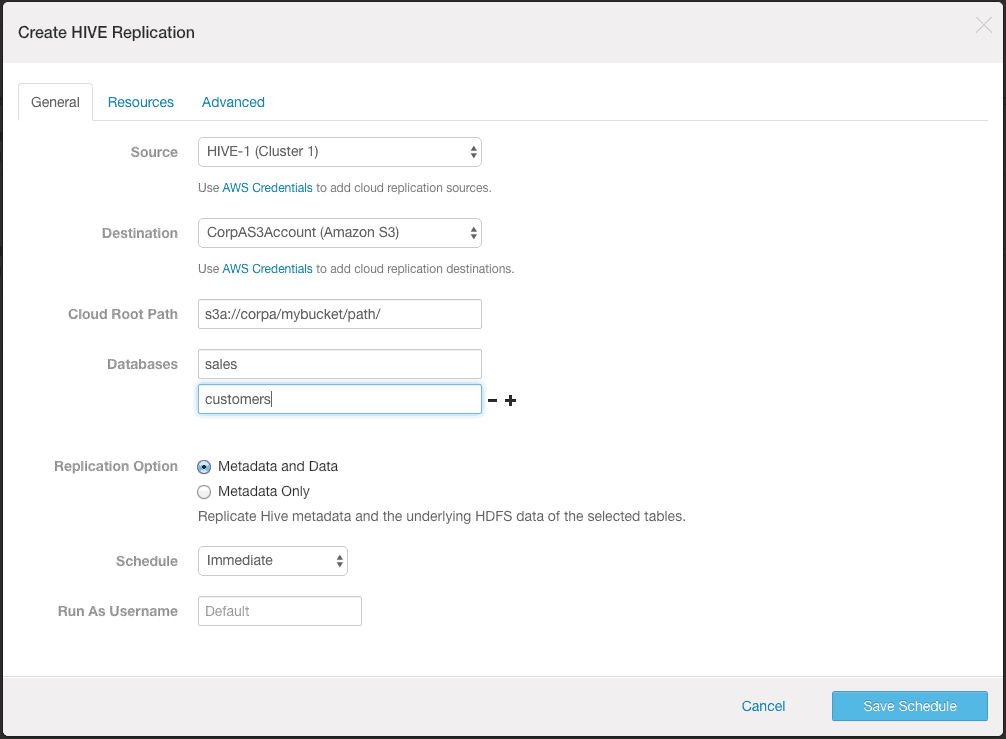
- Go to the source cluster from which you want to backup the Hive table.
- Open the Cloudera Manager Admin console.
- Go to Backup -> Replication Schedules.
- Click Create Replication -> Hive Replication.
- Select the hive service as the source and select the AWS account that you added above as the destination. You will need to provide the S3 path and the names of databases and tables to backup.
- Because we want to backup the data as well as the metadata of the table to S3, select the “Metadata and Data” option.
After successfully running the backup operation, you will see data in the S3 path you specified. Please login into AWS console and go to the S3 service. Then locate the S3 path specified to see that the data was copied successfully. As Amazon S3 provides eventual consistency for read-after-write, it may take some time for data to be in consistent state.
S3 path contents:
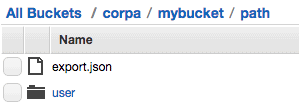
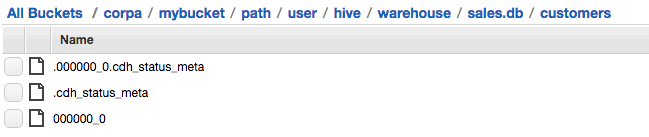
The “export.json” file created at root level of the specified s3 path contains Hive metadata in JSON format. The restore operation uses this metadata to create entities in the destination Hive service. The data files are created in S3 with the exact same path. The hidden file “.cdh_status_meta” created contains HDFS attributes for the “customers” folder. The hidden file “.000000_0.cdh_status_meta” created contains HDFS attributes for the data file 000000_0. The meta files are used for creating the files on the destination HDFS with full fidelity (all metadata attributes).
Note: We do not recommend manual changes to the files inside the given S3 path.
Restoring the table to another Hive while keeping data in S3
Now we want to restore the Hive data to the cluster on cloud with Hive-on-S3 option. With this option, the operation will replicate metadata as external Hive tables in the destination cluster that point to data in S3, enabling direct S3 query by Hive and Impala. The destination cluster can be created using Cloudera Director. Please refer the documentation for creating a cluster using Cloudera Director.
- Go to the destination cluster where you want to restore the Hive table.
- Open the Cloudera Manager Admin Console.
- Go to Backup -> Replication Schedules.
- Click “Create Replication -> Hive Replication”.
- Select the AWS account you added above as the source and the Hive service as the destination. You will need to provide the S3 path containing the data and the names of databases and tables to restore. The S3 path should be the same path where export.json was created during backup.
- Because we want to keep data in S3 and do not want to copy data to the destination HDFS, select the “Hive-on-S3” option. Before using this option, please make sure that Hive can access s3 locations. The documentation provides the steps for the same.
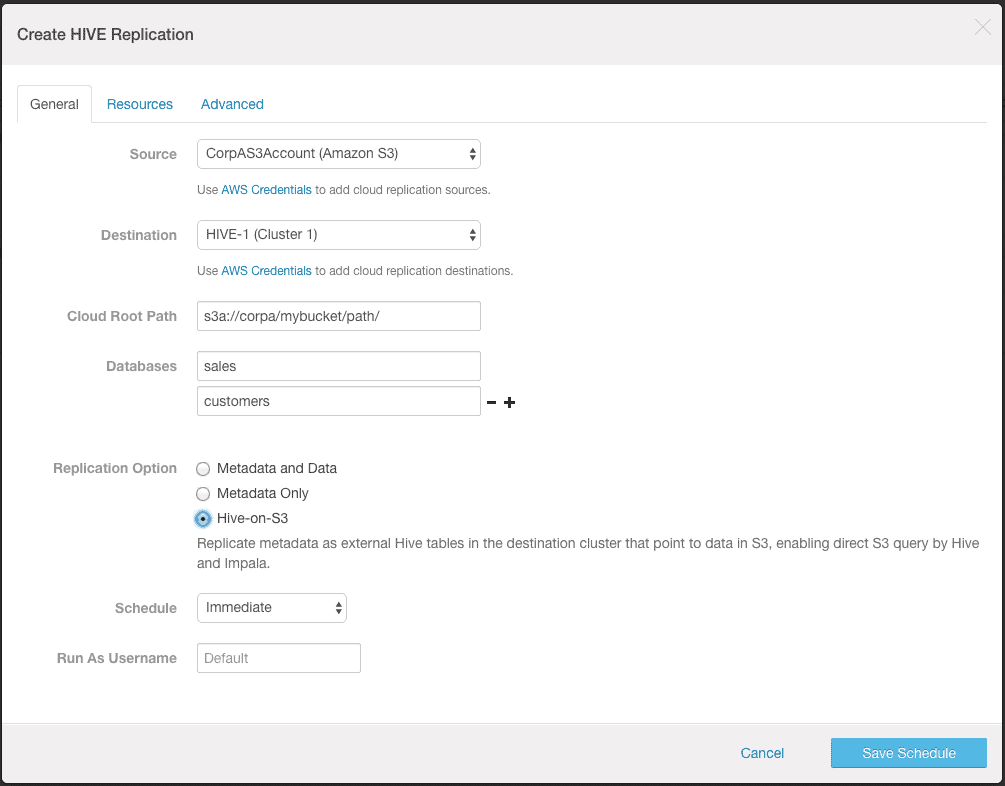
After successful run of restore operation, you will see that the external table has been created in Hive with its LOCATION attribute pointing to the S3 path:
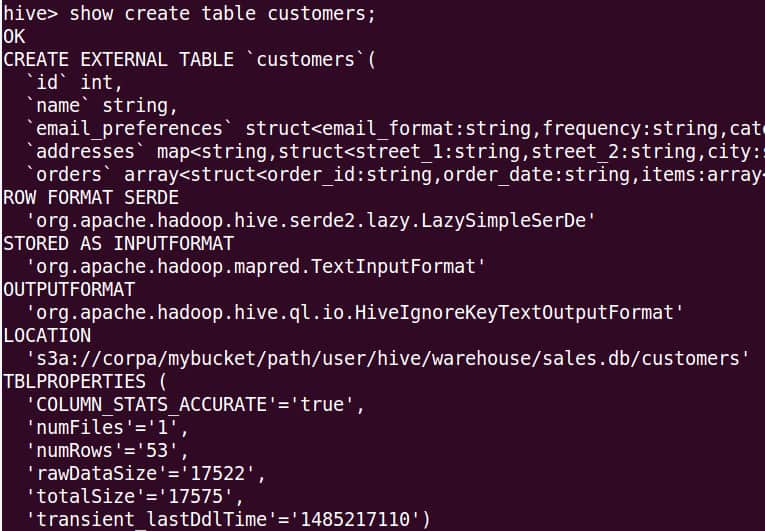
You can now run any operation on the “customers” table.
Performance considerations:
When restoring Hive tables using the Hive-on-S3 option, we create an external table pointing to data located in Amazon S3. When using this option, data is immediately available to query, and also can be shared across multiple clusters. This approach is especially useful for ETL and batch reporting workloads run on transient clusters where clusters are quickly created and torn down as needed. However, although the same queries may continue to be executed seamlessly after the restore, because data is in Amazon S3 and not a local HDFS filesystem (where compute nodes access data in direct attached storage), query performance will be slower, and will vary considerably based on the type and location of EC2 instances used for the cluster. Customers should consider this when using the Hive-on-S3 option, and allocate cluster resources for their workloads accordingly. We recommend consulting the AWS documentation on how to optimize the performance of accessing S3 data from EC2. Specifically, customers should always use EC2 instances located in the same region as their S3 buckets. Also, please review Cloudera’s documentation for more performance tuning tips for running Hive on S3.
Performance of backup to Amazon S3 operation is better when there is a small number of large files vs. a large number of small files. Users should consider aggregating small files into one large file before running this operation. In our testing, backup to Amazon S3 of 100,000 7KB-files was around 150x slower than backup to Amazon S3 of 1000-1MB files. Note that these performance numbers are mere indicators of this effect, and your performance numbers may vary.
Due to network latency, the performance of backup to and restore from Amazon S3 is better when the cluster and the Amazon S3 bucket are closer geographically, particularly within the same AWS region.
Replicating HDFS data to Amazon S3 is an incremental operation. When files at the target location in Amazon S3 have not been modified, BDR will skip copying these files in successive replication runs, copying only the new files. As such, the initial replication run for may take much longer than subsequent runs, and is proportional to the size of new or modified files. Frequent replication will reduce the time it takes to keep the replica in sync.
Editor's Choice

