

Every large enterprise organization is attempting to accelerate their digital transformation strategies to engage with their customers in a more personalized, relevant, and dynamic way. The ability to perform analytics on data as it is created and collected (a.k.a. real-time data streams) and generate immediate insights for faster decision making provides a competitive edge for organizations.
Organizations are increasingly building low-latency, data-driven applications, automations, and intelligence from real-time data streams. Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the data processing components up the stream to address these real-time needs.
Cloudera Stream Processing (CSP) enables customers to turn streams into data products by providing capabilities to analyze streaming data for complex patterns and gain actionable intel. For example, a large biotech company uses CSP to manufacture devices to exact specifications by analyzing and alerting on out-of-spec resolution color imbalance. A number of large financial services companies use CSP to power their global fraud processing pipelines and prevent users from exploiting race conditions in the loan approval process.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Over the last seven years, Cloudera’s Stream Processing product has evolved to meet the changing streaming analytics needs of our 700+ enterprise customers and their diverse use cases. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. The combination of Kafka as the storage streaming substrate, Flink as the core in-stream processing engine, and first-class support for industry standard interfaces like SQL and REST allows developers, data analysts, and data scientist to easily build real time data pipelines that power data products, dashboards, business intelligence apps, microservices, and data science notebooks.
CSP was recently recognized as a leader in the 2022 GigaOm Radar for Streaming Data Platforms report.
This blog aims to answer two questions as illustrated in the diagram below:
- How have stream processing requirements and use cases evolved as more organizations shift to “streaming first” architectures and attempt to build streaming analytics pipelines?
- How is Cloudera Stream Processing (CSP) staying in lock-step with the changing needs of our customers?
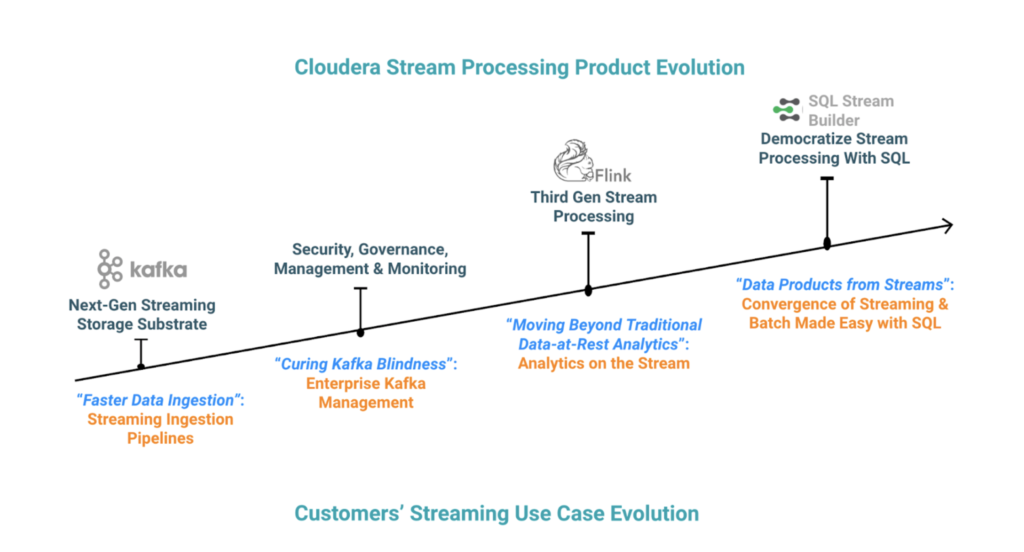
Figure 1: The evolution of Cloudera Stream Processing offering based on customers’ evolving streaming use cases and requirements.
Faster data ingestion: streaming ingestion pipelines
As customers started to build data lakes and lakehouses (before it was even given this name) for multifunction analytics, a critical number of desired outcomes started to emerge around data ingestion:
- Support the scale and performance demands of streaming data: The traditional tools that were used to move data into data lakes (traditional ETL tools, Sqoop) were limited to batch ingestion and did not support the scale and performance demands of streaming data sources.
- Reduce ingest latency and complexity: Multiple point solutions were needed to move data from different data sources to downstream systems. The batch nature of these tools increased the overall latency of the analytics. Faster ingestion was needed to reduce overall analytics latency.
- Application integration and microservices: Real-time integration use cases required applications to have the ability to subscribe to these streams and integrate with downstream systems in real-time.
These desired outcomes beget the need for a distributed streaming storage substrate optimized for ingesting and processing streaming data in real-time. Apache Kafka was purpose-built for this need, and Cloudera was one of the earliest vendors to offer support. The combination of Cloudera Stream Processing and DataFlow powered by Apache Kafka and NiFi respectively has helped hundreds of customers build real-time ingestion pipelines, achieving the above desired outcomes with architectures like the following.
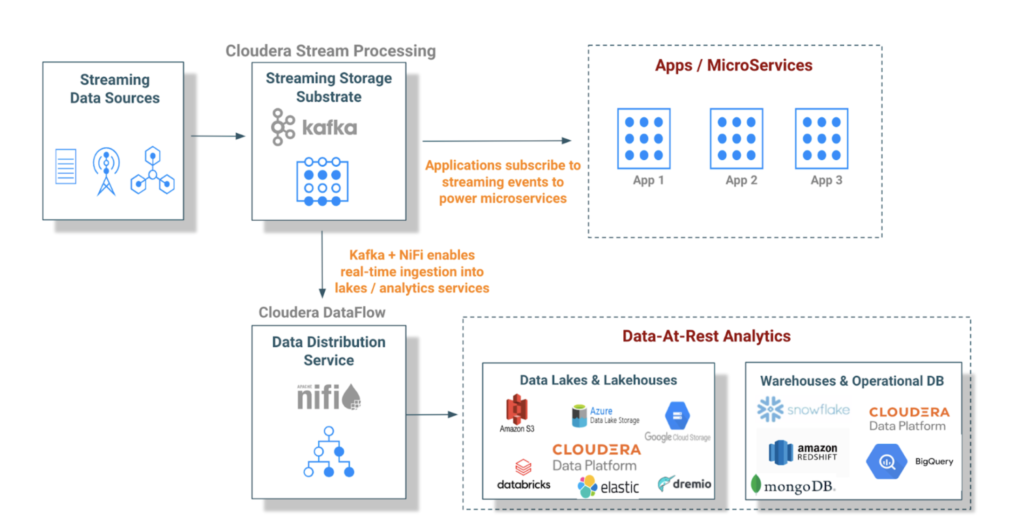
Figure 2: Draining Streams Into Lakes: Apache Kafka is used to power microservices, application integration, and enable real-time ingestion into various data-at-rest analytics services.
Kafka blindness: the need for enterprise management capabilities for Kafka
As Kafka became the standard for the streaming storage substrate within the enterprise, the onset of Kafka blindness began. What is Kafka blindness? Who is affected? Kafka blindness is the enterprise’s struggle to monitor, troubleshoot, heal, govern, secure, and provide disaster recovery for Apache Kafka clusters.
The blindness doesn’t discriminate and affects different teams. For a platform operations team, it was the lack of visibility at a cluster and broker level and the effects of the broker on the infrastructure it runs on and vice versa. While for a DevOps/app team, the user is primarily interested in the entities associated with their applications. These entities are the topics, producers, and consumers associated with their application. The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities. For governance and security teams, the questions revolve around chain of custody, audit, metadata, access control, and lineage. The site availability teams are focused on meeting the strict recovery time objective (RTO) in their disaster recovery cluster.
Cloudera Stream Processing has cured the Kafka blindness for our customers by providing a comprehensive set of enterprise management capabilities addressing schema governance, management and monitoring, disaster recovery, simple data movement, intelligent rebalancing, self healing, and robust access control and audit.
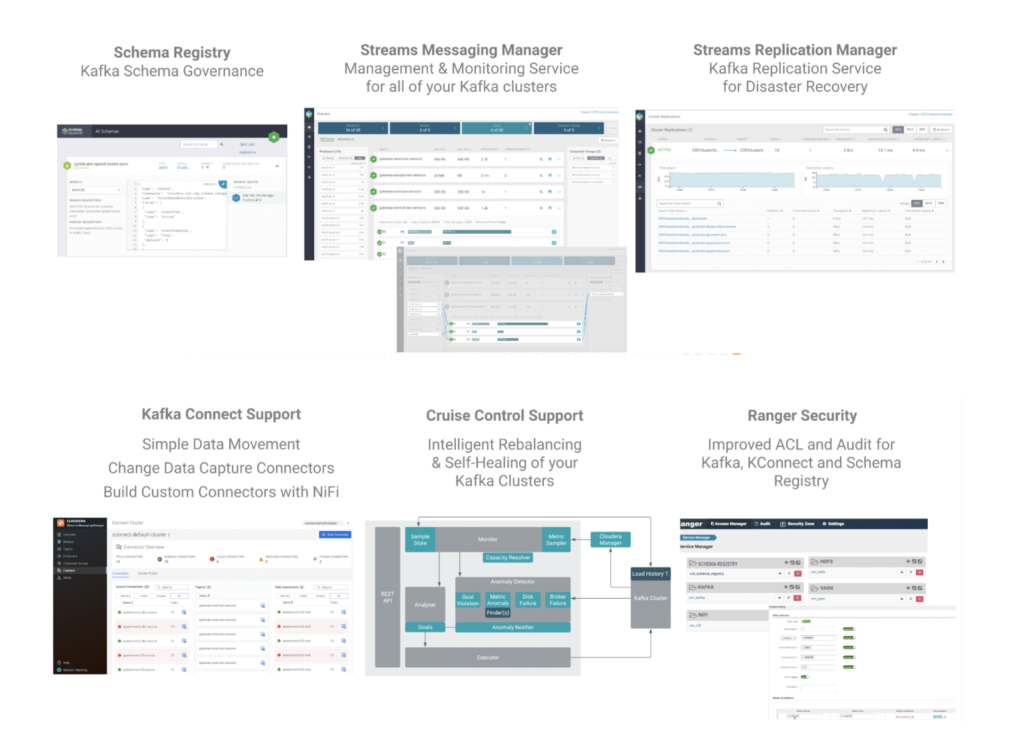
Figure 3: Cloudera Stream Processing offers a comprehensive set of enterprise management services for Apache Kafka.
Moving beyond traditional data-at-rest analytics: next generation stream processing with Apache Flink
By 2018, we saw the majority of our customers adopt Apache Kafka as a key part of their streaming ingestion, application integration, and microservice architecture. Customers started to understand that to better serve their customers and maintain a competitive edge, they needed the analytics to be done in real time, not days or hours but within seconds or faster.
The vice president of architecture and engineering at one of the largest insurance providers in Canada summed it up well in a recent customer meeting:
“We can’t wait for the data to persist and run jobs later, we need real-time insight as the data flows through our pipeline. We had to build the streaming data pipeline that new data has to move through before it can be persisted and then provide business teams access to that pipeline for them to build data products.”
In other words, Kafka provided a mechanism to ingest streaming data faster but traditional data-at-rest analytics was too slow for real-time use cases and required analysis to be done as close to data origination as possible.
In 2020, to address this need, Apache Flink was added to the Cloudera Stream Processing offering. Apache Flink is a distributed processing engine for stateful computations ideally suited for real-time, event-driven applications. Building real-time data analytics pipelines is a complex problem, and we saw customers struggle using processing frameworks such as Apache Storm, Spark Streaming, and Kafka Streams.
The addition of Apache Flink was to address the hard problems our customers faced when building production-grade streaming analytics applications including:
- Stateful stream processing: How do I efficiently, and at scale, handle business logic that requires contextual state while processing multiple streaming data sources? E.g.: Detecting a catastrophic collision event in a vehicle by analyzing multiple streams together: vehicle speed changes from 60 to zero in under two seconds, front tire pressure goes from 30 psi to error code and in less than one second, the seat sensor goes from 100 pounds to zero.
- Exactly once processing: How do I ensure that data is processed exactly once at all times even during errors and retries? E.g.: A financial services company needs to use stream processing to coordinate hundreds of back-office transaction systems when consumers pay their home mortgage.
- Handle late-arriving data: How does my application detect and deal with streaming events that come out of order? E.g.: Real-time fraudulent services that need to ensure data is processed in the right order even if data arrives late.
- Ultra-low latency: How do I achieve in-memory, one-at-a time stream processing performance? E.g.: Financial institutions that need to process requests of 30 million active users making credit card payments, transfers, and balance lookups with millisecond latency.
- Stateful event triggers: How do I trigger events when dealing with hundreds of streaming sources and millions of events per second per stream? E.g.: A healthcare provider that needs to support external triggers so that when a patient checks into an emergency room waiting room, the system reaches out to external systems to pull patient-specific data from hundreds of sources and make that data available in an electronic medical record (EMR) system by the time the patient walks into the exam room.
Apache Kafka is critical as the streaming storage substrate for stream processing, and Apache Flink is the best in breed compute engine to process the streams. The combination of Apache Kafka and Flink is essential as customers move from data-at-rest analytics to data-in-motion analytics that power low latency, real-time data products.
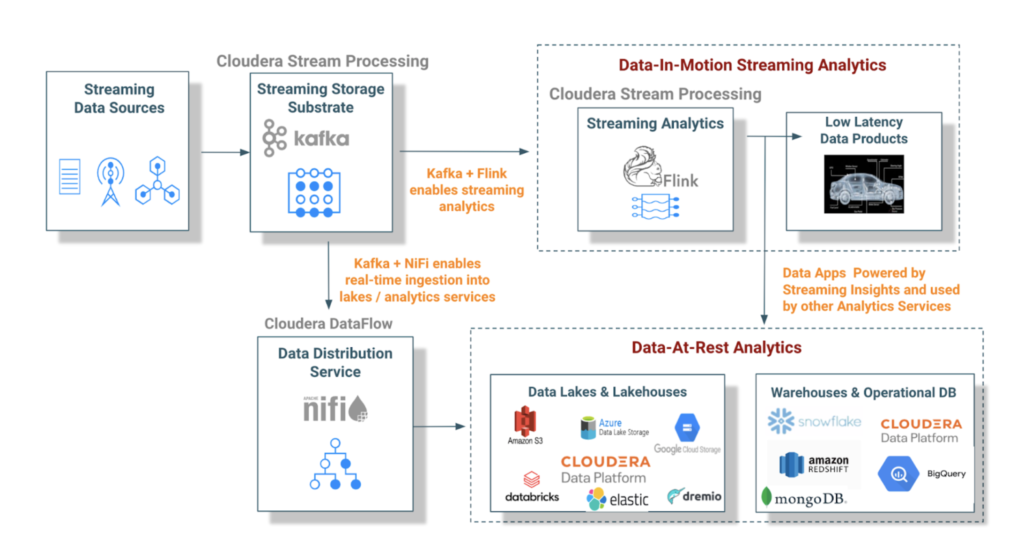
Figure 4: For real-time use cases that require low latency, Apache Flink enables analytics in-stream without persisting the data and then performing analytics.
Making the Lailas of the world successful: democratize streaming analytics with SQL
While Apache Flink adds powerful capabilities to the CSP offering with a simple high-level API in multiple languages, constructs of stream processing like stateful processing, exactly once semantics, windowing, watermarking, subtleties between event, and system time are new concepts for most developers and novel concepts to data analysts, DBAs, and data scientists.
Meet Laila, a very opinionated practitioner of Cloudera Stream Processing. She is a smart data analyst and former DBA working at a planet-scale manufacturing company. She needs to measure the streaming telemetry metadata from multiple manufacturing sites for capacity planning to prevent disruptions. Laila wants to use CSP but doesn’t have time to brush up on her Java or learn Scala, but she knows SQL really well.
In 2021, SQL Stream Builder (SSB) was added to CSP to address the needs of Laila and many like her. SSB provides a comprehensive interactive user interface for developers, data analysts, and data scientists to write streaming applications with industry standard SQL. By using SQL, the user can simply declare expressions that filter, aggregate, route, and mutate streams of data. When the streaming SQL is executed, the SSB engine converts the SQL into optimized Flink jobs.
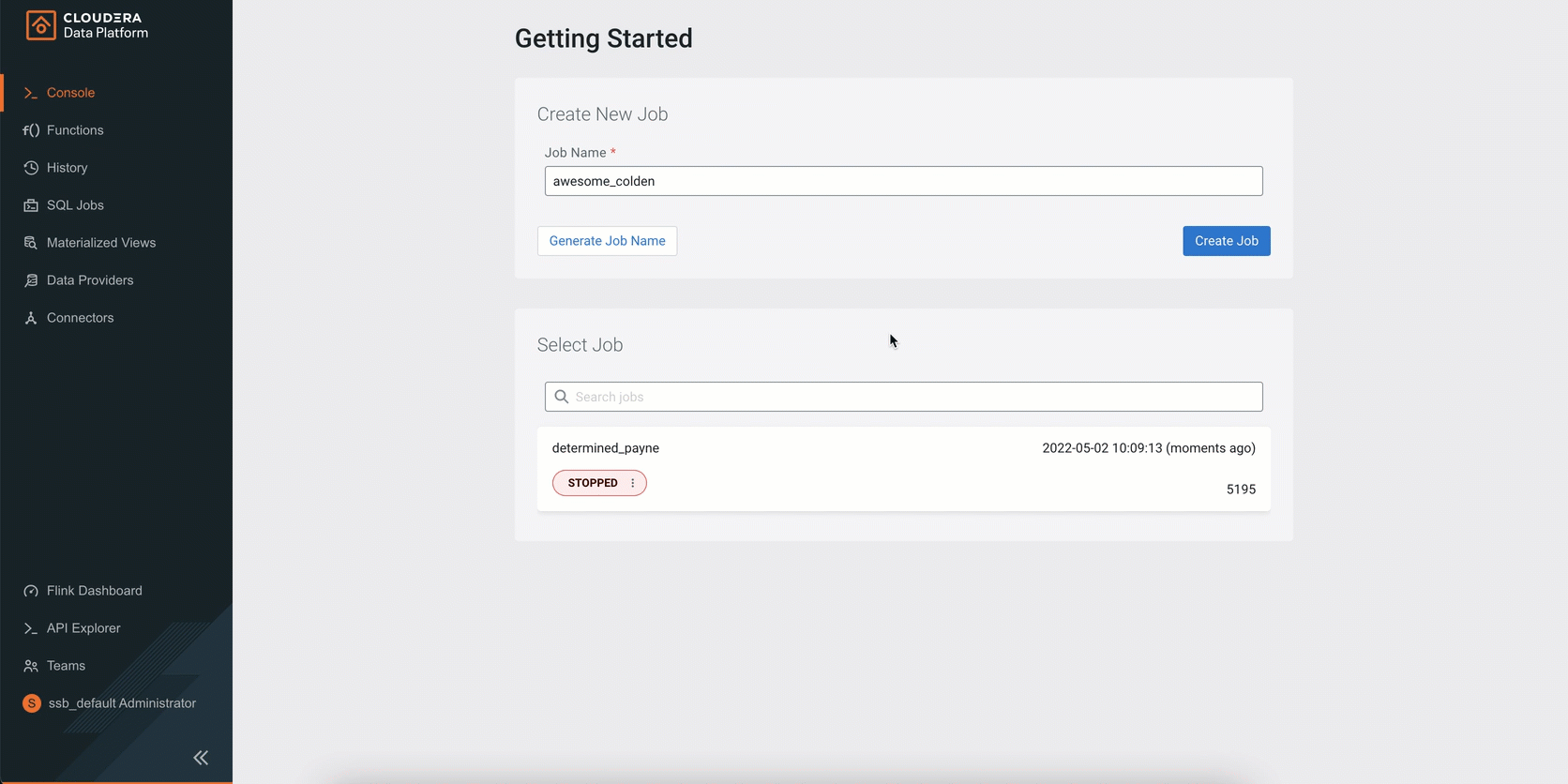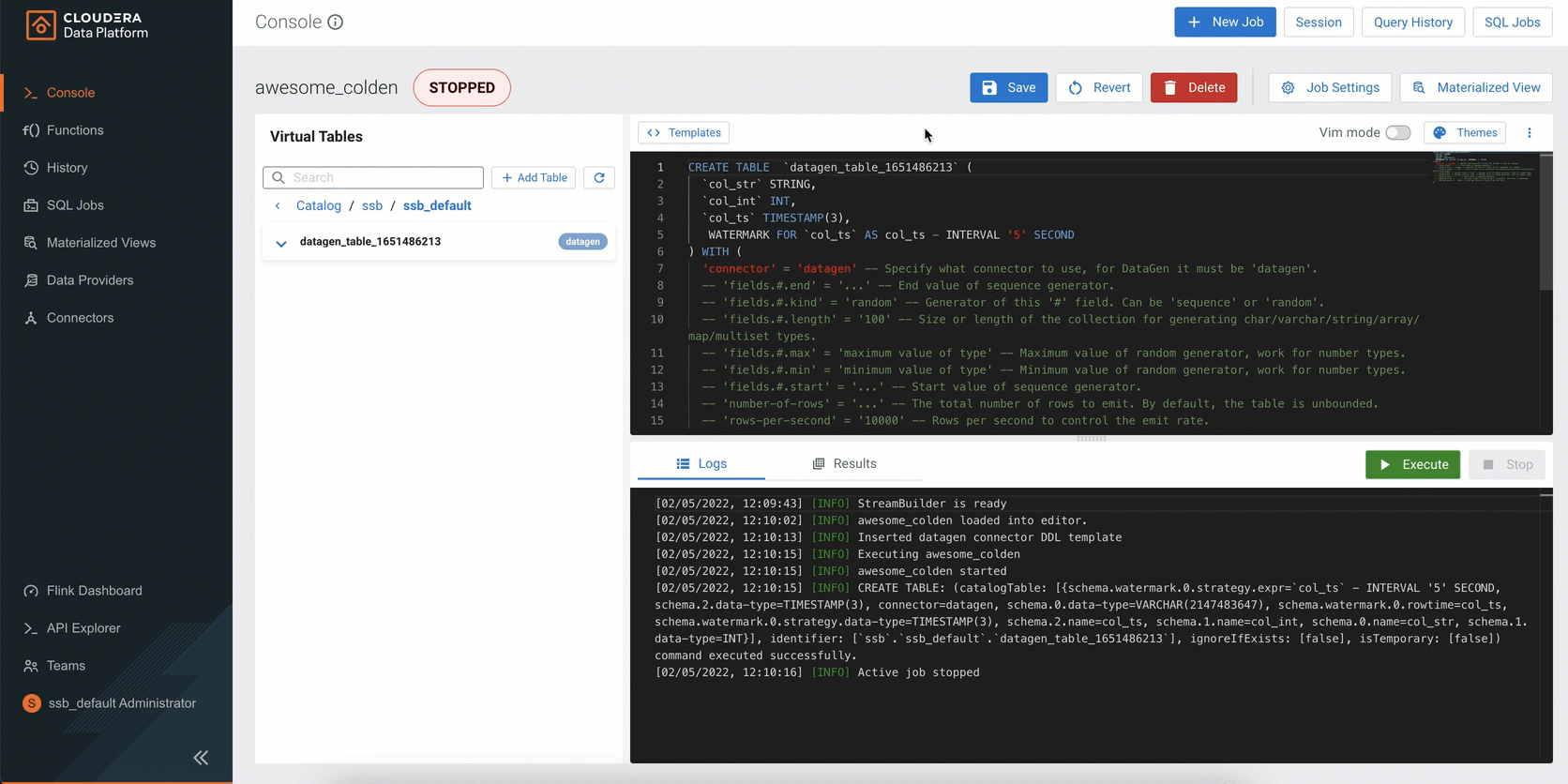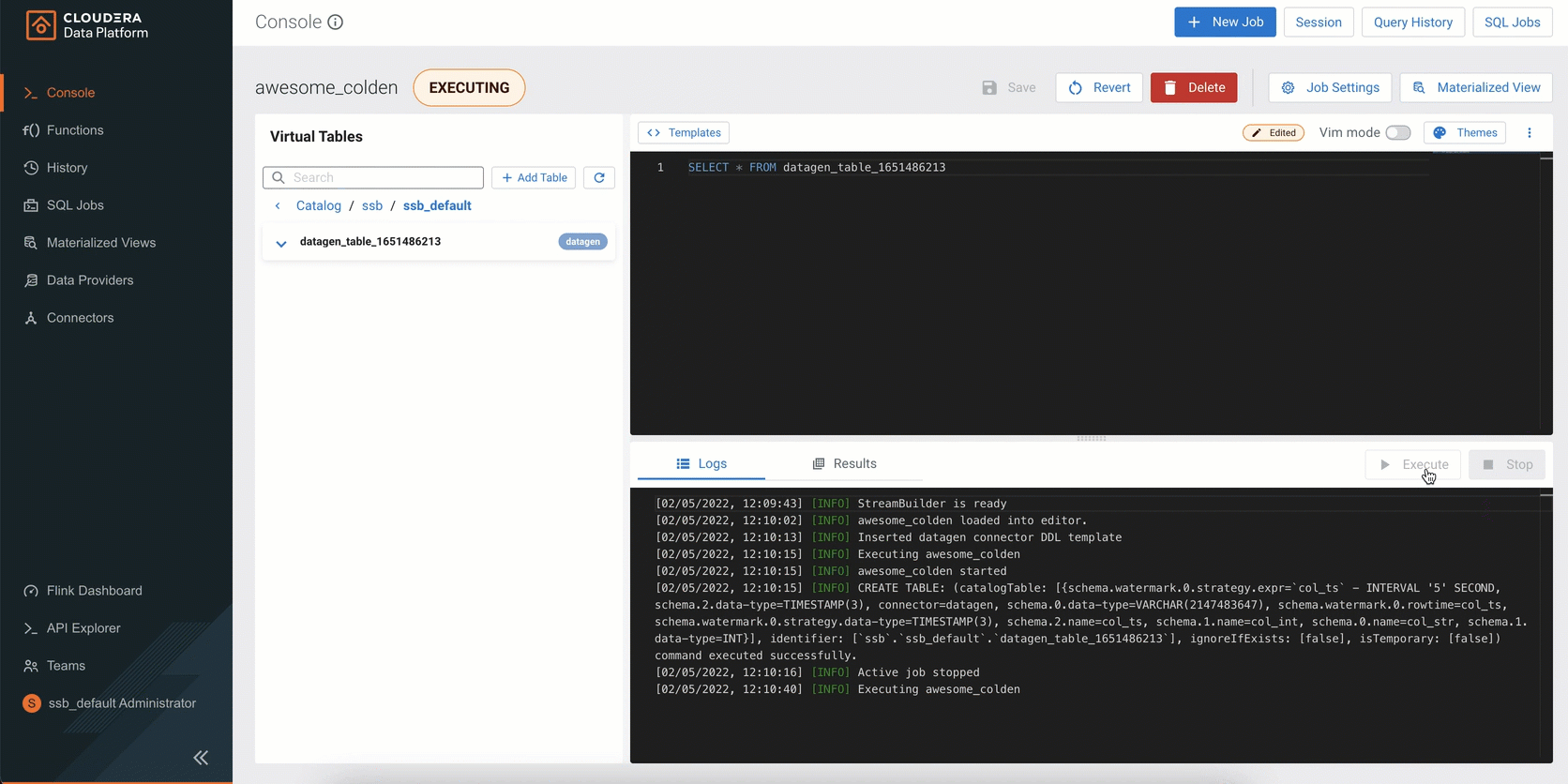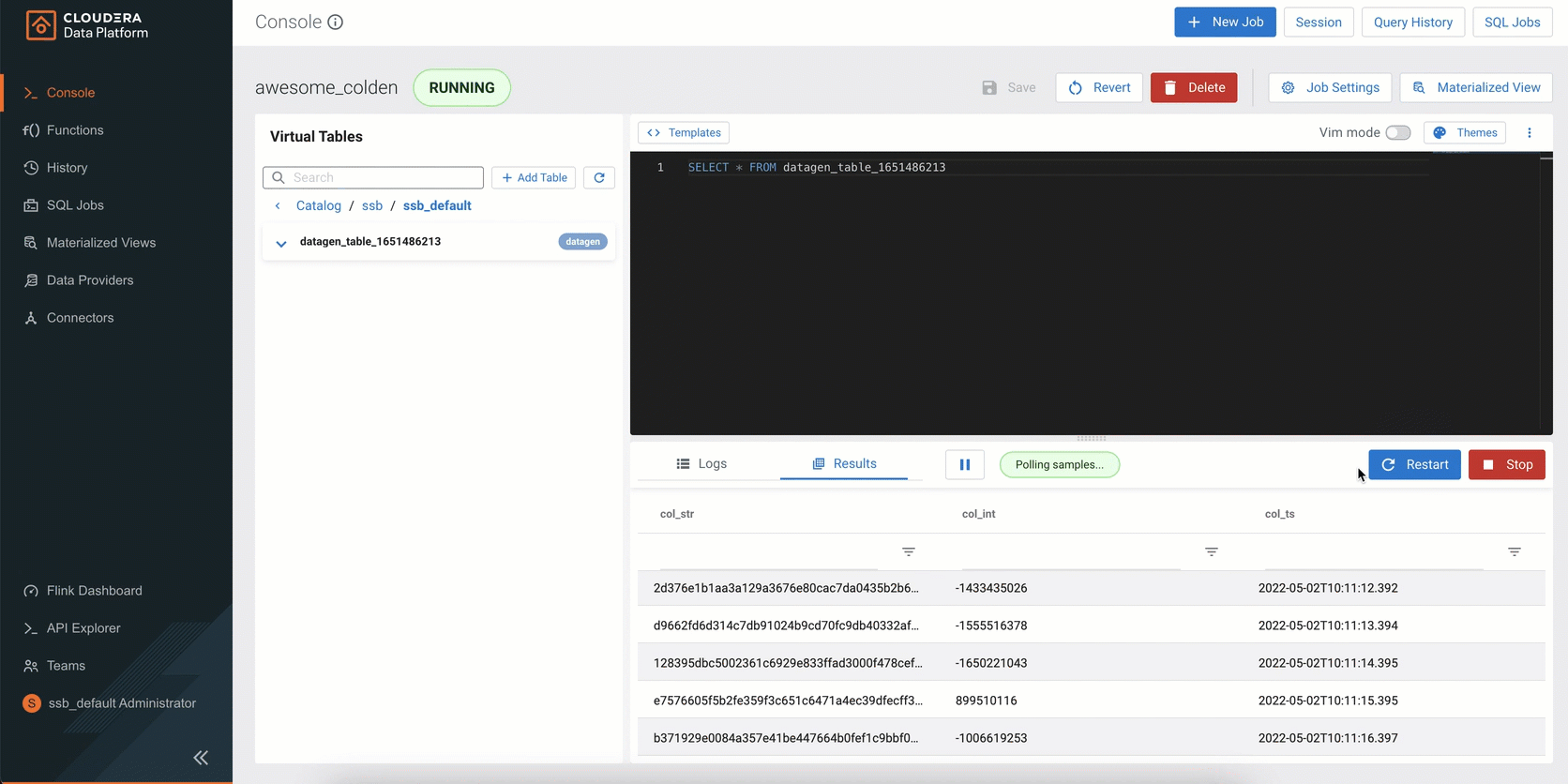
Figure 5: SQL Stream Builder (SSB) is a comprehensive interactive user interface for creating stateful stream processing jobs using SQL.
Convergence of batch and streaming made easy
During a customer workshop, Laila, as a seasoned former DBA, made the following commentary that we often hear from our customers:
“Streaming data has little value unless I can easily integrate, join, and mesh those streams with the other data sources that I have in my warehouse, relational databases and data lake. Without context, streaming data is useless.”
SSB enables users to configure data providers using out of the box connectors or their own connector to any data source. Once the data providers are created, the user can easily create virtual tables using DDL. Complex integration between multiple streams and batch data sources becomes easier like in the example below.
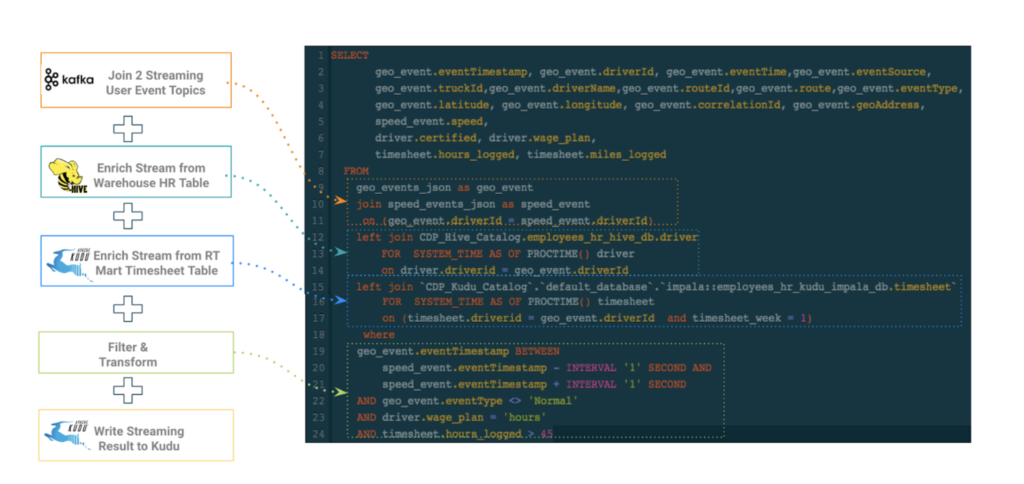
Figure 6: Convergence of streaming and batch: with SQL Stream Builder (SSB), users can easily create virtual tables for streaming and batch data sources, and then use SQL to declare expressions that filter, aggregate, route, and mutate streams of data.
Another common need from our users is to make it simple to serve up the results of the streaming analytics pipeline into the data products they are creating. These data products can be web applications, dashboards, alerting systems, or even data science notebooks.
SSB can materialize the results from a streaming SQL query to a persistent view of the data that can be read via a REST API. This highly consumable dataset is called a materialized view (MV), and BI tools and applications can use the MV REST endpoint to query streams of data without a dependency on other systems. The combination of Kafka as the storage streaming substrate, Flink as the core in-stream processing engine, SQL to build data applications faster, and MVs to make the streaming results universally consumable enables hybrid streaming data pipelines described below.
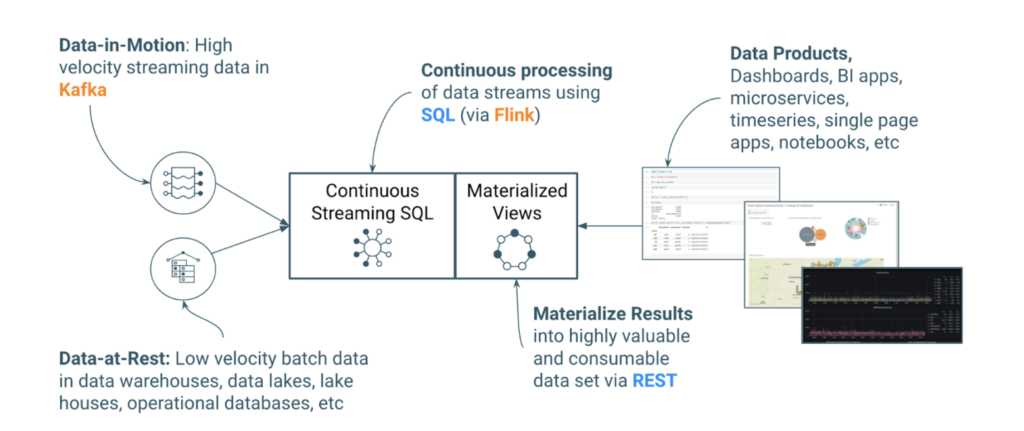
Figure 7: Cloudera Stream Processing (CSP) enables users to create end-to-end hybrid streaming data pipelines.
So did we make Laila successful? Once Laila started using SSB, she quickly utilized her SQL skills to parse and process complex streams of telemetry metadata from Kafka with contextual information from their manufacturing data lakes in their data center and in the cloud to create a hybrid streaming pipeline. She then used a materialized view to create a dashboard in Grafana that provided a real-time view of capacity planning needs at the manufacturing site.
In subsequent blogs, we’ll deep dive into use cases across a number of verticals and discuss how they were implemented using CSP.
Conclusion
Cloudera Stream Processing has evolved from enabling real-time ingestion into lakes to providing complex in-stream analytics, all while making it accessible for the Lailas of the world. As Laila so accurately put it, “without context, streaming data is useless.” With the help of CSP, you can ensure your data pipelines connect across data sources to consider real-time streaming data within the context of your data that lives across your data warehouses, lakes, lake houses, operational databases, and so on. Better yet, it works in any cloud environment. Relying on the industry standard SQL, you can be confident that your existing resources have the know-how to deploy CSP successfully.
Not in the manufacturing space? Not to worry. In subsequent blogs, we’ll deep dive into use cases across a number of verticals and discuss how they were implemented using CSP.
Getting started today
Cloudera Stream Processing is available to run on your private cloud or in the public cloud on AWS, Azure, and GCP. Check out our new Cloudera Stream Processing interactive product tour to create an end to end hybrid streaming data pipeline on AWS.
What’s the fastest way to learn more about Cloudera Stream Processing and take it for a spin? First, visit our new Cloudera Stream Processing home page. Then download the Cloudera Stream Processing Community Edition on your desktop or development node, and within five minutes, deploy your first streaming pipeline and experience your a-ha moment.
Editor's Choice

