

Introduction
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Even though that approach addressed the short-term need of moving to the cloud, it has had three significant disadvantages:
- First, it doesn’t fully (or, in most instances, at all) leverage the elastic capabilities of the cloud deployment model, i.e., the ability to scale up and down compute resources
- Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store
- Finally, IaaS deployments required substantial manual effort for configuration and ongoing management that, in a way, accentuated the complexities that clients faced deploying legacy Hadoop implementations in the data center
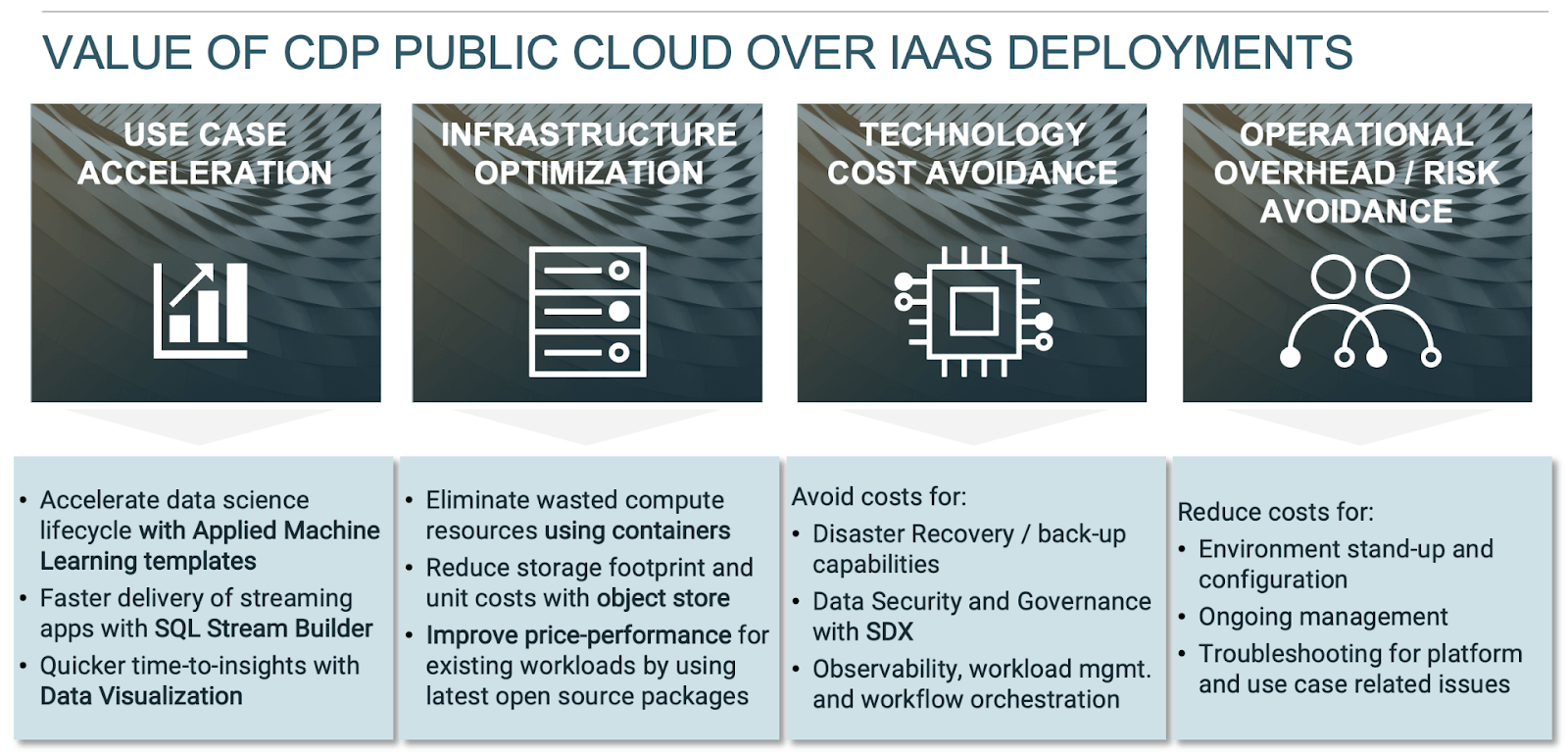
The intent of this article is to articulate and quantify the value proposition of CDP Public Cloud versus legacy IaaS deployments and illustrate why Cloudera technology is the ideal cloud platform to migrate big data workloads off of IaaS deployments. The framework that I built for that comparison includes three dimensions:
- Technology cost rationalization by converting a fixed, cost structure associated with Cloudera subscription costs per node into a variable cost model based on actual consumption
- Infrastructure cost optimization by enabling container-based scalability for compute resources based on processing load and by leveraging object storage that has lower price point than compute-attached storage
- Operational efficiency and risk reduction by automating most of the manual upgrade and configuration tasks being implemented manually in IaaS deployments
Technology and infrastructure costs
Cloudera subscription and compute costs
I will be addressing the first two value drivers of CDP Public Cloud together, as, for the most part, they are tied to the same underlying technology capability of our cloud native platform, that of compute elasticity. CDP Public Cloud leverages the elastic nature of the cloud hosting model to align spend on Cloudera subscription (measured in Cloudera Consumption Units or CCUs) with actual usage of the platform. That is accomplished by delivering most technical use cases through a primarily container-based CDP services (CDP services offer a distinct environment for separate technical use cases e.g., data streaming, data engineering, data warehousing etc.) that optimizes autoscaling for compute resources compared to the efficiency of VM-based scaling.
As a result, CDP Public Cloud helps clients reduce their technology and compute resource cost by:
- Offering a usage-based pricing model based on Cloud Consumption Units (CCUs) that is driven by actual usage of the platform
- Dynamically invoking compute resources based on parameters such as query concurrency (for Data Warehousing using cases), fluctuations in ingested IoT volumes (streaming use cases) and releasing them automatically as usage winds down
The result is to align cost with business value, irrespective of the technical use case deployed onto CDP. The range of savings for clients that move from a fixed, IaaS-oriented cost structure to usage-based pricing differ based on a host of factors that include the actual environment utilization (i.e., usage observed throughout the day for a use case), type of instances used (instance class and type) and region. To provide a comprehensive view of the savings opportunity across all (applicable to CDP) permutations of the parameters mentioned above for both AWS and Azure deployments (e.g., including 23 regions times 135 instance types in the case of AWS), I conducted a simulation / sensitivity analysis, calculating savings for different utilization scenarios shown in the graphs below:
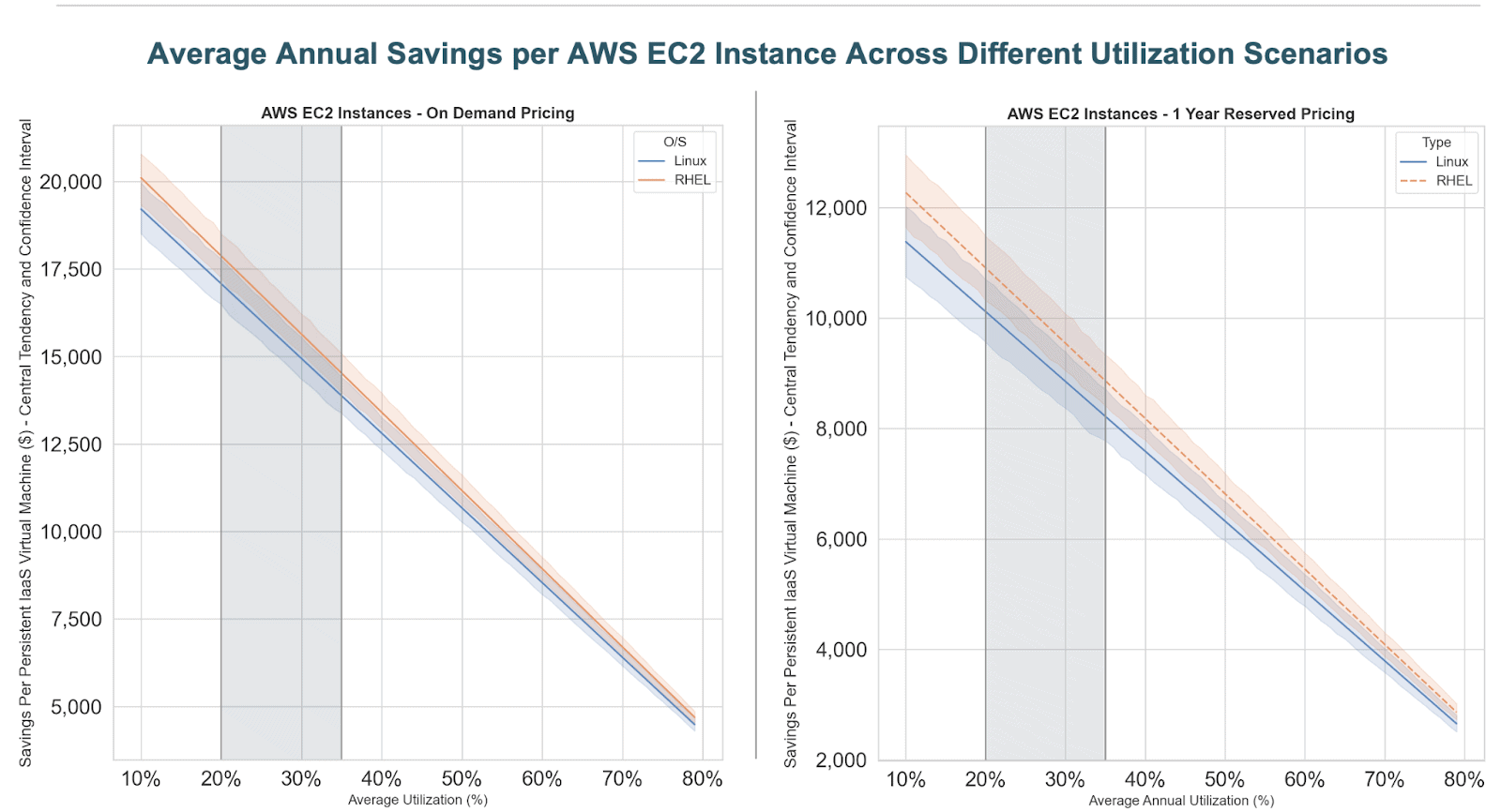
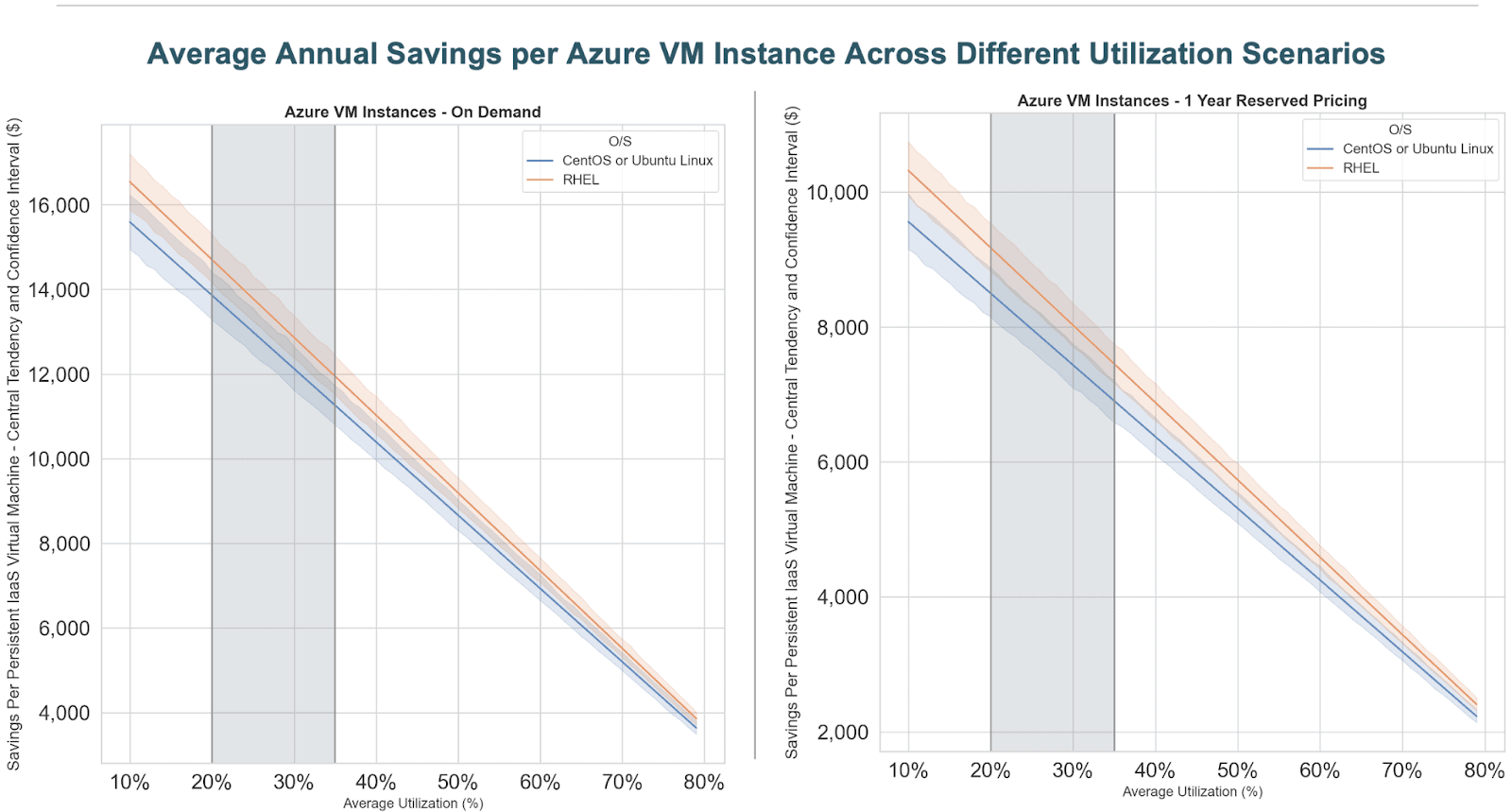
The horizontal axis on each chart reflects different scenarios for the actual utilization of the environment, and the vertical axis corresponds to the annual savings that could be realized per virtual machine were the workload to become optimally elastic, against a baseline where the IaaS instance runs persistently. To simplify the output by means of statistical summarization, I have plotted the arithmetic mean (solid line) for RHEL and Linux operating systems and the 95% confidence interval (shaded area surrounding each solid line) for each utilization scenario and O/S type. The light grey area between the 20-35% utilization range highlights empirical utilization scenarios most commonly observed in client environments and gives a good indication about the savings potential. To further distill the analysis above, the maximum cloud infrastructure savings by moving a persistent IaaS instance to the cloud within the context of a typical utilization range should fall in the following range (amounts in USD):
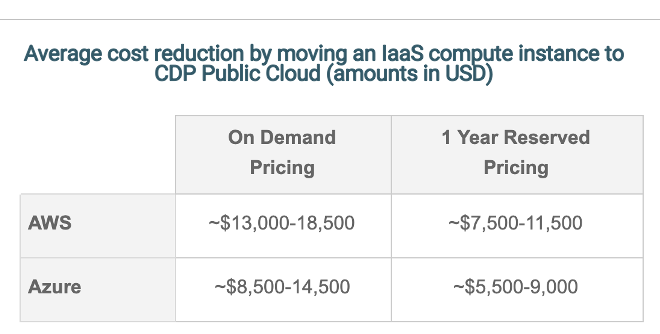
To put these savings into perspective, even a modest $1,000 reduction in compute costs for an existing IaaS node corresponds to ~1,400 data warehousing cloudera credits! (using list pricing of $0.72/hour for a r5d.4xlarge instance type on AWS or E16 v3 instance type on Azure)
Storage costs
CDP Public Cloud yields substantial savings in the case of storage as well, due to:
- Consolidation of storage within clusters according to the HDFS replication factor (typically 3x) by leveraging object storage instead of VM-attached storage
- Consolidation of storage across clusters that is commensurate with the duplication of data stored in different IaaS clusters. That is accomplished by leveraging the SDX layer that exposes a unified data layer to all clusters
- Reduction in marginal storage costs (i.e., $ / GB / month) because unit costs for object storage are typically substantially lower compared to unit costs for VM-attached storage
Using AWS as an example, the box plot graphs below show the typical, percent reduction opportunity in unit storage costs (per GB) by comparing the unit cost of the CDP object store (in S3) against different VM-attached storage types that our clients have been using in IaaS deployments:
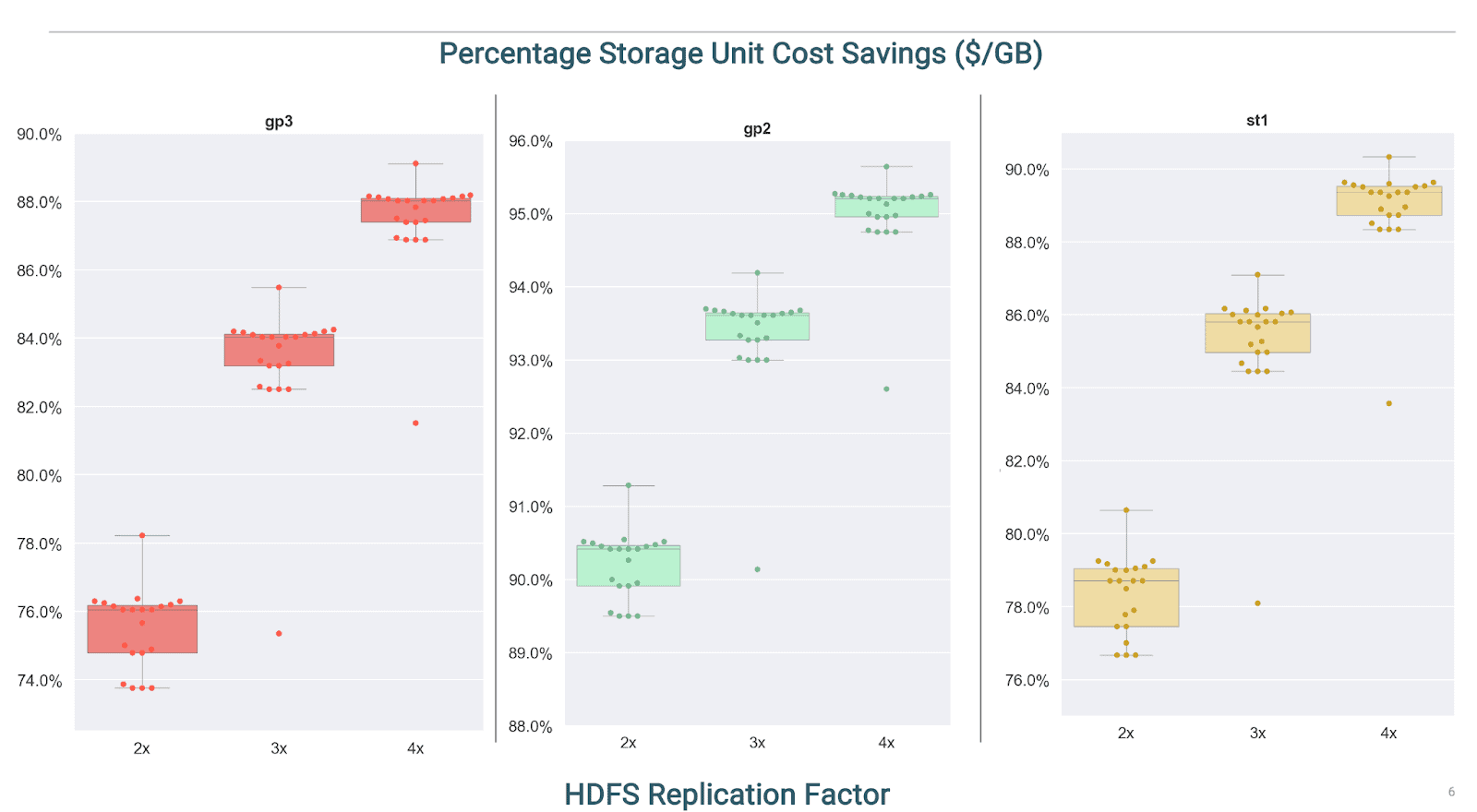
As we can see from the graphs above, for 3x HDFS replication factor, clients should expect to see ~82%-94% savings on a GB basis assuming conversion of the entire storage footprint to S3 (the dots in the charts represent % difference in specific regions by storage type, whereas the boxes are the statistical representation of their quartiles across regions). The analysis excludes residual compute-attached storage that certain services are using for caching (e.g., Data Warehousing, Operational Database) and will remain in the target state environment.
The case of backup and disaster recovery costs
Prior to CDP Public Cloud, clients had to either incur additional costs (e.g., proprietary components from legacy Cloudera or legacy Hortonworks such as BDR or DLM) or consume additional application development and platform management effort (e.g., moving HDFS data to S3 using DistCp for basic data backups) for data lifecycle management capabilities. On the other hand, CDP Public Cloud offers that capability natively without incurring additional costs:
| Deployment Type | Technology Component for Backup and Disaster Recover | Cost (in USD) |
| CDH on IaaS |
|
~$10K / Node / Year (BDR pricing) |
| HDP on IaaS |
|
~$200 /TB/Yr (DLM pricing) |
| CDP Public Cloud (PaaS) |
|
None |
Additional capabilities introduced with CDP Public Cloud
CDP Public isn’t just the “superset” of capabilities that existed in legacy CDH and HDP technologies. It comes with additional components directly addressing higher-order needs for improved performance and data democratization. The table below summarizes technology differentiators over legacy CDH and HDP capabilities:
| Capability | CDH IaaS | HDP IaaS | CDP Public Cloud |
| Fine-grained Data Access Control | Limited granularity with Sentry | Apache Ranger (part of HDP and HDF) | Apache Ranger (part of SDX) |
| Data Visualization | Not Available | Not Available | Data Visualization |
| Workload Management | Available at an extra cost with WXM | Not available, requires additional tool | Workload Management |
| Multi-Cloud Management | Single-cloud visibility with Cloudera Manager | Single-cloud visibility with Ambari | SDX and Cloudera Control Plane |
| Policy-Driven Cloud Storage Permissions | Not available | Not available | Ranger Remote Auth. or RAZ (SDX) |
| SQL-driven Streaming App Development | Not available | Not available | SQL Stream Builder (part of CDF) |
| Machine Learning Prototypes | Not available in legacy CDSW SKU | Not available | Applied ML Prototypes (CML) |
| Workflow Orchestration | Not available | Not available | Managed Airflow (part of CDE) |
| Flow Management | Not available | Apache NiFi (part of HDF) | Apache NiFi (part of CDF) |
Quantifiable improvements to Apache open source projects
In addition to the differences presented above, the CDP runtime includes the latest version of open source projects that deliver data lifecycle stages. Many times, the version supported by CDP delivers superior performance compared to the respective versions included in a legacy CDH or HDP distribution. While real-life performance differences (and corresponding cost savings) will depend on the nature of workloads (e.g., specific type and complexity of SparkSQL queries) and overall performance tuning, the resulting financial benefits will be most certainly material. For example, Spark 3.x that is included in CDP, was found to be ~2x faster than Spark 2.4 in TCP-DS 30TB benchmarks
Operational efficiency
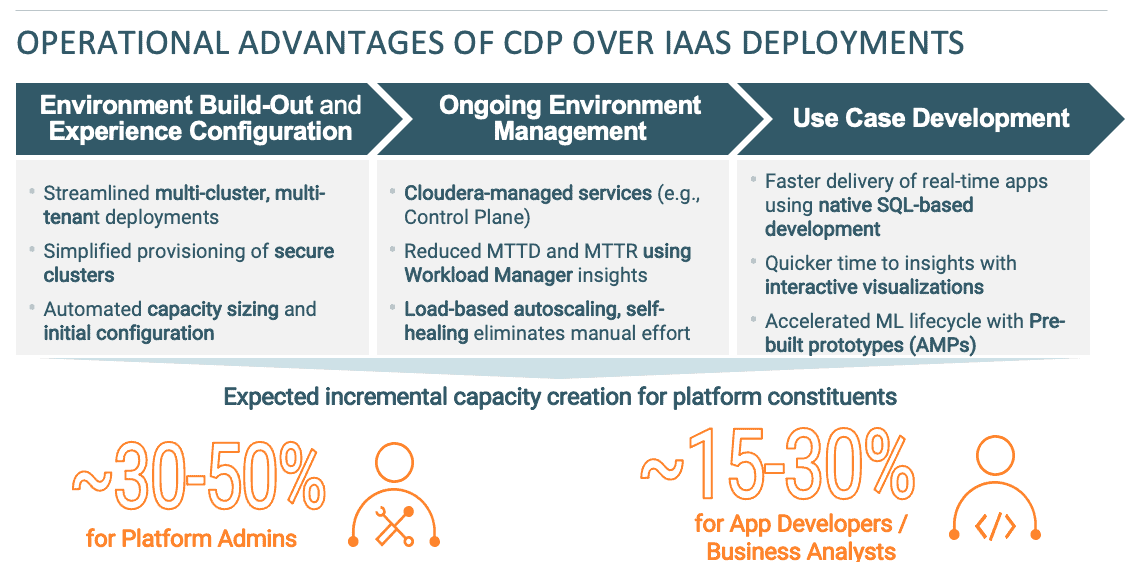
The greatest improvement that CDP Public Cloud delivers over IaaS deployments lies in the operational domain and impacts activities that span across the entire platform lifecycle from environment build-out to experience configuration, tuning and ongoing management. The numerous operational improvements with CDP Public Cloud over Hadoop IaaS deployments can be organized into the following categories:
A. Environment Build-Out: CDP Public Cloud automates a lot of previously manual, risk-intensive activities related to initial platform build-out activities. As an example:
- Configuring secure clusters has been greatly simplified through UI-based provisioning of “secure by default” clusters instead of compiling scripts for each cluster, similar to IaaS deployments. That, by itself will deliver substantial operational improvements in multi-cluster settings, where previously Hadoop admins had to arrive at complex architectural decisions when it comes to establishing trust between servers (multi-KDC or central KDC approach), managing token delegation etc.
- The Shared Data Experience (SDX), an integral part of CDP Public Cloud, simplifies deployment of multi-cluster environments and delivers a unified data and metadata integration fabric across disparate clusters, thus eliminating duplication of tasks
B. Experience configuration / use case deployment: At the data lifecycle experience level (e.g., data streaming, data engineering, data warehousing etc.), CDP has simplified all tasks related to configuring and provisioning multi-tenant environments that deliver enterprise-grade performance and scalability capabilities such as resource isolation, autosuspend, automated load-based scalability etc. As an example, when deploying a user environment, Cloudera Data Warehouse handles all software pre-configuration tasks, creating the different caching layers etc. As a result, you don’t need to engage in complex capacity planning or tuning for the Data Warehouse service similar to configuring IaaS deployments
C. Ongoing management. Finally, CDP reduces effort for several ongoing platform and end-user operations such as:
- Operation of many foundational services, as, Cloudera is responsible (under the Shared Responsibility Model) for the provisioning and availability of several services such as the Control Plane, allowing platform teams to focus on value-add activities
- Use case tuning and troubleshooting through Workload Manager which offers granular insights into the performance of individual units of work e.g., data warehousing queries or data engineering pipelines, ultimately enabling platform users to streamline issue resolution
D. Use Case Development: When it comes to use case development, Cloudera has enhanced different data lifecycle services with the additional technology capabilities as I presented above. Those capabilities will help accelerate the lifecycle for developing applications, as an example:
- Applied Machine Learning Prototypes (or AMPs) enable Cloudera Machine Learning users to accelerate development lifecycle by starting off with a full, end-to-end project developed for a similar use case
- SQL Stream Builder reduces time to develop streaming use cases using Cloudera Data Flow, by offering a familiar SQL-based query language (Continuous SQL)
Conclusion
Compared to IaaS deployments, CDP Public Cloud represents a paradigm shift for deploying big data use cases in the public cloud. Organizations that were previously using archaic IaaS deployment models and have now moved to CDP Public Cloud, didn’t just see a marked reduction in technology and cloud infrastructure spend, but empowered data engineers, application developers and data scientists with a streamlined capability to manage the use case lifecycle:
Cloudera’s Value Management team can help you quantify the value of migrating your IaaS environments to CDP Public Cloud.
Acknowledgment
I would like to thank Mike Forrest who helped with the arduous task of collecting AWS and Azure pricing metrics
Editor's Choice

