

Introduction
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. This year, we expanded our partnership with NVIDIA, enabling your data teams to dramatically speed up compute processes for data engineering and data science workloads with no code changes using RAPIDS AI. RAPIDS on the Cloudera Data Platform comes pre-configured with all the necessary libraries and dependencies to bring the power of RAPIDS to your projects.
What is RAPIDS
RAPIDS brings the power of GPU compute to standard Data Science operations, be it exploratory data analysis, feature engineering or model building. For more information see: <https://rapids.ai/> The RAPIDS libraries are designed as drop-in replacements for common Python data science libraries like pandas (cuDF), numpy (cuPy), sklearn (cuML) and dask (dask_cuda). By leveraging the parallel compute capacity of GPUs the time for complicated data engineering and data science tasks can be dramatically reduced, accelerating the timeframes for Data Scientists to take ideas from concept to production.
Scenario
In this tutorial, we will illustrate how RAPIDS can be used to tackle the Kaggle Home Credit Default Risk challenge. The Home Credit Default Risk problem is about predicting the chance that a customer will default on a loan, a common financial services industry problem set. To try and predict this, an extensive dataset including anonymised details on the individual loanee and their historical credit history are included. See <https://www.kaggle.com/c/home-credit-default-risk/overview> for more details.
As a machine learning problem, it is a classification task with tabular data, a perfect fit for RAPIDS.
The focus of this tutorial will be on the mechanics of leveraging the RAPIDS library and not on building the best performing model for the leaderboard. To see more information on the winning submission See: https://www.kaggle.com/c/home-credit-default-risk/discussion/64821
Project Setup
To follow along, clone the repo at: https://github.com/Data-drone/cml_rapids.git into a new CML Project
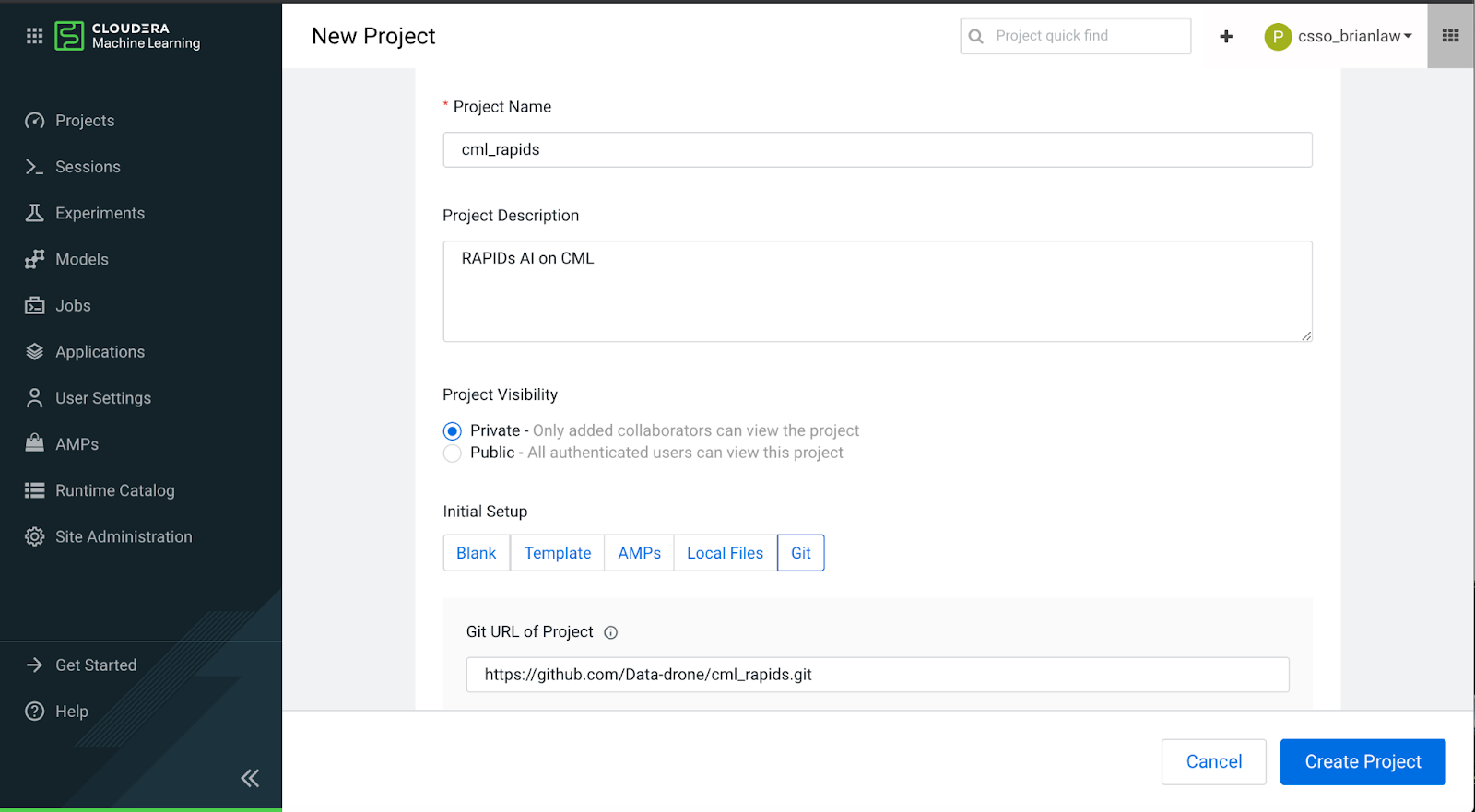
In this example, we will use a Jupyter Notebook session to run our code. Create a session with 8 cores, 16GB memory, and 1 GPU
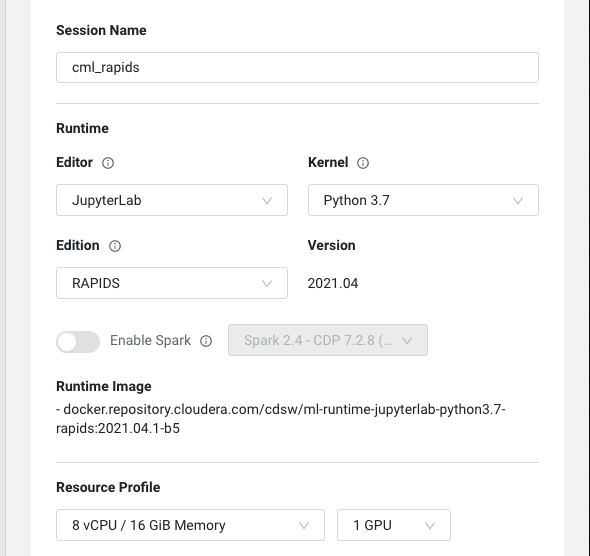
Install the requirements from a terminal session with:
code pip install -r requirements.txt
Get the Dataset
For the code to work, the data in it’s CSV format should be placed into the data subfolder. The dataset can be downloaded from: https://www.kaggle.com/c/home-credit-default-risk/data.
To validate that our image is working and that RAPIDS is correctly configured, run `testing.py` from a terminal session in jupyterlab.
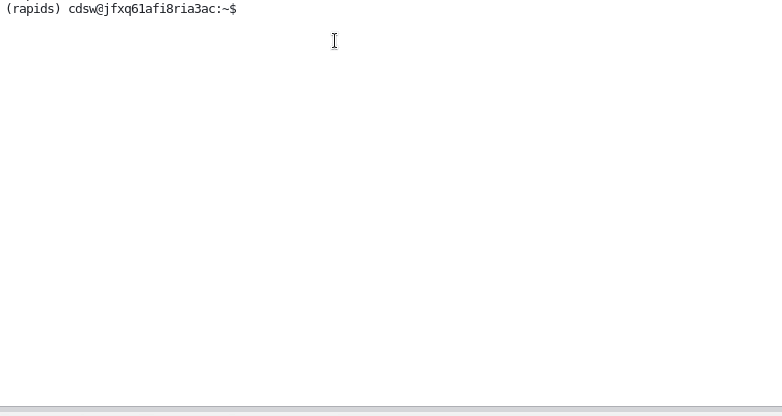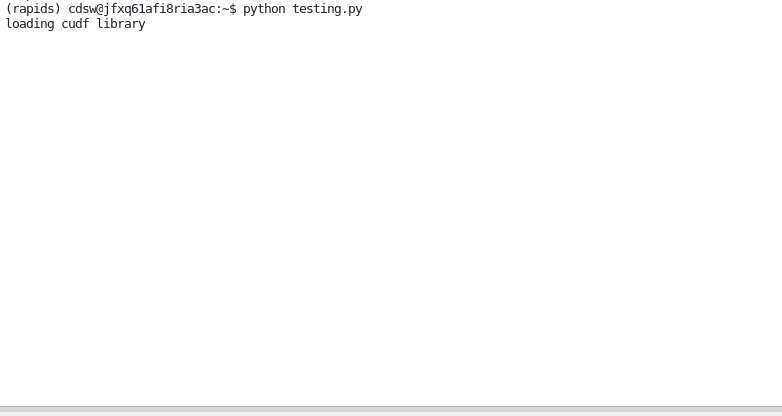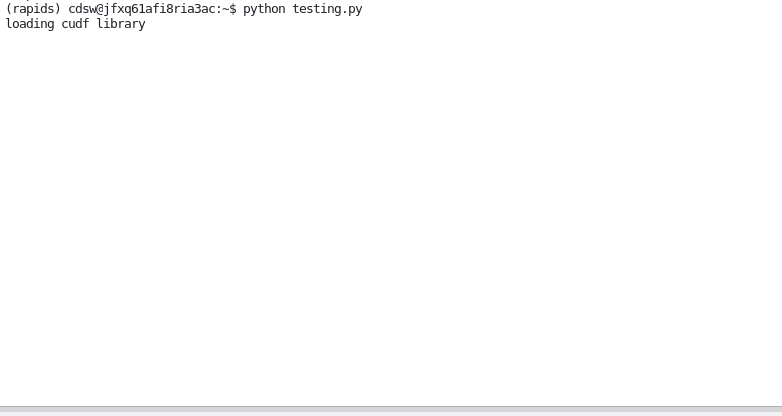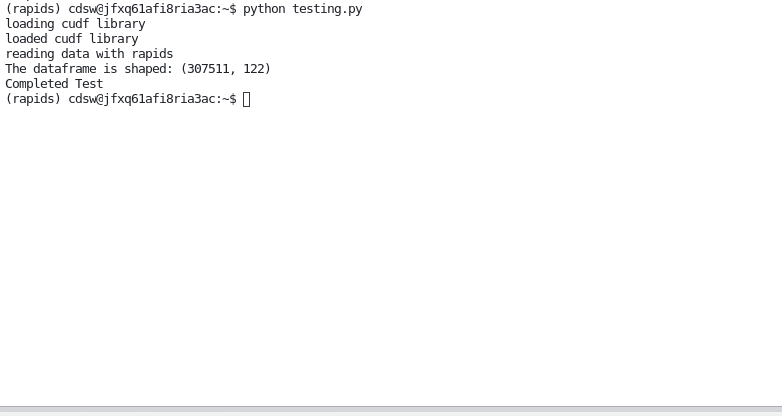
The script will go through loading RAPIDs libraries then leveraging them to load and processing a datafile.
Common problems at this stage can be related to GPU versions. RAPIDS is only supported on Pascal or newer NVIDIA GPUs. For AWS this means at least P3 instances. P2 GPU instances are not supported.
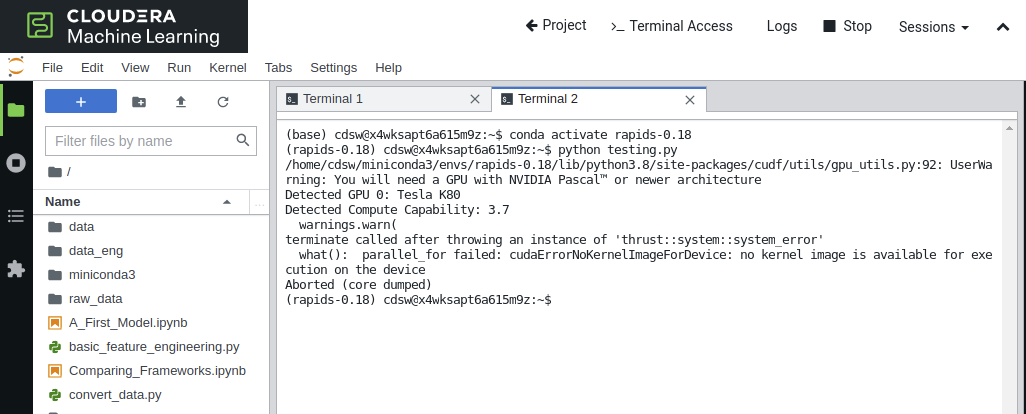
Data Ingestion
The raw data is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files. Parquet also stores type metadata which makes reading back and processing the files later slightly easier.
Run the `convert_data.py` script. This will open the CSVs with correctly data types then save them out as parquet in the `raw_data` folder.
Now we have all our parquet datasets to continue on our RAPIDS journey.
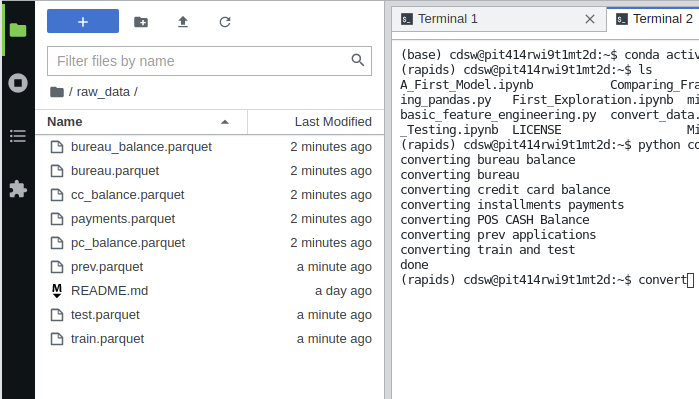
Exploring the dataset, there are numerical columns, categorical and boolean columns. The `application_test` and `application_train` files contain the main features that we will be building our model off of whilst the other tables provide some supplementary data. Feel free to skim through: `First_Exploration.ipynb` in order to see some basic exploration of the datasets.
In the `First_Exploration.ipynb` we also leverage `cuXfilter`, a RAPIDS-accelerated cross filtering visualization library for some of the charts.
Simple Exploration and Model
As with all Machine Learning problems, let’s start with a simple model. This gives us the opportunity to build a baseline to improve off of and also to check that Machine Learning can learn something off the data right off the bat.
Open `A_First_Model.ipynb`
At the start of this notebook, you can choose which set of libraries to load.
The RAPIDS set or the pandas set. Just run one of these cells.
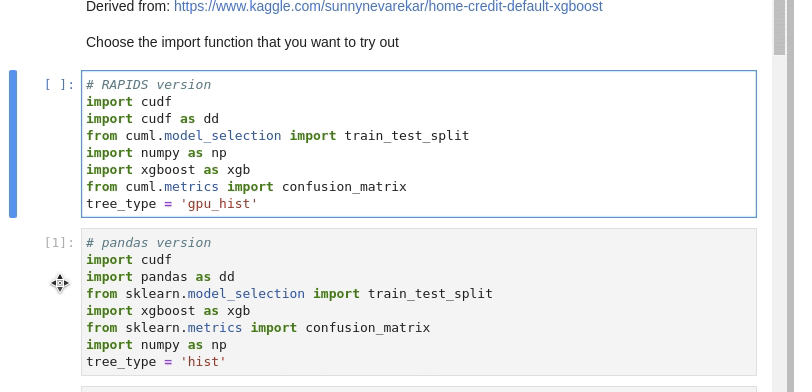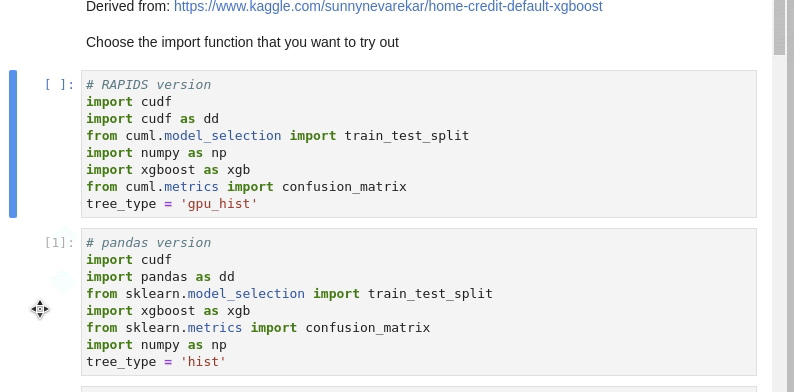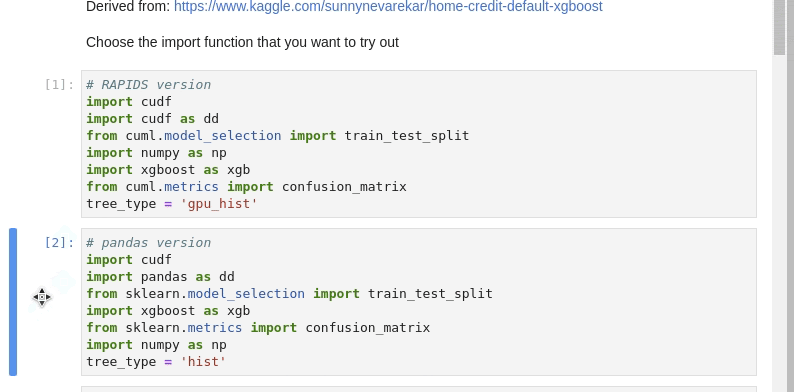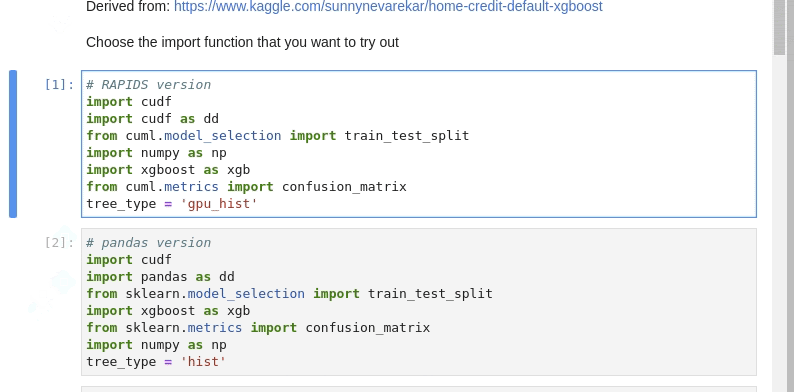
This notebook goes through loading just the train and test datasets.
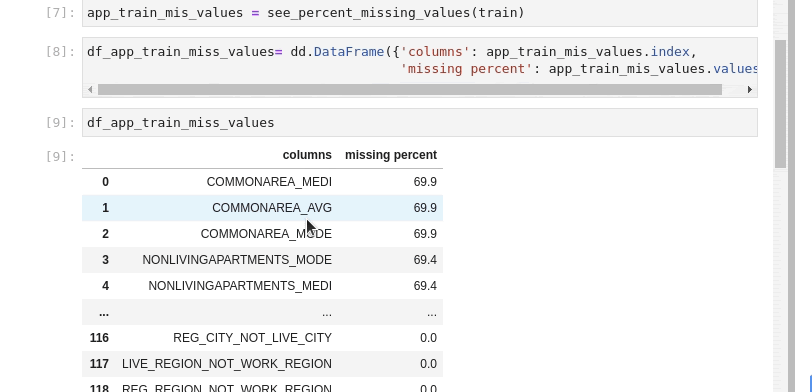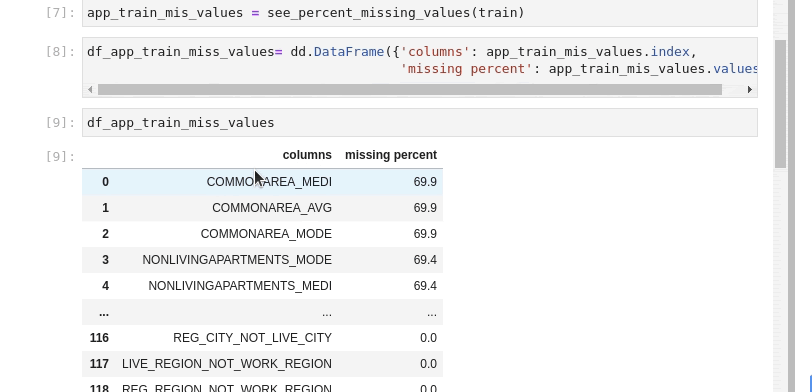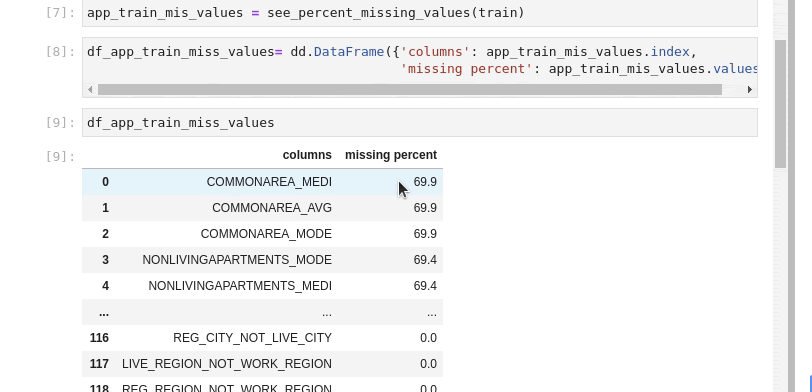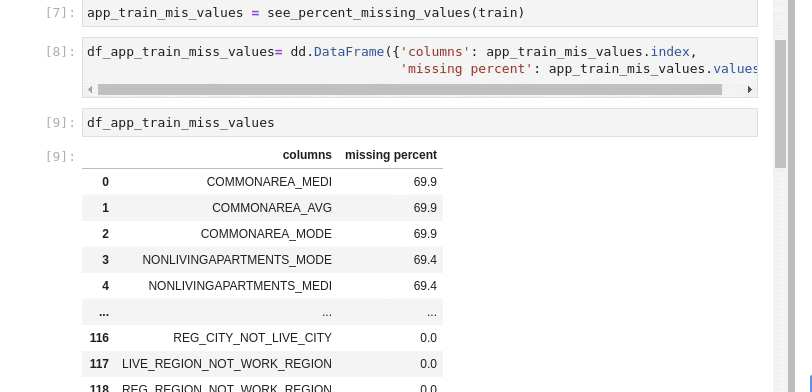
Some simple filtering out of columns with a lot of missing values
It is worth noting that although RAPIDS `cudf` is mostly a drop in replacement for `pandas`, we do need to change some parts to make it work seamlessly.
code block if type(df_app_train_miss_values) == cudf.core.dataframe.DataFrame: drop_columns = df_app_train_miss_values[df_app_train_miss_values['missing percent'] \ >= 40]['columns'].to_arrow().to_pylist() else: drop_columns = df_app_train_miss_values[df_app_train_miss_values['missing percent'] \ >= 40]['columns'].tolist()
The training of the model.
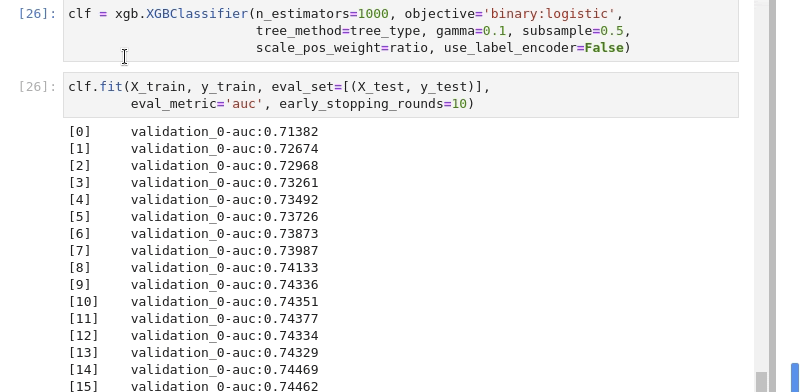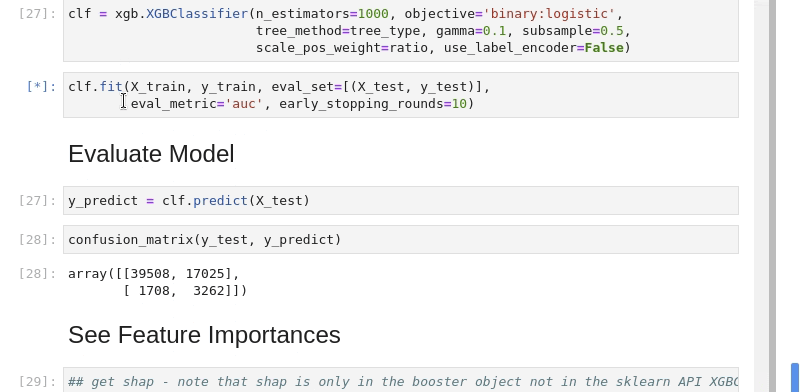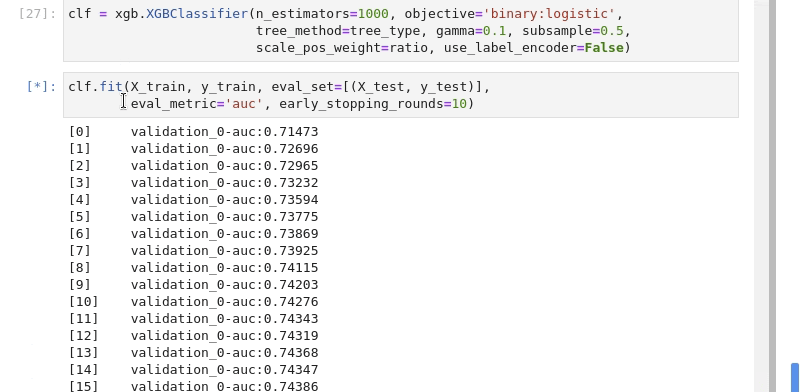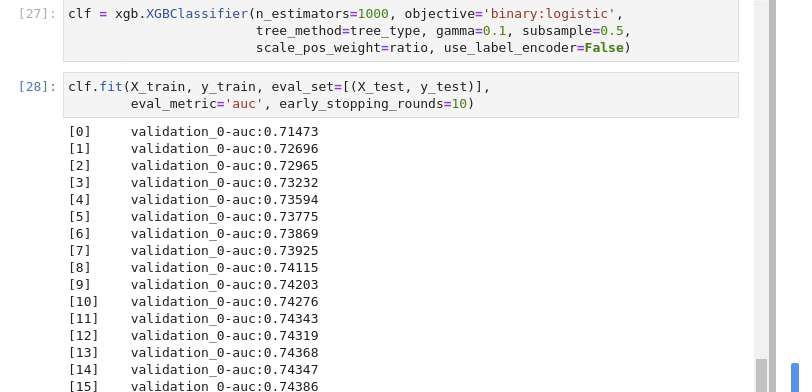
And analysing the results.
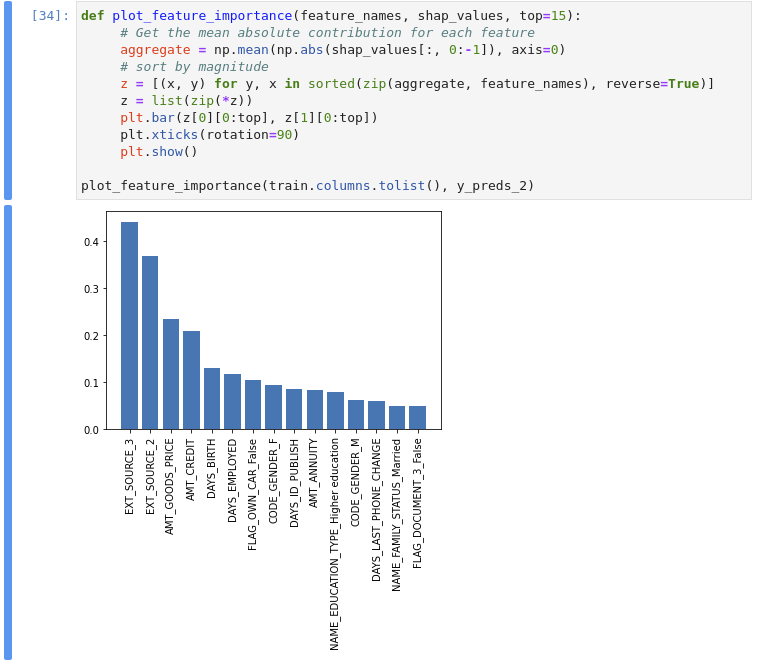
Feature Engineering
Now that we have a feel for how this works, let’s look at a more advanced feature engineering pipeline.
For our simple feature engineering pipeline, we only used the main training table and didn’t look at the other tables in the dataset.
For our advanced feature engineering pipeline, we will include the auxiliary data and also engineering some additional features.
Open the Comparing_Frameworks.ipynb file to see how cuDF and pandas compare.
NOTE: The function for engineering the features have been written to be compatible with Pandas and cuDF and can be found in `feature_engineering_2.py`
The notebook is split into two sections. RAPIDS cuDF and Pandas.
From our testing, we see the following in terms of performance:
| Process | RAPIDS (wall time) | Pandas (wall time) |
| Ingest Data | 1.17 secs | 9.83 secs |
| Generate Features | 8.12 secs | 68.1 secs |
| Write Data | 4.34 secs | 9.8 secs |
* Note your runtimes may vary depending on the cluster hardware setup and session resources. This was based on a P3 Worker with 8 cores and 16GB RAM
We can see that for all parts of the process, RAPIDS offers higher performance than raw Pandas. It is worth noting at this stage, that RAPIDS cuDF can only take advantage of one GPU. Should we wish to scale beyond a single GPU, we will need to leverage `dask_cudf`.
Modelling
For the advanced modelling section, we will again leverage xgboost as our primary method. To enable GPU Acceleration, we set the `tree_method` to `gpu_hist`. That is really all we need to do to leverage GPU compute!

With the Home Credit Default Risk Challenge, overfitting is very easy. So we have included a cross validation step here. In order to use `train_test_split` with RAPIDS cuDF dataframes, we use the `cuml` version instead. cuML, however, doesn’t have `StratifiedKFold` sampling so we will use the `sklearn` version.
`StratifiedKFold` isn’t very computationally expensive however so it doesn’t matter that we aren’t running this on GPU. The resulting indexes can also be used directly with cuDF dataframes via `iloc` as per normal.
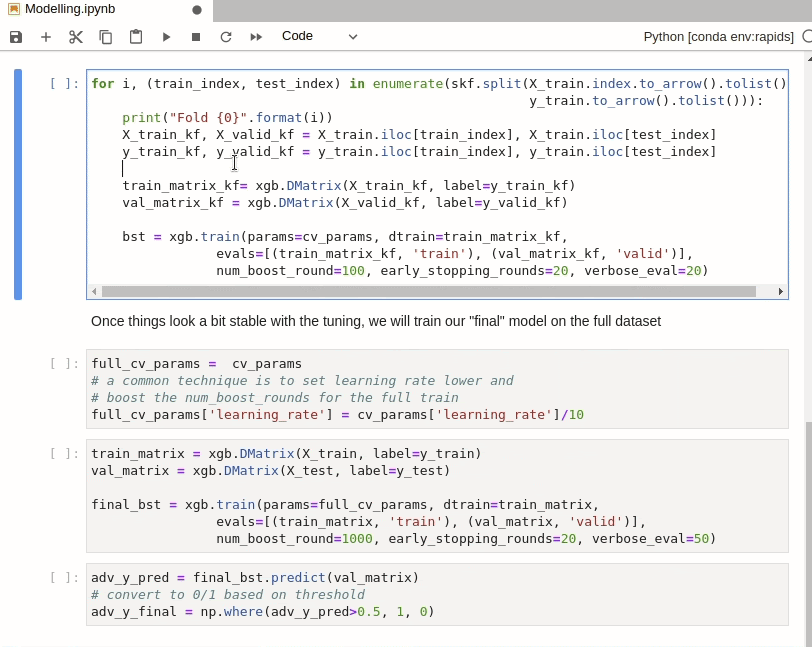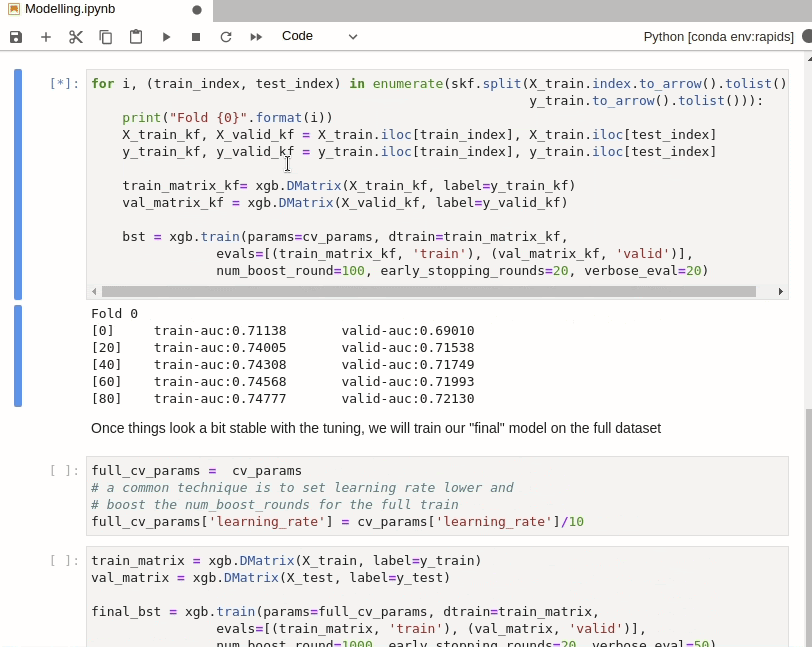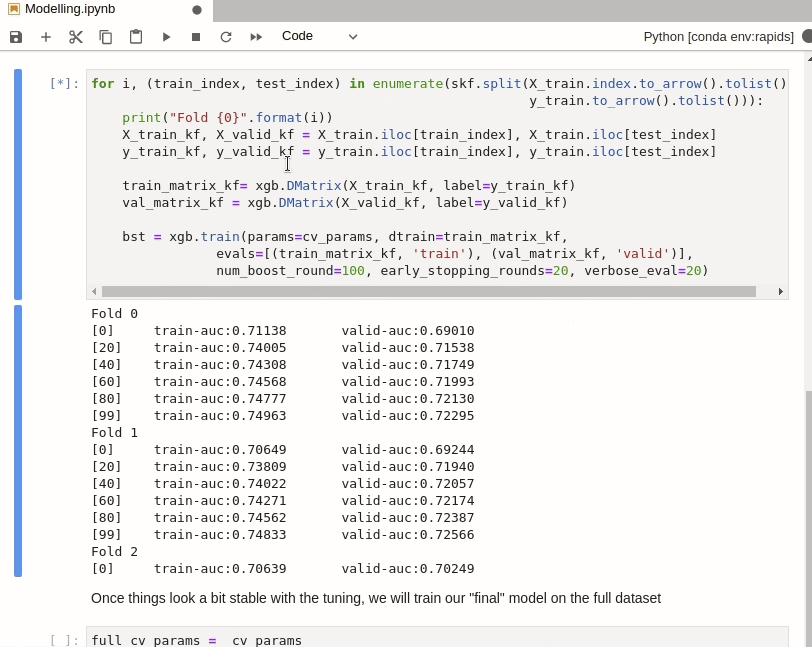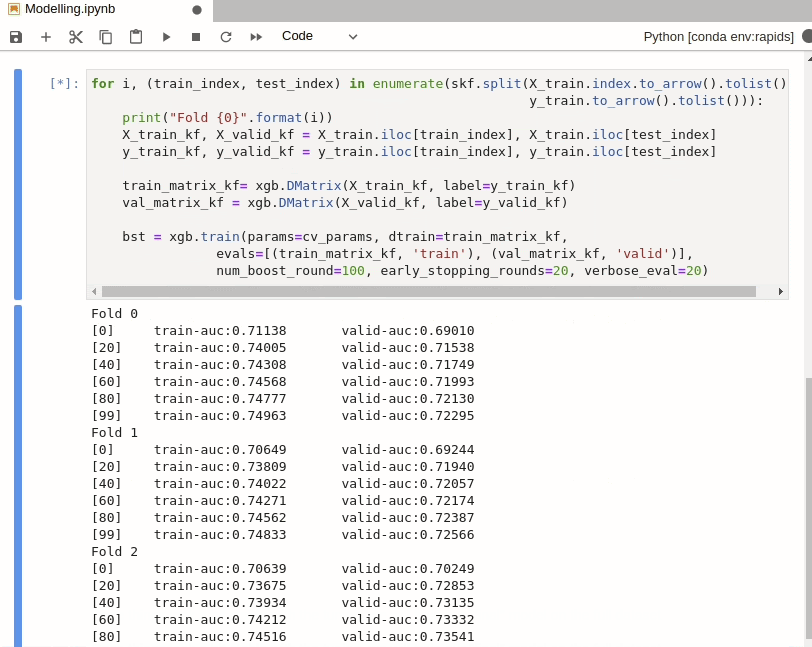
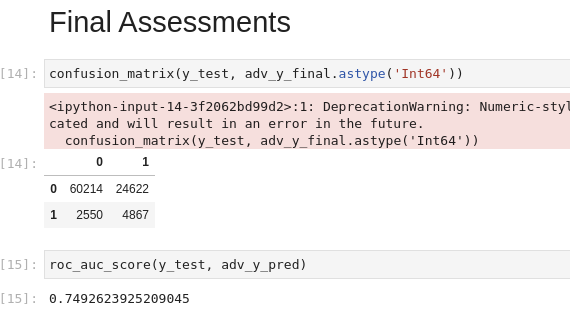
Assessing Models
With our model trained, we can have a look at the confusion matrix and auc scores from our model. Again, we use cuML versions so that we don’t have to transfer the data back to the CPU.
XGBoost also features GPU-accelerated feature importance calculations and SHAP calculations for explainability. For a full explanation of shap values see: https://www.kaggle.com/dansbecker/shap-values
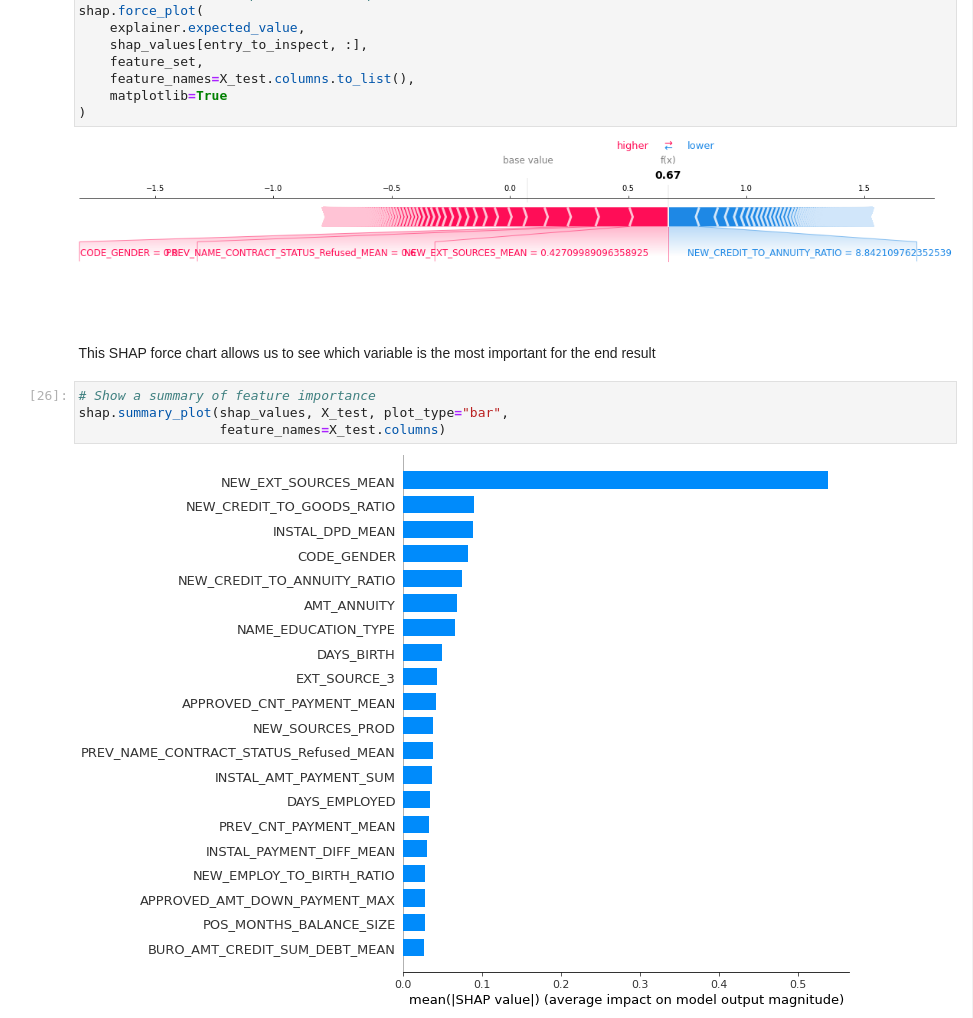
Next Steps
The following post is part 3 of the series, GPUs on CML. If you would like to learn more about how you can leverage RAPIDS to accelerate your Machine Learning Projects in Cloudera Machine Learning, be sure to check out part 1 & part 2 of the blog series.
On June 3, join the NVIDIA and Cloudera teams for our upcoming webinar Enable Faster Big Data Science with NVIDIA GPUs. Register Now.
Editor's Choice

