

For enterprise organizations, managing and operationalizing increasingly complex data across the business has presented a significant challenge for staying competitive in analytic and data science driven markets. With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that data engineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
To tackle these challenges, we’re thrilled to announce CDP Data Engineering (DE), the only cloud-native service purpose-built for enterprise data engineering teams. For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual profiling, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams.
Delivered through the Cloudera Data Platform (CDP) as a managed Apache Spark service on Kubernetes, DE offers unique capabilities to enhance productivity for data engineering workloads:
- Visual GUI-based monitoring, troubleshooting and performance tuning for faster debugging and problem resolution
- Native Apache Airflow and robust APIs for orchestrating and automating job scheduling and delivering complex data pipelines anywhere
- Resource isolation and centralized GUI-based job management
- CDP data lifecycle integration and SDX security and governance
Unlike traditional data engineering workflows that have relied on a patchwork of tools for preparing, operationalizing, and debugging data pipelines, Data Engineering is designed for efficiency and speed — seamlessly integrating and securing data pipelines to any CDP service including Machine Learning, Data Warehouse, Operational Database, or any other analytic tool in your business. Because DE is fully integrated with the Cloudera Shared Data Experience (SDX), every stakeholder across your business gains end-to-end operational visibility, with comprehensive security and governance throughout.
Enterprise Data Engineering From the Ground Up
When building CDP Data Engineering, we first looked at how we could extend and optimize the already robust capabilities of Apache Spark. Spark has become the de-facto processing framework for ETL and ELT workflows for good reason, but for many enterprises working with Spark has been challenging and resource-intensive. Leveraging Kubernetes to fully containerize workloads, DE provides a built-in administration layer that enables one click provisioning of autoscaling resources with guardrails, as well as a comprehensive job management interface for streamlining pipeline delivery.
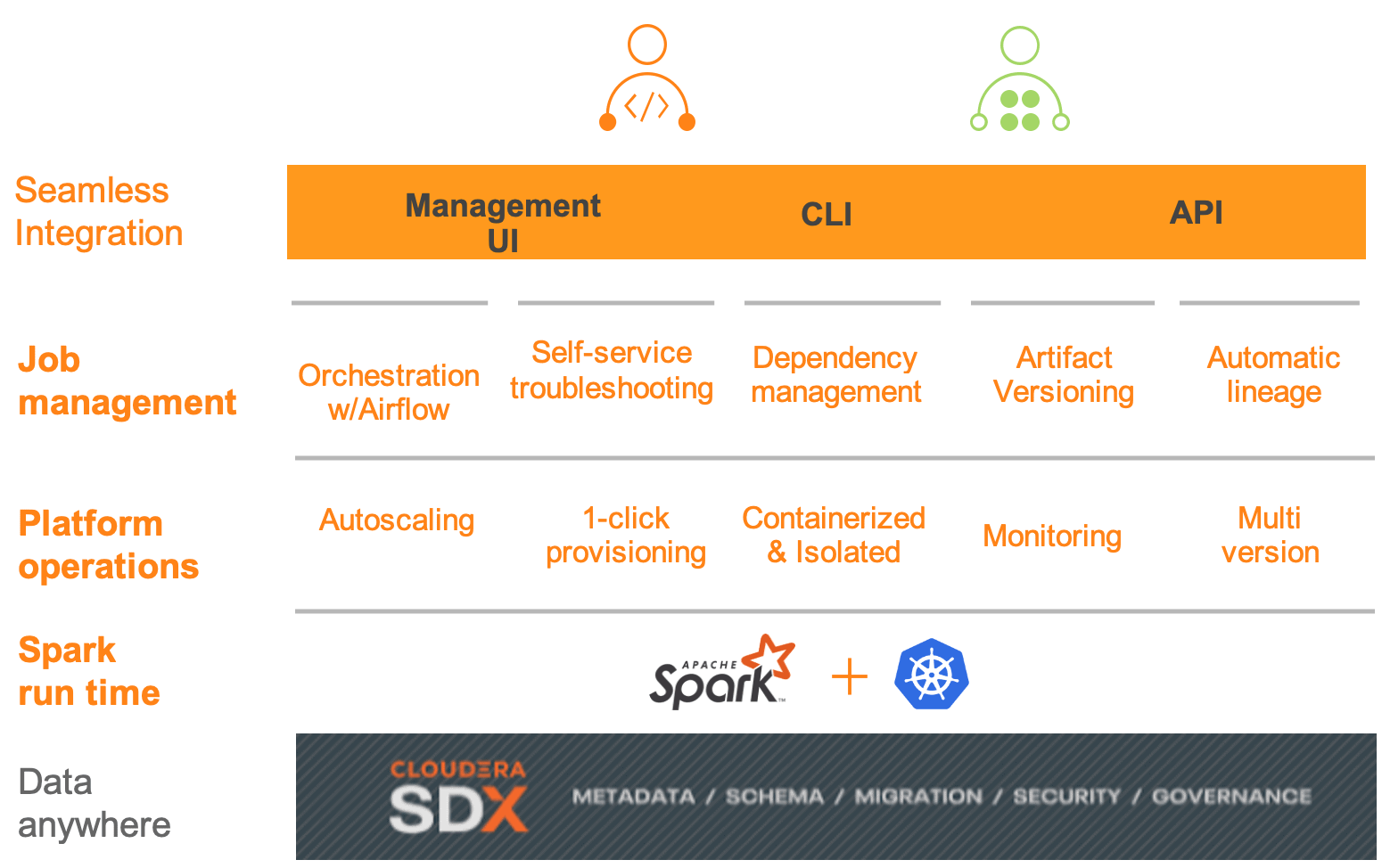
Figure 1: Key component within CDP Data Engineering
DE enables a single pane of glass for managing all aspects of your data pipelines. Let’s take a technical look at what’s included.
A Technical Look at CDP Data Engineering
Managed, Serverless Spark
For the majority of Spark’s existence, the typical deployment model has been within the context of Hadoop clusters with YARN running on VM or physical servers. Alternative deployments have not been as performant due to lack of investment and lagging capabilities. With the advancements in containerization technologies like Kubernetes it is now possible to run Spark on Kubernetes with high performance. But even then it has still required considerable effort to set up, manage, and optimize performance.
For these reasons, customers have shied away from newer deployment models, even though they have considerable value. For example, many enterprise data engineers deploying Spark within the public cloud are looking for ephemeral compute resources that autoscale based on demand. Until now, Cloudera customers using CDP in the public cloud, have had the ability to spin up Data Hub clusters, which provide Hadoop cluster form-factor that can then be used to run ETL jobs using Spark. What we have observed is that the majority of the time the Data Hub clusters are short lived, running for less than 10 hours.
Not only is the ability to scale up and down compute capacity on-demand well suited for containerization based on Kubernetes, they are also portable across cloud providers and hybrid deployments. DE is architected with this in mind, offering a fully managed and robust serverless Spark service for operating data pipelines at scale.
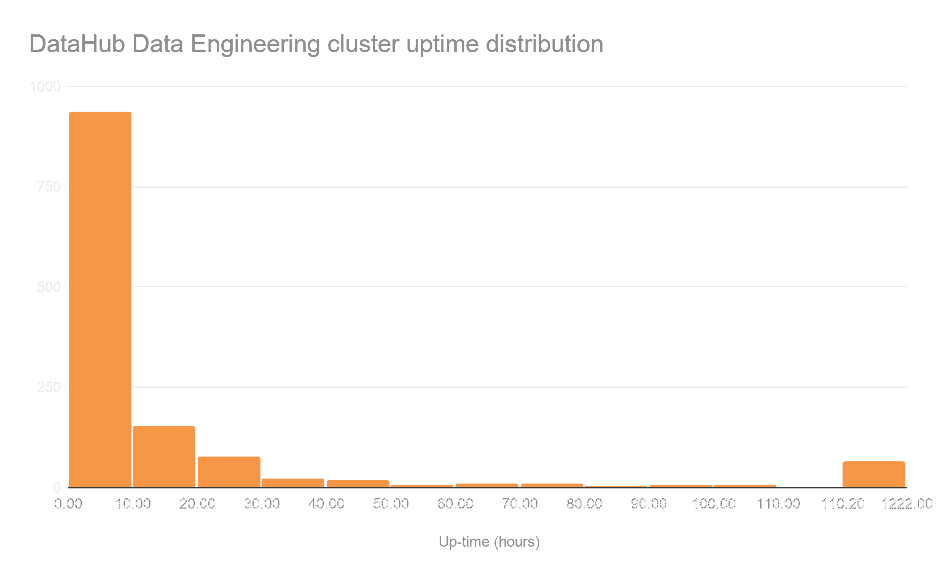
Figure 2: Data Hub clusters within CDP Public Cloud used for Data Engineering are short lived majority running for less than 10 hours.
Job Deployment Made Simple
For a data engineer that has already built their Spark code on their laptop, we have made deployment of jobs one click away. The user can use a simple wizard where they can define all the key configurations of their job.
DE supports Scala, Java, and Python jobs. We have kept the number of fields required to run a job to a minimum, but exposed all the typical configurations data engineers have come to expect: run time arguments, overriding default configurations, including dependencies and resource parameters.
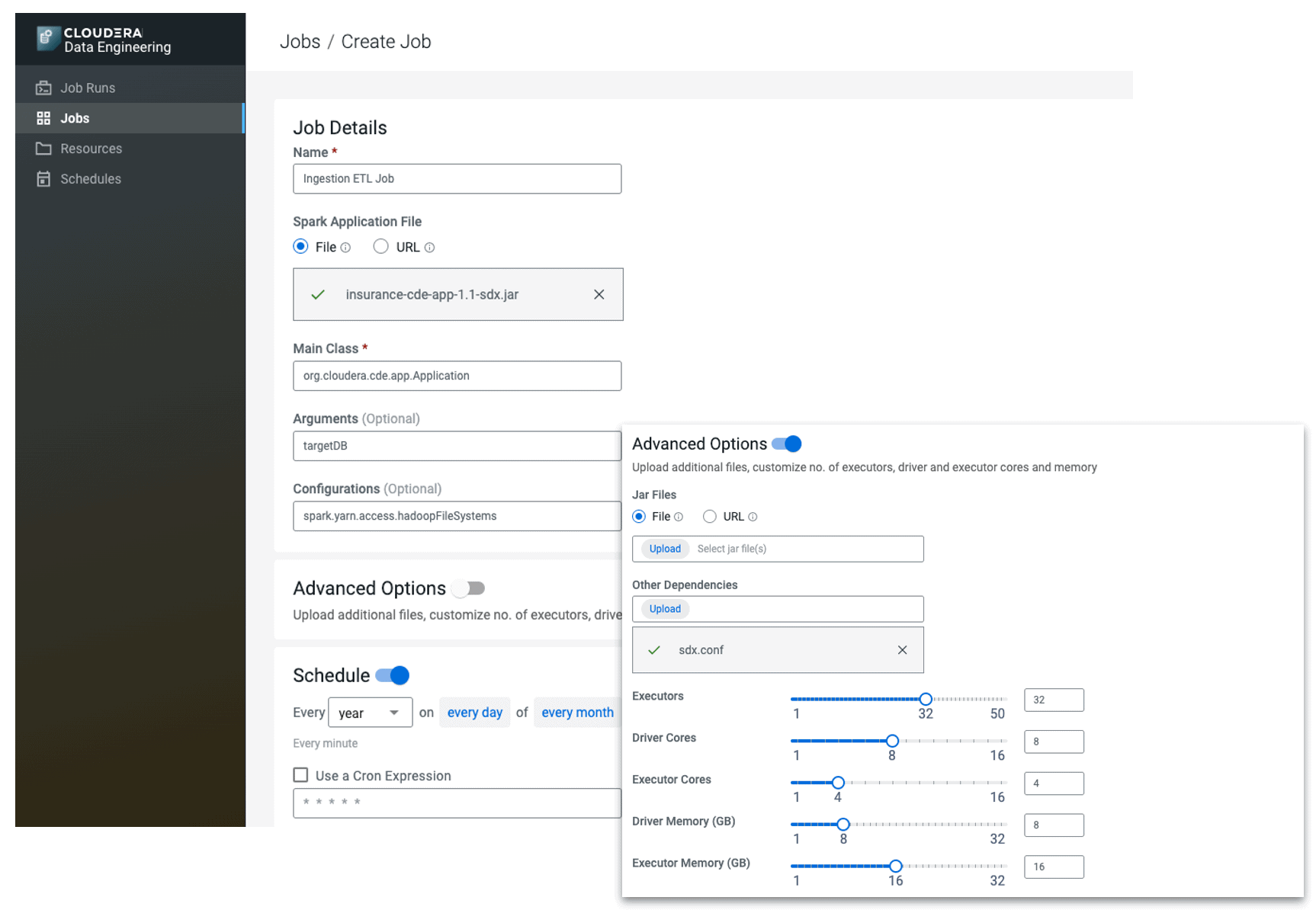
Figure 3: Job creation wizard within DE
Users can upload their dependencies; these can be other jars, configuration files or python egg files. These are managed as a single entity called a “resource”, that behind the scenes has proper versioning to ensure wherever the job is run, the correct dependencies are available. Resources are automatically mounted and available to all Spark executors alleviating the manual work of copying files on all the nodes.
Flexible Orchestration Backed by Apache Airflow
With DE we are introducing a completely new orchestration service backed by Apache Airflow — the preferred tooling for modern data engineering. Airflow allows defining pipelines using python code that are represented as entities called DAGs. DE automatically takes care of generating the Airflow python configuration using the custom DE operator.
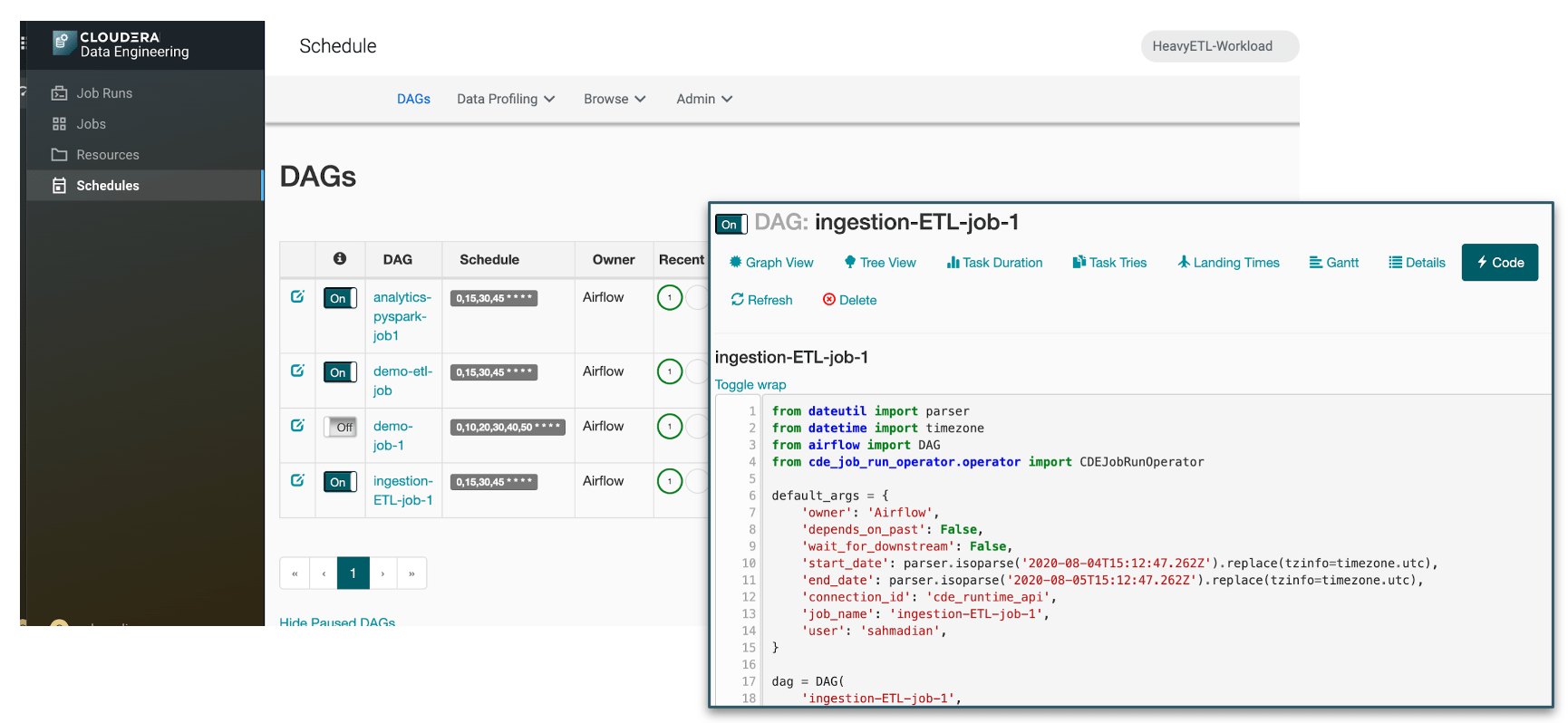
Figure 4: Auto-generated pipelines (DAGs) as they appear within the embedded Apache Airflow UI. Each DAG is defined using python code.
By leveraging Airflow, data engineers can use many of the hundreds of community contributed operators to define their own pipeline. This will allow defining of custom DAGs and scheduling of jobs based on certain event triggers like an input file showing up in an S3 bucket. This is what makes Airflow so powerful and flexible, and why we are excited to incorporate it into the Cloudera Data Platform for the very first time.
Automation APIs
A key aspect of ETL or ELT pipelines is automation. We built DE with an API centric approach to streamline data pipeline automation to any analytic workflow downstream. All the job management features available in the UI uses a consistent set of APIs that are accessible through a CLI and REST allowing for seamless integration with existing CI/CD workflows and 3rd party tools.
Some of the key entities exposed by the API:
- Jobs are the definition of something that DE can run. For example, the information required to run a jar file on Spark with specific configurations.
- A job run is an execution of a job. For example, one run of a Spark job on a DE virtual cluster.
- A resource is a directory of files that can be uploaded to DE and then referenced by jobs. This is typically for application (e.g. .jar, .py files) and reference files, and not the data that the job run will operate on.
For example, Jenkin builds of Spark jobs can be set up to deploy jobs on DE using the API. And if you have a local development environment running jobs via Spark-submit, it’s very easy to transition to the DE CLI to start managing Spark jobs, and avoiding the usual headaches of copying files to edge or gateway nodes or terminal access. With the CLI, creation and submission of jobs are fully secure, and all the job artifacts and configurations are versioned making it easy to track and revert changes.
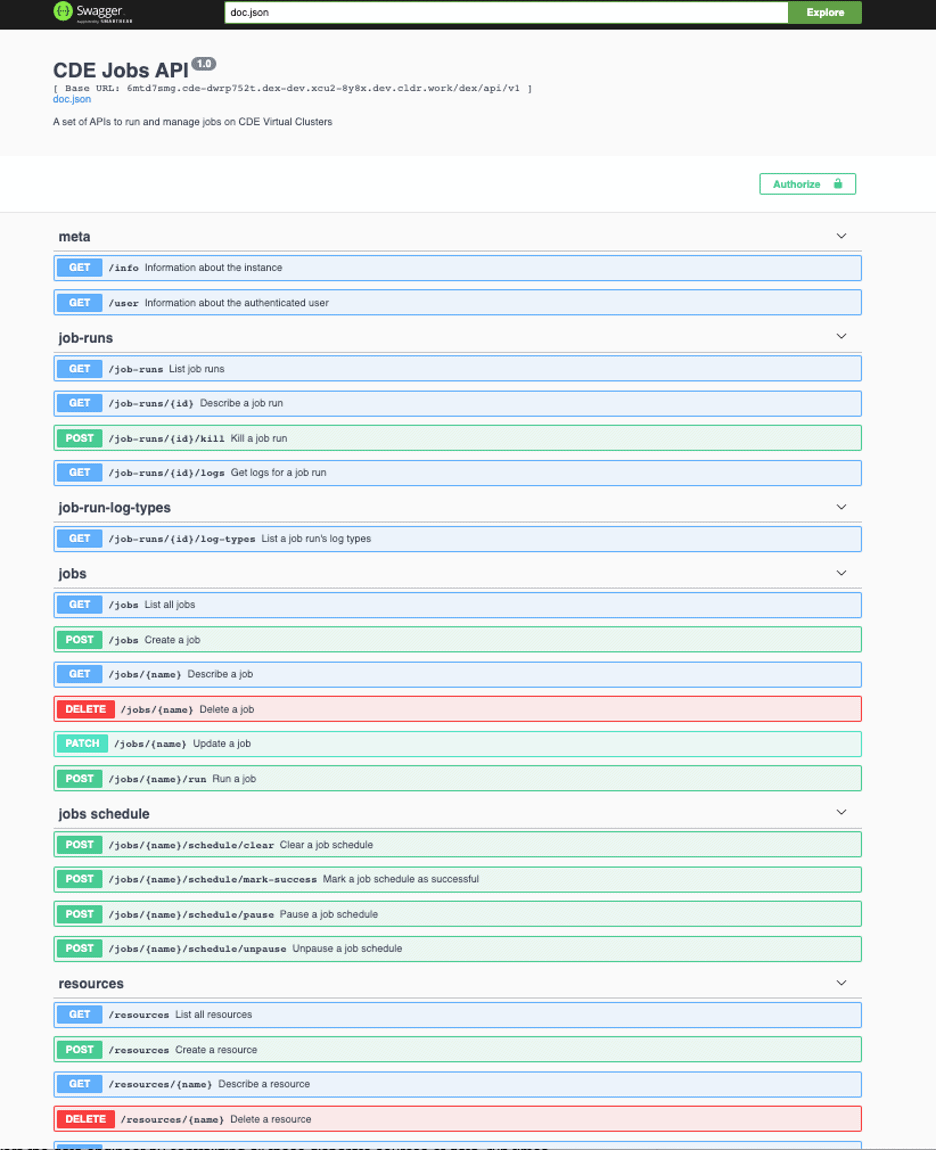
Figure 5: Automation APIs available through REST and CLI, that also back the management UI
A Single Pane of Glass For Everything Data Engineers Do
Ask any data engineering practitioner and operationalizing their data pipelines is one of the most challenging tasks they face on a regular basis — primarily because of the lack of visibility and disparate tools. Whether it’s managing job artifacts and versions, monitoring run times, having to rely on IT admins when something goes wrong to collect logs, or manually sifting through 1000s of lines of logs to identify errors and bottlenecks; true self-service is usually out of reach.
DE empowers the data engineer by centralizing all these disparate sources of data — run times, logs, configurations, performance metrics — to provide a single pane of glass and operationalize their data pipeline at scale.
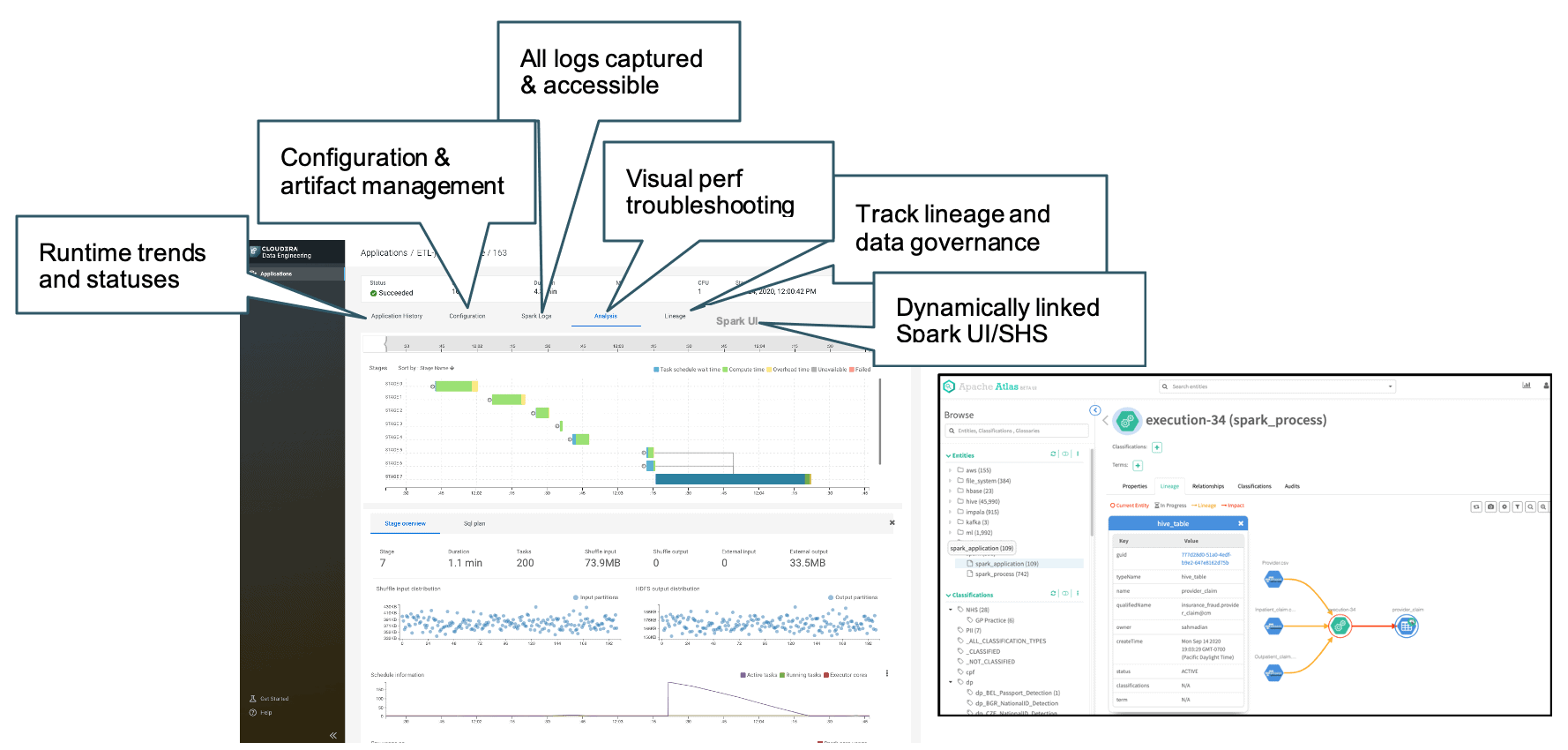
Figure 6: (left) DE’s central interface to manage jobs along with (right) the auto generated lineage within Atlas
Self-service visual profiling and troubleshooting
As good as the classic Spark UI has been, it unfortunately falls short. For starters it lacks metrics around cpu, memory utilization that are easily correlated across the lifetime of the job. That’s why we are excited to provide a new visual profiling and tuning interface that’s self-service and codifies the best practices and deep experience we have gained after years of debugging and optimizing Spark jobs.
As each Spark job runs, DE has the ability to collect metrics from each executor and aggregate the metrics to synthesize the execution as a timeline of the entire Spark job in the form of a Gantt chart, each stage is a horizontal bar with the widths representing time spent in that stage. Any errors during execution are also highlighted to the user with tooltips for additional context regarding the error and any actions that the user might need to take.
To understand utilization and identify bottlenecks, the stage timeline is correlated with CPU, Memory, and IO. This allows the data engineer to spot memory pressure or underutilization due to overprovisioning and wasting resources.
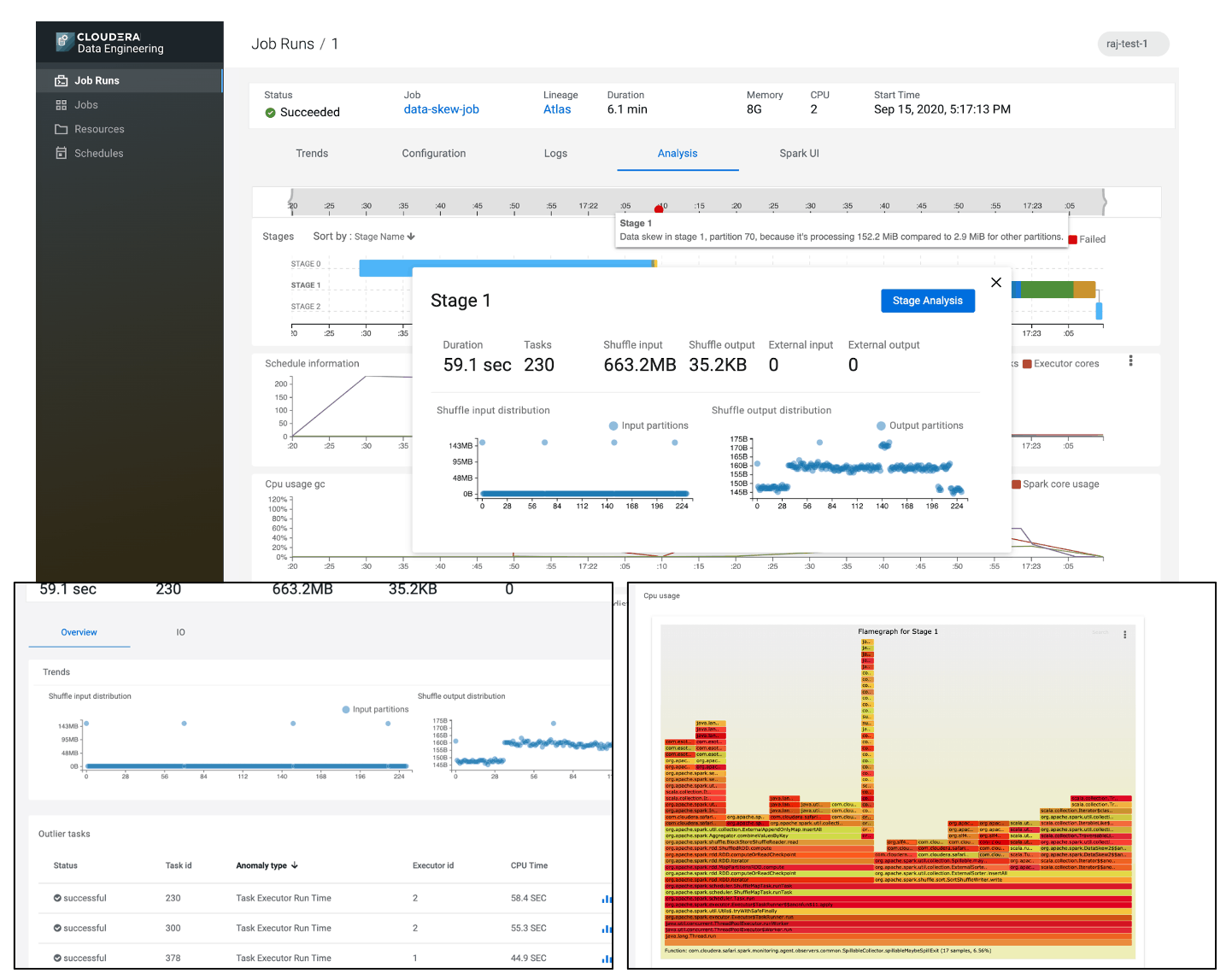
Figure 7: (top) Stage level drill down, with additional statistics around # of Tasks, total input/output and distribution skew (bottom) Task outliers in terms of duration and i/o, along with CPU flamegraphs depicting for a specific task/stage where the majority of the time was spent in particular parts of the code.
For further analysis, stage level summary statistics show the number of parallel tasks and I/O distribution. And based on the statistical distribution, the post-run profiling can detect outliers and present that back to the user. The stage details page provides information related to these outlier tasks along CPU duration and I/O. In addition, CPU flame graphs visualize the parts of the code that are taking the most time.
Finding bottlenecks and the proverbial “needle in the haystack” are made easy with just a few clicks. This level of visibility is a game changer for data engineering users to self-service troubleshoot the performance of their jobs.
Platform Resource Management & Isolation
For platform administrators, DE simplifies the provisioning and monitoring of workloads. As opposed to traditional fixed sized, on-prem clusters, virtual clusters within DE are autoscaling compute resources, increasing & decreasing capacity on-demand.
This is made possible by running Spark on Kubernetes which provides isolation from security and resource perspective while still leveraging the common storage layer provided by SDX. This is the power of CDP delivering curated, containerized experiences that are portable across multi-cloud and hybrid.
When a new business request comes for a new project, the admin can bring up a containerized virtual cluster within a matter of minutes. The admin defines resource guard rails along CPU and Memory to bound run away workloads and control costs — no more procuring new hardware or managing complex YARN policies.
The admin overview page provides a snapshot of all the workloads across multi-cloud environments. And the graphs indicate the scaling up and down of compute capacity in response to the execution of Spark jobs, highlighting payment charges only for what is used.
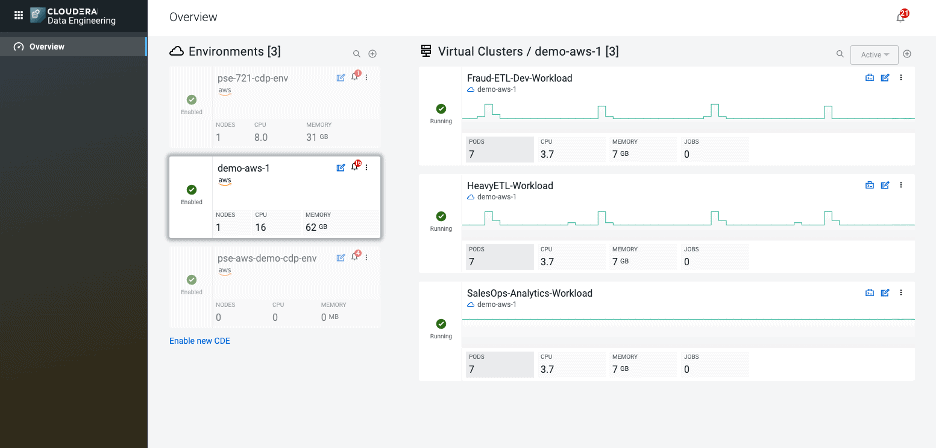
Figure 8: Cloudera Data Engineering admin overview page
Building The Future Of Enterprise Data Engineering
With this release of CDP Data Engineering we’re excited to usher in a new era of optimized workflows designed for the full data lifecycle. DE delivers a best-in-class managed Apache Spark service on Kubernetes and includes key productivity enhancing capabilities typically not available with basic data engineering services. As we continue to expand and optimize CDP to be the best possible Enterprise Data Platform for your business, stay tuned for more exciting news and announcements.
Learn more about Data Engineering in the CDP Data Engineering eBook.
Editor's Choice


Thanks! I tried to search some information on different sources what a data Engineers really works, but I have never got enough and real information, like what you posted above. Thanks!