

Recently, we announced enhanced multi-function analytics support in Cloudera Data Platform (CDP) with Apache Iceberg. Iceberg is a high-performance open table format for huge analytic data sets. It allows multiple data processing engines, such as Flink, NiFi, Spark, Hive, and Impala to access and analyze data in simple, familiar SQL tables.
In this blog post, we are going to share with you how Cloudera Stream Processing (CSP) is integrated with Apache Iceberg and how you can use the SQL Stream Builder (SSB) interface in CSP to create stateful stream processing jobs using SQL. This enables you to maximize utilization of streaming data at scale. We will explore how to create catalogs and tables and show examples of how to write and read data from these Iceberg tables. Currently, Iceberg support in CSP is in technical preview mode.
The CSP engine is powered by Apache Flink, which is the best-in-class processing engine for stateful streaming pipelines. Let’s take a look at what features are supported from the Iceberg specification:
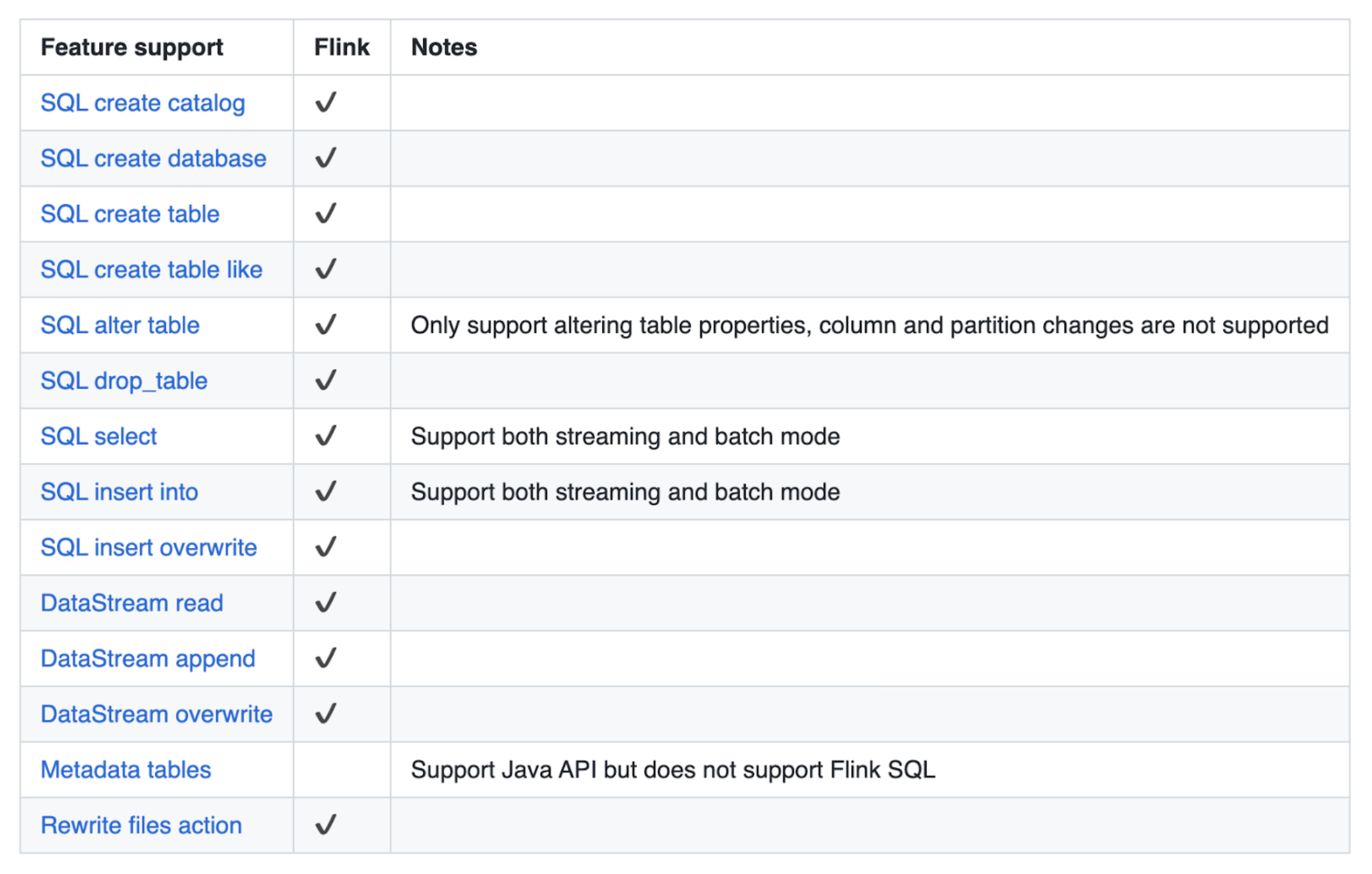
As shown in the table above, Flink supports a wide range of features with the following limitations:
- No DDL support for hidden partitioning
- Altering a table is only possible for table properties (no schema/partition evolution)
- Flink SQL does not support inspecting metadata tables
- No watermark support
CSP currently supports the v1 format features but v2 format support is coming soon.
SQL Stream Builder integration
Hive Metastore
To use the Hive Metastore with Iceberg in SSB, the first step is to register a Hive catalog, which we can do using the UI:
In the Project Explorer open the Data Sources folder and right-click on Catalog, which will bring up the context menu.
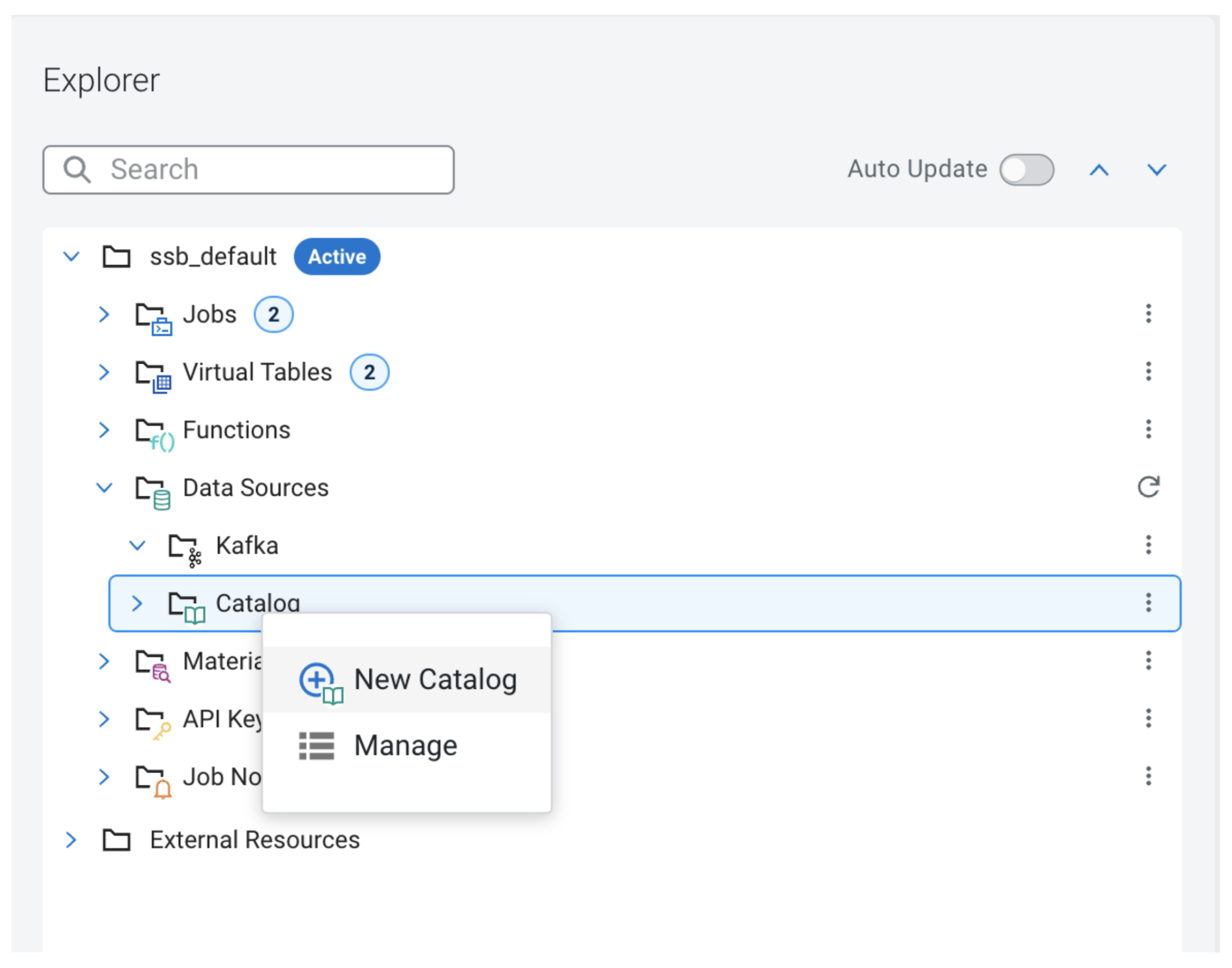
Clicking “New Catalog” will open up the catalog creation modal window.
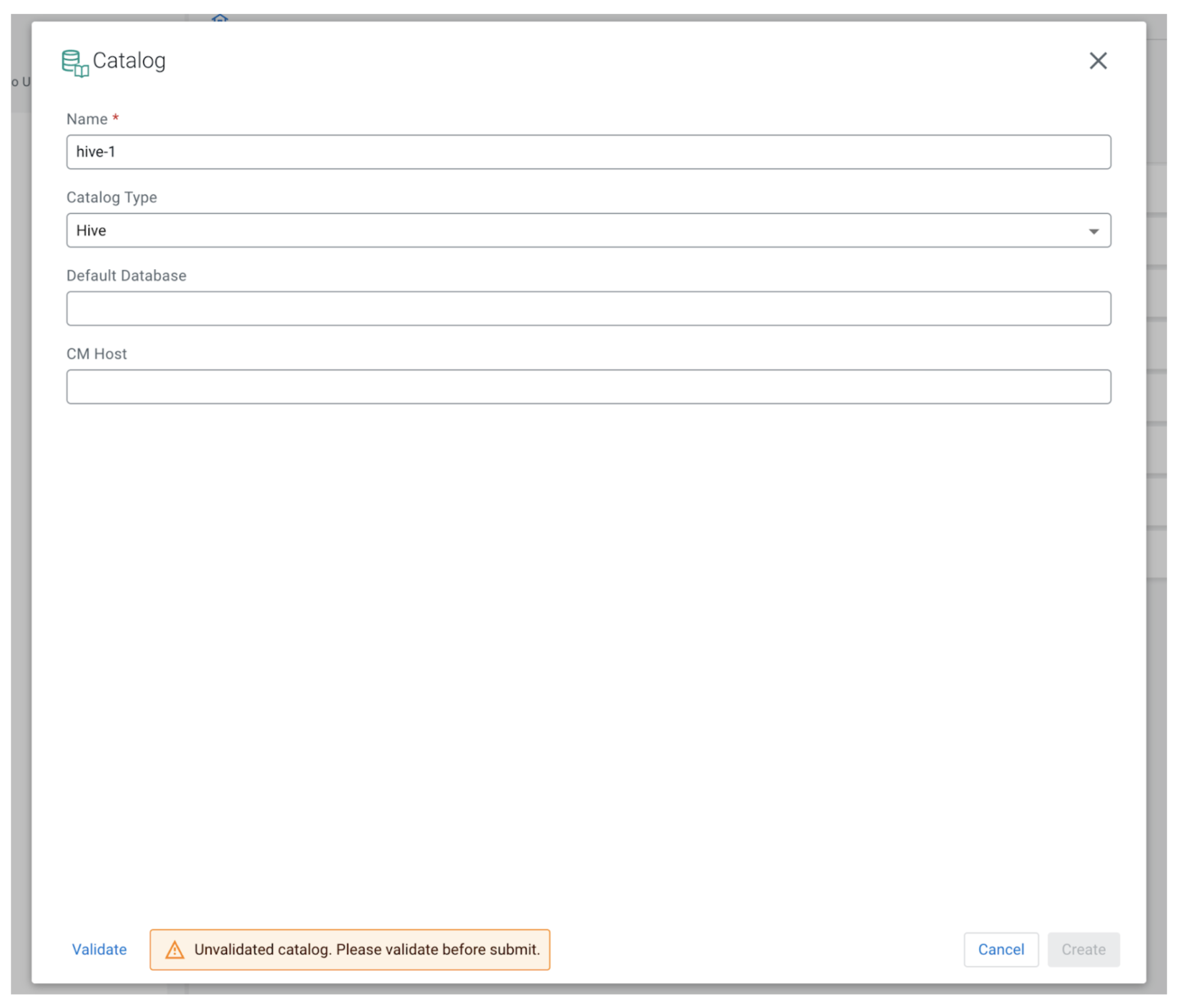
To register a Hive catalog we can enter any unique name for the catalog in SSB. The Catalog Type should be set to Hive. The Default Database is an optional field so we can leave it empty for now.
The CM Host field is only available in the CDP Public Cloud version of SSB because the streaming analytics cluster templates do not include Hive, so in order to work with Hive we will need another cluster in the same environment, which uses a template that has the Hive component. To provide the CM host we can copy the FQDN of the node where Cloudera Manager is running. This information can be obtained from the Cloudera Management Console by first selecting the Data Hub cluster that has Hive installed and belongs to the same environment. Next, go to the Nodes tab:

Look for the node marked “CM Server” on the right side of the table. After the form is filled out, click Validate and then the Create button to register the new catalog.
In the next example, we will explore how to create a table using the Iceberg connector and Hive Metastore.
Let’s create our new table:
CREATE TABLE `ssb`.`ssb_default`.`iceberg_hive_example` ( `column_int` INT, `column_str` VARCHAR(2147483647) ) WITH ( 'connector' = 'iceberg', 'catalog-database' = 'default', 'catalog-type' = 'hive', 'catalog-name' = 'hive-catalog', 'ssb-hive-catalog' = 'your-hive-data-source', 'engine.hive.enabled' = 'true' )
As we can see in the code snippet, SSB provides a custom convenience property ssb-hive-catalog to simplify configuring Hive. Without this property, we would need to know the hive-conf location on the server or the thrift URI and warehouse path. The value of this property should be the name of the previously registered Hive catalog. By providing this option, SSB will automatically configure all the required Hive-specific properties, and if it’s an external cluster in case of CDP Public Cloud it will also download the Hive configuration files from the other cluster. The catalog-database property defines the Iceberg database name in the backend catalog, which by default uses the default Flink database (“default_database”). The catalog-name is a user-specified string that is used internally by the connector when creating the underlying iceberg catalog. This option is required as the connector doesn’t provide a default value.
After the table is created we can insert and query data using familiar SQL syntax:
INSERT INTO `iceberg_hive_example` VALUES (1, 'a'); SELECT * FROM `iceberg_hive_example`;
Querying data using Time Travel:
SELECT * FROM `iceberg_hive_example` /*+OPTIONS('as-of-timestamp'='1674475871165')*/;
Or:
SELECT * FROM `iceberg_hive_example` /*+OPTIONS('snapshot-id'='901544054824878350')*/
In streaming mode, we have the following capabilities available:
We can read all the records from the current snapshot, and then read incremental data starting from that snapshot:
SELECT * FROM `iceberg_hive_example` /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/
Furthermore, we can read all incremental data starting from the provided snapshot-id (records from this snapshot will be excluded):
SELECT * FROM `iceberg_hive_example` /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
Conclusion
We have covered how to access the power of Apache Iceberg in SQL Stream Builder and its possibilities and limitations in Flink. We also explored how to create and access Iceberg tables using a Hive catalog and the convenience options in SSB to facilitate the integration, so you can spend less time on configuration and focus more on the data.
Try it out yourself!
Anybody can try out SSB using the Stream Processing Community Edition (CSP-CE). CE makes developing stream processors easy, from your desktop or any other development node. Analysts, data scientists, and developers can now evaluate new features, develop SQL-based stream processors locally using SQL Stream Builder powered by Flink, and develop Kafka Consumers/Producers and Kafka Connect Connectors, all locally before moving to production in CDP.
Editor's Choice

