

SQL Stream Builder (SSB) is a versatile platform for data analytics using SQL as a part of Cloudera Streaming Analytics, built on top of Apache Flink. It enables users to easily write, run, and manage real-time continuous SQL queries on stream data and a smooth user experience.
Though SQL is a mature and well understood language for querying data, it is inherently a typed language. There is a certain level of consistency expected so that SQL can be leveraged effectively. As an essential part of ETL, as data is being consolidated, we will notice that data from different sources are structured in different formats. It might be required to enhance, sanitize, and prepare data so that data is fit for consumption by the SQL engine. Data transformations in SSB gives us the ability to do exactly that.
What is a data transformation?
Data transformation in SSB makes it possible to mutate stream data “on the wire” as it is being consumed into a query engine. This transformation can be performed on incoming records of a Kafka topic before SSB sees the data.
A few use cases when transformations can be a powerful tool:
- If the data being collected has sensitive fields that we choose not to expose to SSB.
- If the Kafka topic has CSV data that we want to add keys and types to it.
- If the data is in valid JSON format, but has non Avro compatible field names, has no uniform keys, etc.
- If the messages are inconsistent.
- If the schema you want does not match the incoming Kafka topic.
Similar to UDFs, data transformations are by default written in JavaScript. The one requirement that we do have is that after the data transformation is completed, it needs to emit JSON. data transformations can be defined using the Kafka Table Wizard.
The use case
The data we are using here is security log data, collected from honeypots: invalid authentication attempts to honeypot machines that are logged and published to a Kafa data source.
Here is an excerpt of the log entries in JSON that is streamed to Kafka:
{"host":"honeypot-fra-1","@version":"1","message":"Sep 11 19:01:27 honeypot-fra-1 sshd[863]: Disconnected from invalid user user 45.61.184.204 port 34762 [preauth]","@timestamp":"2022-09-11T19:01:28.158Z","path":"/var/log/auth.log"} {"@timestamp":"2022-09-11T19:03:38.438Z","@version":"1","message":"Sep 11 19:03:38 honeypot-sgp-1 sshd[6605]: Invalid user taza from 103.226.250.228 port 41844","path":"/var/log/auth.log","host":"honeypot-sgp-1"} {"@timestamp":"2022-09-11T19:08:30.561Z","@version":"1","message":"Sep 11 19:08:29 honeypot-sgp-1 kernel: [83799422.549396] IPTables-Dropped: IN=eth0 OUT= MAC=fa:33:c0:85:d8:df:fe:00:00:00:01:01:08:00 SRC=94.26.228.80 DST=159.89.202.188 LEN=40 TOS=0x00 PREC=0x00 TTL=240 ID=59466 PROTO=TCP SPT=48895 DPT=3389 WINDOW=1024 RES=0x00 SYN URGP=0 ","path":"/var/log/iptables.log","host":"honeypot-sgp-1"}
You probably notice a couple of non Avro compatible field names in the data, one of them being @timestamp, which contains an ISO formatted timestamp of when the security incident occurred. If you ingest this log data into SSB, for example, by automatically detecting the data’s schema by sampling messages on the Kafka stream, this field will be ignored before it gets into SSB, though they are in the raw data.
Further, if we’ve elected to use “Kafka event timestamps” as SSB row times, the timestamp that SSB records will be the time it was injected into Kafka. This might be OK for some cases. However, we will probably want to base our query on when a security incident actually happened.
We will solve this problem in three steps:
- Write a data transformation that creates a new field with an Avro compatible name in each JSON entry. We populate the field with the value in the non Avro compatible @timestamp field.
- We will change the schema of the data to include the new field that we emitted in step 1.
- We will tell SSB to use this new field, that is now part of the schema as the event timestamp.
The data transformation
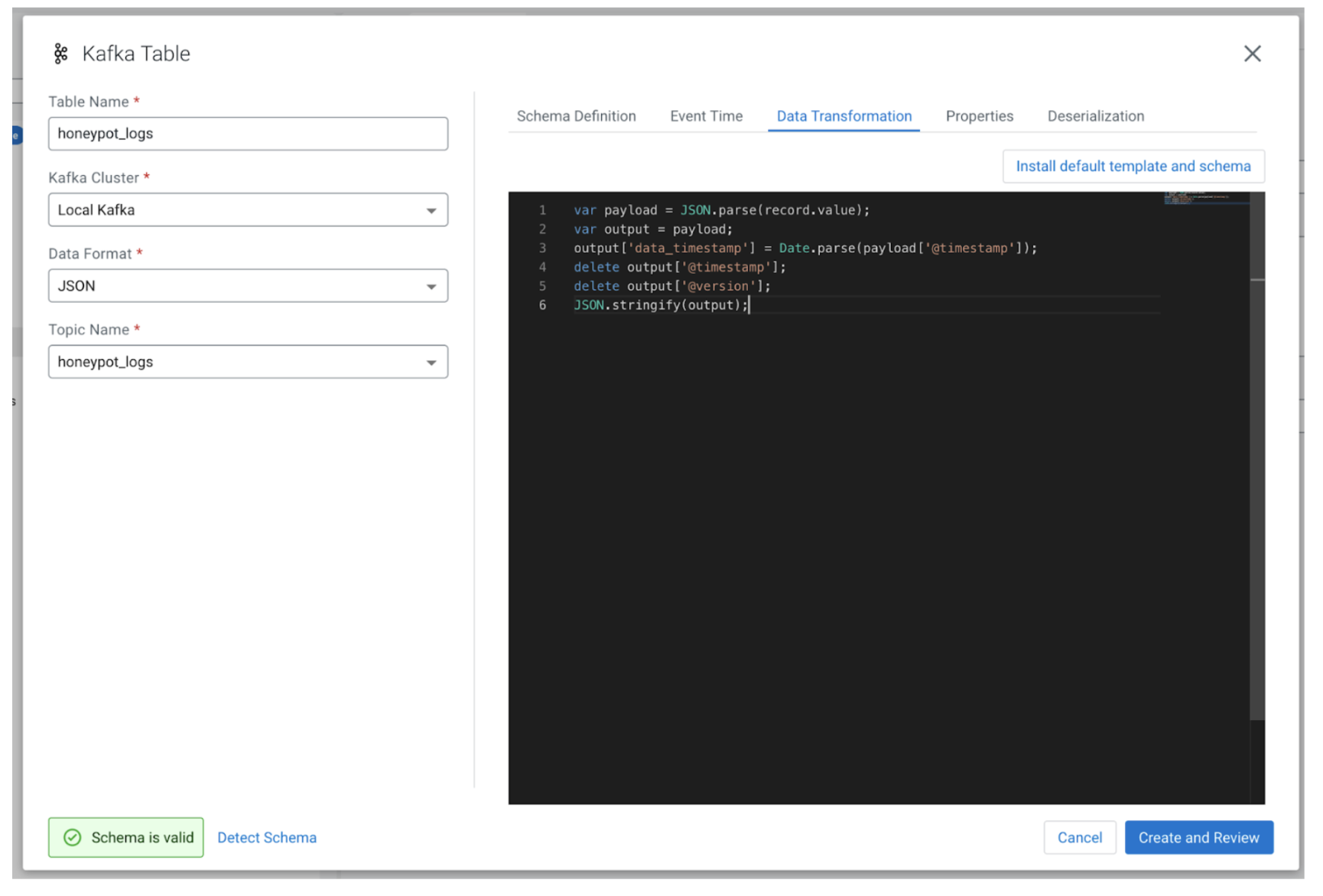
This data transformation should happen before the events are written into the SSB table. You can find “Data Transformation” as one of the tabs under the table.
At the core of the data transformation there is a “record” object that contains the payload of the log data. The data transformation is set up as a construct under the table.
We will want to create a new field called data_timestamp that is processed from the @timestamp field. We will create a local scoped variable to access the record’s payload dictionary. The timestamp field is parsed using the JavaScript Date module and added to a new key on the payload. We can, at that point, sanitize the fields that are not Avro compatible, and return it as a stringified JSON object.
var payload = JSON.parse(record.value); var output = payload; output['data_timestamp'] = Date.parse(payload['@timestamp']); delete output['@timestamp']; delete output['@version']; JSON.stringify(output);
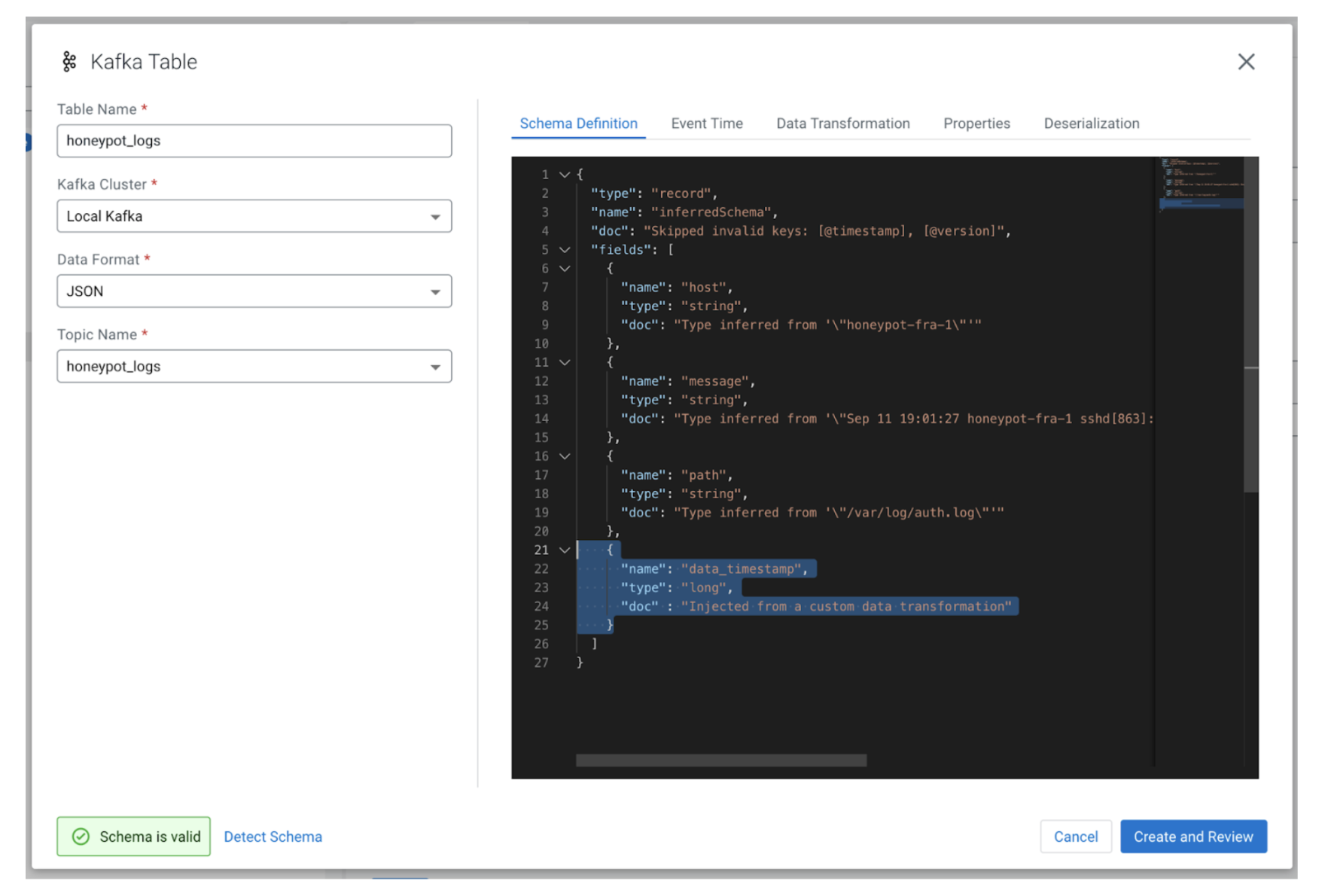
We can now add the new field data_timestamp into the schema so that it will be exposed to SQL queries. We could just add the following fragment describing the new field and its time into the schema under the “Schema Definition” tab:
{ "name" : "data_timestamp", "type": "long", "doc": "Injected from a custom data transformation" }
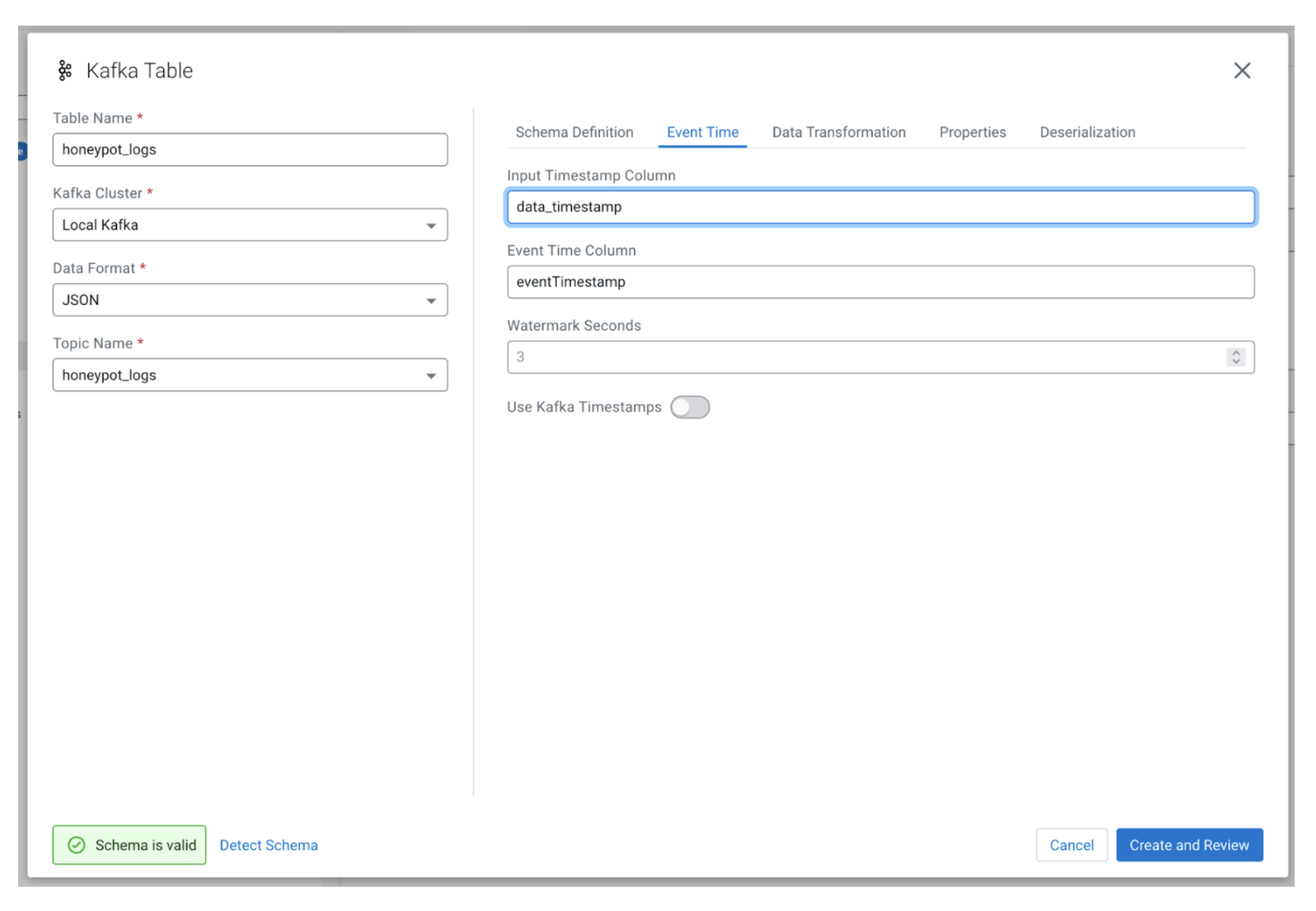
The last step is to change the Kafka row time to use the new row that we just created. That function can be found under the “Event Time” tab’s “Input Timestamp Column.”
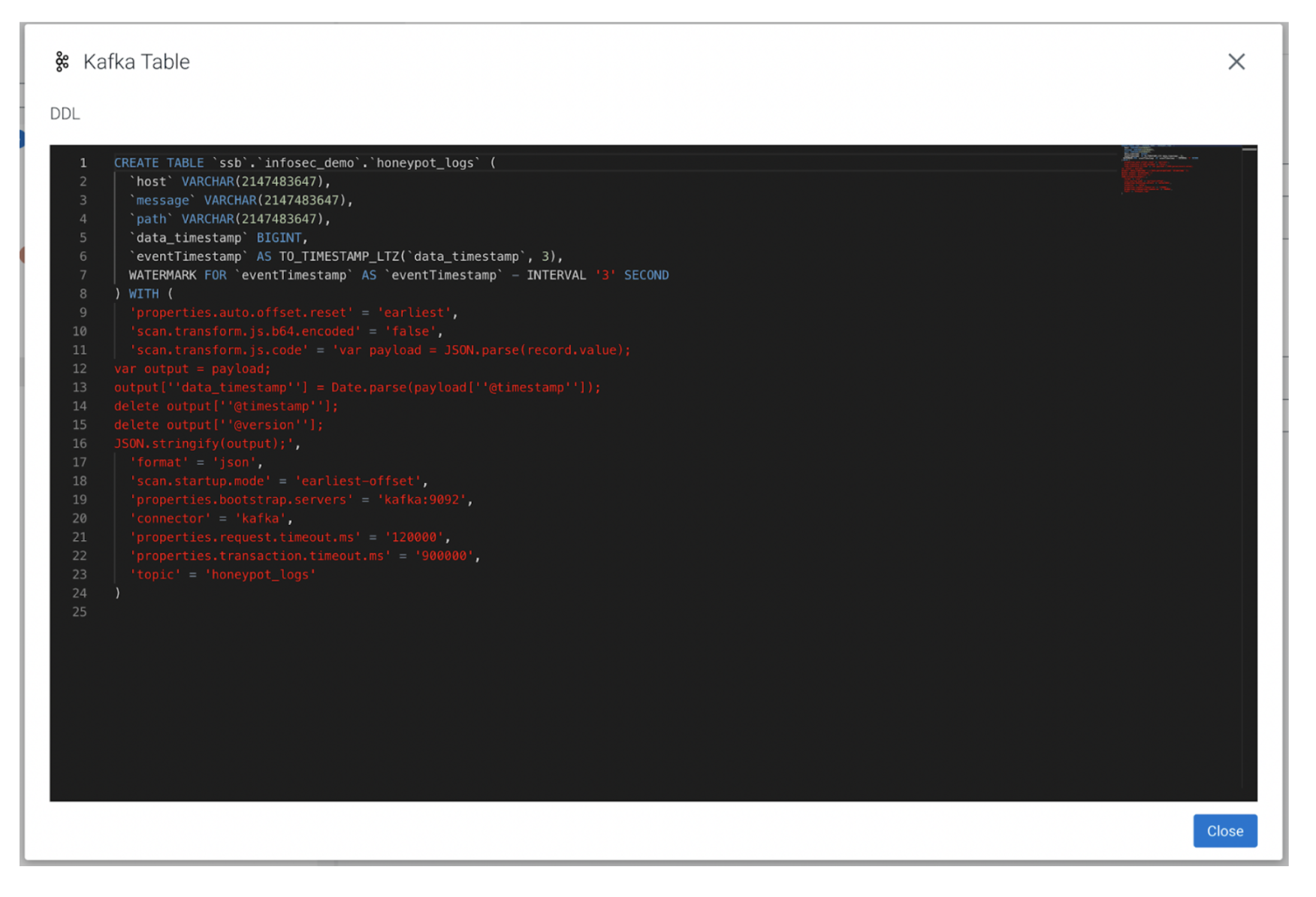
We can review the DDL changes that are going to be applied to the schema itself on “Update and Review.”
To summarize:
- A new big integer data_timestamp field is added.
- The eventTimestamp is used as the row time, formatted from the data_timestamp.
Conclusion
In this module, we have taken a deeper look at SSB’s data transformations. We looked at how to write a data transformation in JavaScript to extract a field from the payload and format it into a timestamp that can be configured as the SSB row time.
Try it out yourself!
Anybody can try out SSB using the Stream Processing Community Edition (CSP-CE). The Community Edition makes developing stream processors easy, as it can be done right from your desktop or any other development node. Analysts, data scientists, and developers can now evaluate new features, develop SQL-based stream processors locally using SQL Stream Builder powered by Flink, and develop Kafka Consumers/Producers and Kafka Connect Connectors, all locally before moving to production in CDP.
Check out the full recording of the Deploying Stateful Streaming Pipelines in Less Than 5 Minutes With CSP Community Edition.
Editor's Choice

